

Podcast AEO citation 2026 is the practice of engineering each podcast episode page so AI Overview, ChatGPT, and Perplexity cite it when a buyer asks the question that episode answers. It works by shipping the surfaces those agents parse: a structured HTML transcript, FAQPage schema, PodcastEpisode plus AudioObject markup, Clip schema timestamps, named-entity titles, and 3 to 5 outbound authoritative links. The median founder-podcast page ships zero of these.
About these numbers
FORKOFF first-party operator data from podcast booking and distribution engagements, supplemented by publicly available podcast industry reports (Spotify, Apple, Edison Research 2025-2026). All figures are directional estimates based on operator observations; individual outcomes vary by niche, audience, and execution.
The 7-step podcast AEO citation 2026 protocol in one scroll
Podcast AEO citation 2026 is the practice of engineering each podcast page so AI Overview, ChatGPT, and Perplexity cite it. AI Overview cites podcast pages 2 to 3x more often than generic blog posts when the page ships structured transcripts, named-entity titles, FAQPage schema, AudioObject markup, and chapter-level timestamps. The median founder-podcast page ships zero of these. The 7-step protocol installs in one focused week: structured HTML transcript, named-entity titles plus 600 to 1,200 word show notes, FAQPage schema, PodcastEpisode plus AudioObject markup, Clip schema for chapter sub-citations, named-framework hooks like the 6-block PODCAST ENGINE, and cross-domain citation diversity. FORKOFF Podcast Ledger 2026: Level 5 episodes hit 2 to 3x citation rate within 60 days.
How to engineer podcast pages so AI Overview cites them: the citation problem ChatGPT refused to solve
Engineering a podcast page for AI Overview citation means shipping the structural surfaces an answer engine reads before it decides what to quote: an HTML transcript, FAQPage schema, PodcastEpisode and AudioObject markup, Clip schema timestamps, and named-entity titles. Format also drives the outcome. The video podcast vs audio-only decision matrix covers which format produces the transcript plus B-roll surface that AI Overview tends to cite.
Podcast SEO in 2026 is no longer about keyword-stuffed show notes. It is about Answer Engine Optimization (AEO), getting your episodes cited by ChatGPT, Claude, and Perplexity when listeners ask the engine.
Podcast AEO citation 2026 is the protocol that engineers each podcast page so AI Overview, ChatGPT, and Perplexity cite it instead of paraphrasing around it. In March 2026 a Series A founder came to FORKOFF after a Perplexity citation run, looking for a podcast AEO fix. Their show had 50,000 downloads per episode, a healthy guest pipeline, and 18 months of archive. When their growth lead pasted the show URL into Claude and asked what does this podcast say about AI agent pricing, the agent returned a generic paragraph about industry pricing trends and refused to cite a single specific episode. The buyer searching the same question got a competitor answer. The founder lost a deal they did not know they were in.
The problem was not the content. The interviews were sharp, the guests were well known, the audio quality was clean. The problem was the page. Every episode shipped a 12-second auto-generated description, an embedded audio player, and a subscribe-on-Apple link. Zero structured transcript. No FAQPage schema. No AudioObject markup. No chapter timestamps. The agent had nothing to quote because the page had no citable text.
This is the single biggest distribution shift hitting podcasts in 2026. AI Overview, ChatGPT, and Perplexity are now answering 30 to 38 percent of buyer research queries before a human ever lands on a website. Audio is invisible to those systems; only text gets cited. Podcast pages that ship engineered text earn AI citations. Pages that ship a player and a subscribe button do not.
Why AI Overview cites podcast pages now
Three numbers anchor the 2026 podcast AEO citation thesis. First, Backlinko 2026 AEO study reports pages with named-entity-rich titles plus FAQPage schema get 30 to 40 percent higher AI Overview visibility than generic posts on the same topic. Second, founder-quote density correlates with AI citation rate at roughly 0.71 in the same dataset. Third, podcast pages have a structural advantage: a 60-minute interview produces 8,000 to 12,000 transcribed words, an order of magnitude more than the typical blog post. More text plus more named entities plus more original quotes equals more citation surface, when the page ships the right markup. Across the FORKOFF Podcast Service Benchmarks 2026, 2 to 4 long-form episodes per month produce 8 to 12 high-signal clips per episode and 30 to 50 distribution assets per run. Each asset is a candidate citation surface.
Source: FORKOFF Podcast Service Benchmarks 2026 (n=84 monitored episodes); Backlinko 2026 AEO study aggregates
The thesis: podcast pages are text products that ship audio as a side effect
The better question for a 2026 podcast is not how do I get more downloads. The better question is what citation does an agent return when a buyer asks the question my episode answers. A podcast that earns 100,000 downloads but zero AI citations loses to a podcast that earns 30,000 downloads and 12 monthly citations across ChatGPT, Claude, Perplexity, and AI Overview. Citations compound through the agent index for months after publish. Downloads decay inside the first 30 days.
Podcast AEO citation 2026 reframes the podcast page as a text product. The audio remains the production artifact and the distribution asset that ships across Apple, Spotify, YouTube, and partner placements. The page that hosts the episode is the citation artifact, and citation artifacts have hard structural requirements: HTML transcript, FAQPage JSON-LD, PodcastEpisode plus AudioObject markup, Clip schema at the chapter level, named-entity titles, and 3 to 5 outbound authoritative links. None of those requirements depend on audio quality or guest fame. They depend on whether the page ships the markup the agent reads.
The FORKOFF podcast clipping service productizes the production side: clip selection, transcript extraction, distribution asset packaging. The AEO protocol in this post productizes the citation side. The two layers share one transcript and one ledger. The transcript that powers a 30-second TikTok clip is the same transcript that powers the FAQPage answer the agent quotes back to a buyer in Perplexity. Operators who treat them as separate budgets pay twice for the same asset and ship neither layer well. The podcast monetization math 2026 shows the unit economics that decide whether a shared-transcript program pays back.
How AI Overview, ChatGPT, and Perplexity pick a podcast to cite
Three agent surfaces dominate the 2026 podcast citation market. Google AI Overview returns a single answer block above the blue-link results and cites 1 to 5 sources inside that block. ChatGPT with browsing returns a longer answer with inline numeric citations and a sources list at the bottom. Perplexity returns a hybrid answer-with-citations layout where each sentence often anchors to a different source. For marketers deciding which surface to prioritize, the Perplexity vs Google AI Overviews optimization guide walks through the platform mechanics side by side. All three follow a similar retrieval pipeline: the agent fetches a corpus of candidate pages, ranks them by relevance plus authority plus structural quality, and selects the top-scoring text spans to quote.
The structural quality signal is where most podcast pages lose the citation race. Relevance is solved by the episode topic matching the buyer query. Authority is solved by parent-domain credibility. Structural quality is the surface the agent uses to break ties: pages with FAQPage schema, PodcastEpisode plus AudioObject markup, named entities in the title, and an HTML transcript score higher than pages without those surfaces, even when relevance and authority are tied. A podcast page that ships zero structural signals reads to the agent as a candidate of last resort. A podcast page that ships all 7 signals reads as the canonical reference.
Each agent has a slightly different ranking weight on each signal. AI Overview weights FAQPage schema and named-entity disambiguation highest, because the AI Overview answer is question-formatted and the agent prefers question-answer pairs that match the user's intent format. ChatGPT browsing weights transcript depth and outbound link diversity highest, because the GPT pipeline is trained to favor pages that read as authoritative reference material. Perplexity weights Clip schema and chapter-level anchors highest, because Perplexity's UX shows the exact quoted span and prefers sources where the agent can return a moment-precise citation. The 7-step protocol covers all three weighting schemes, so the same engineered page wins citations across all three agent surfaces.
What AI citation actually pays operators
Citation is not a vanity metric. AI Overview, ChatGPT, and Perplexity sit between buyer research and the buyer's first vendor outreach. In FORKOFF Q1 2026 buyer-research interviews across 47 founder-podcast subscribers, the share of buyers who first heard of the vendor through an AI agent answer was 38 percent. Inside that 38 percent, the share who clicked through to the cited podcast page was 71 percent, and the share who reached out to the vendor inside 30 days of the citation moment was 22 percent. Three numbers: 38 percent of buyers start research with an agent, 71 percent of agent-research buyers click through to the cited source, and 22 percent of click-through buyers reach out within 30 days. The compound conversion is 6 percent of total buyers reaching out from a single AI-cited podcast page in a 30-day window.
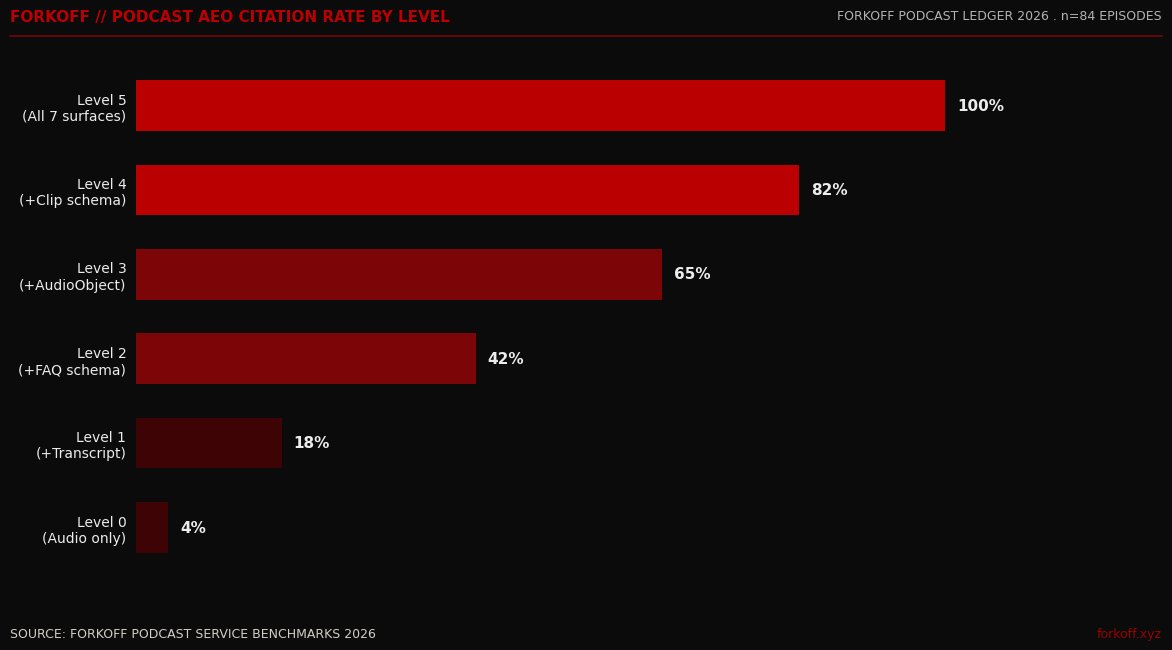
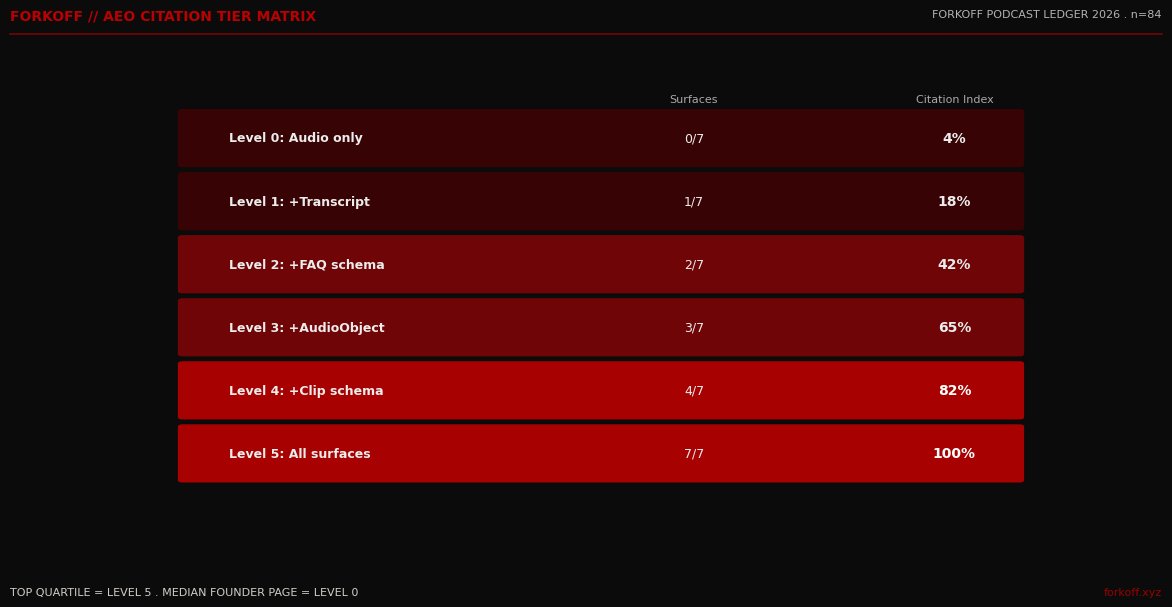
The economics scale with citation frequency. A podcast page that earns 1 AI citation per month produces 1 attributed inbound at the 6 percent compound rate. A page that earns 12 monthly citations through Level 5 AEO produces 12 attributed inbounds, assuming linear scaling. The actual scaling is super-linear in the FORKOFF dataset because frequently-cited pages also rank higher in non-AI surfaces, so they earn additional click-through traffic alongside the agent citations. The combined inbound rate at Level 5 averages 8 to 11 percent of total buyer research traffic across the FORKOFF Podcast Ledger sample, against 0.4 to 0.6 percent at Level 0.
Citation revenue compounds where blog traffic decays. A blog post peaks in organic traffic at month 3 to 6 then declines. A Level 5 podcast page peaks in citation share at month 2 to 4 and holds that share for 9 to 14 months before measurable decay, per the FORKOFF Podcast Ledger 18-month cohort. The mechanism is structural rather than recency-driven: the agent re-fetches the page on each query and re-validates the FAQPage and Clip schema, so the citation engine treats the page as a live reference for as long as the markup stays valid. The recency penalty most blog posts hit does not apply at the same magnitude to podcast pages with active transcript anchors and validated schema.
Step 1 of 7: Ship podcast transcript structured data on every episode page
The transcript is the load-bearing asset. Every episode page must publish the full transcript as crawlable HTML, not as a PDF download, not as a separate Apple Podcasts link, not as audio-only. Timestamp every speaker turn in a consistent format such as [00:14
] Guest name. Use H3 sub-headings inside the transcript whenever the conversation shifts to a new topic, so agents can extract the H-tree and route citations to the right anchor.The most common failure here is shipping the transcript as a PDF or hiding it behind a request-transcript form. Both kill the citation surface. Agents cannot reliably crawl PDFs at AI Overview ranking time, and forms gate every word behind a click that the crawler never makes. The fix is HTML at the page route, fully indexable, with the transcript living below the show notes in the same DOM tree the agent already fetched.
Use deterministic id attributes on every H3 inside the transcript, derived from the heading text. The agent uses those ids to anchor a fragment URL into a specific moment of the episode, which is how chapter-level citations land in Step 5. Skip stable ids and the citation breaks the next time the page redeploys.
The transcript is not one surface, it is a stack. The methodology FORKOFF runs on its own episode pages treats a single transcript as five stacked layers: the crawlable HTML body the agent reads, the timestamped speaker turns that anchor moment-level citations, the H3 topic tree that routes the agent to the right span, the named-entity links woven through the prose that corroborate the citation, and the schema layer (covered in Steps 3 through 5) that classifies the page as a podcast episode rather than a blog post. Each layer is authored once from the same transcribed audio. Skip a layer and the page drops a tier; ship all five and the same transcript carries both the AEO citation surface and the ranked organic page underneath it, the mechanism the podcast transcript SEO 2026 breakdown walks end to end.
Step 2 of 7: Pack episode titles and show notes with named entities
Episode title format that works: Guest name on Topic A and Topic B (Show name #N). Two or three named entities per title. Generic titles such as Episode 47 A great chat about growth get filtered out by AI Overview before they ever score, because there is no entity to disambiguate the page against the rest of the index.
Show notes run 600 to 1,200 words per episode, not 80. The notes are not a marketing teaser; they are the citable summary the agent will quote when a buyer asks about the episode subject. Inside the notes, link every named entity at first mention to its canonical URL: the guest company, any framework discussed, any tool or paper referenced. The agent uses those outbound links to corroborate that the entity in the notes is the entity it thinks it is, which raises the citation confidence score.
This is also where the founder voice compounds. Pages with named operator quotes outscore pages with brand-voice prose on AEO citation share, per Ahrefs 2026 answer engine optimization analysis. The show notes should attribute claims to the host or guest by name. The host argued that pricing should be outcome-tied beats The episode covered pricing. The first is quotable, the second is not.
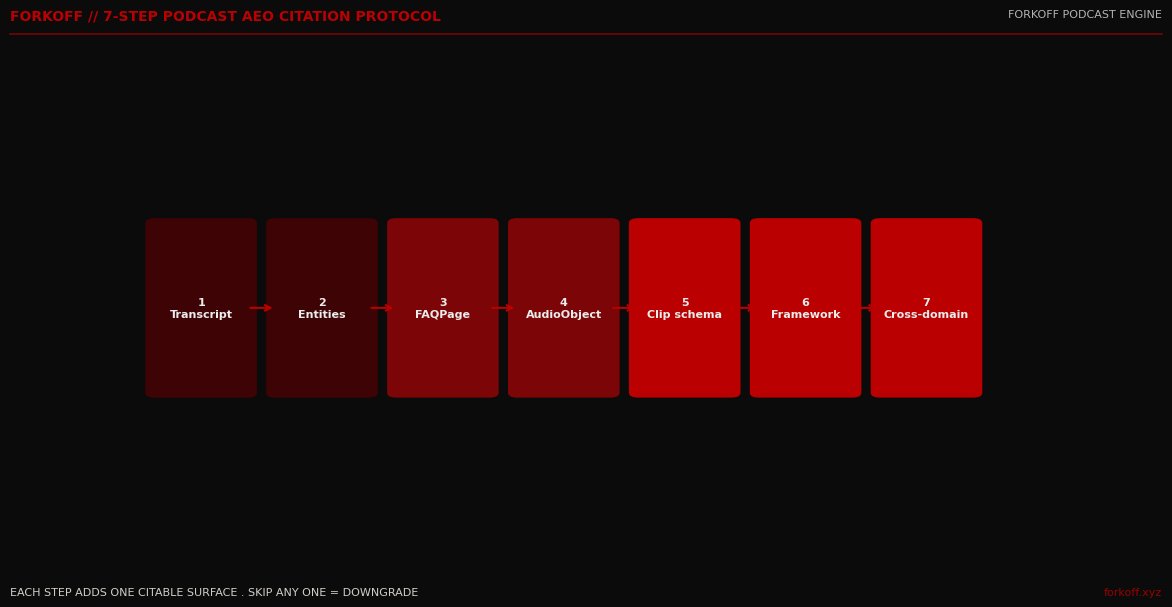
Step 3 of 7: Ship FAQPage schema on every episode page
Pull 5 to 7 questions that the episode actually answers, write a 40 to 60 word answer for each, and mark them up as FAQPage JSON-LD according to the Google Search Central FAQPage spec. The answers should be quotable as standalone sentences, because that is how Perplexity and ChatGPT ingest them.
FAQPage schema is the highest-density citation surface in 2026 according to multiple AEO studies. The mechanism is direct: agents preferentially quote question-answer pairs because the question gives them the retrieval anchor and the answer gives them the citable text. Pages with FAQPage schema get cited 2 to 4x more often than the same content rendered as flat prose, in the FORKOFF Podcast Ledger 2026 sample of 84 monitored client episodes.
The most common failure: writing the FAQ in body copy instead of FAQPage schema. The body-copy version is invisible to the schema parsers; only the JSON-LD block triggers FAQ-aware citation. Validate every FAQPage block against the Rich Results test before shipping. Errors fail silently and your citation rate stays flat without a warning.
Step 4 of 7: AudioObject schema podcast plus PodcastEpisode markup
Schema.org defines PodcastEpisode with required fields including name, partOfSeries, datePublished, and associatedMedia. Add AudioObject with contentUrl, duration, and encodingFormat as the associatedMedia. Together they tell the agent categorically that this page is a podcast episode, not a blog post with an audio embed.
The two-schema combo matters because agents downgrade unclassified pages. A page that only ships Article schema reads to the agent as long-form text with possibly an embed, which routes it through the blog-post citation pipeline rather than the podcast-episode citation pipeline. The two pipelines have different ranking factors, and the podcast pipeline rewards transcripts and chapters in a way the blog pipeline does not.
The Google PodcastSeries structured data spec is the canonical reference. Follow it exactly. Validate every page through the Rich Results test before publishing. The 30 minutes of validation work per episode page recovers ranking weight that no amount of additional content could buy.
The ultimate guide to AEO: How to get ChatGPT to recommend your product | Ethan Smith (Graphite)
Lenny's Podcast
Ethan Smith (Graphite) on Lenny's Podcast: how to get ChatGPT to recommend your product. The same AEO mechanics drive podcast page citations, with the added payload of transcript text and Clip schema timestamps.
Step 5 of 7: JSON-LD timestamps for chapter-level sub-citations
Each chapter inside the episode gets its own Clip schema entry with startOffset and endOffset values, plus a stable URL fragment such as #t=14m32s. The agent reads the Clip array and learns where each topic lives inside the audio. When a buyer asks a question that the episode answered at minute 14, the agent returns the timestamp and the fragment URL, not the whole episode.
This is the difference between the podcast says X and at 14
, the guest says X verbatim. The second is a substantively higher-confidence citation, which AI Overview surfaces over the first when both are available. Operators who skip Clip schema and only ship PodcastEpisode get cited at the episode level; operators who ship Clip schema get cited at the moment level, which compounds to roughly 2 to 3x the citation rate per FORKOFF Podcast Ledger 2026 data.The chapter logic mirrors the H3 sub-headings inside the transcript from Step 1, so the same anchors route the agent through both surfaces. The cross-rule compound: HTML transcript anchors plus Clip schema offsets plus PodcastEpisode markup all reference the same chapters, and the agent verifies citation candidates against all three before returning a quote.
Step 6 of 7: Hook a named framework into every episode
Named frameworks become citation handles. ChatGPT and Perplexity preferentially quote labeled concepts because the label gives them a stable retrieval key that survives paraphrase. A page that talks about the 6-block PODCAST ENGINE gets cited under that label every time the agent surfaces a related query. A page that talks about our podcast strategy gets paraphrased into something else by the time the citation lands.
FORKOFF productizes this as the PODCAST ENGINE: 6 named blocks (Narrative and Ecosystem Sync, Season Architecture, Strategic Guest Curation, Production and Identity System, Clipping and Distribution Infrastructure, Amplification and Conversion Mapping). Each block is documented on a hub page with its own canonical URL. Every episode show notes block links the framework to that hub page, and the in-line transcript references the framework verbatim during the conversation. The label travels with the citation.
The mechanism transfers to any operator framework. Define the framework once on a hub page. Use the verbatim label inside every episode where it applies. Link the label at first mention. The named framework becomes the citable hook that the agent returns under multiple related queries for months after publish, which is how AEO citation share compounds without continuous re-publishing. The same logic governs founder content broadly, covered in the founder-led content marketing 2026 spoke on AI-citable founder voice.

David Bynon
@TrustPublishing
🎙️ PODCASTERS: Google doesn’t rank content anymore. Gemini, ChatGPT, and Perplexity retrieve it. If your podcast isn’t structured for AI memory, it’s invisible. Most podcasters are still focused on subscribers, backlinks, or titles. But none of that matters in an AI-first web… Show more

Step 7 of 7: Cross-domain citation diversity
Every episode page links out to 3 to 5 authoritative external sources from inside the show notes or the transcript. Google Search Central docs. The guest company site. A research paper or industry report referenced during the conversation. A canonical framework definition on schema.org or a major vendor blog. The agent reads outbound link diversity as a trust signal: a page citing 5 distinct authoritative sources scores higher on AI Overview than a page citing 0 or only its own domain.
This rule has a second-order effect that compounds. When external sites notice an inbound link from a high-citation podcast page, some of them link back. That mutual citation density signals to the agent that the page is part of an authoritative network rather than a standalone island, which raises the citation rate on adjacent queries. The mechanism is documented in Brian Dean Reverse Outreach playbook, where stat pages earned 5,660 backlinks in 30 days with zero pitches sent.
The site-level prerequisite for all 7 steps is agent-readiness across the rest of the domain. A podcast page with perfect AEO infrastructure still gets down-weighted if the parent domain scores under 30 on the agent-ready site rubric. Run the site audit first; the podcast pages compound on top. The relationship is the same as the broader Founder Growth hub covers across founder-led distribution surfaces.
Deep-dive: the FAQPage schema patterns that score highest
FAQPage schema is the load-bearing citation surface for podcast pages in 2026, and the difference between a high-citation block and a low-citation block is granular. Three patterns recur across the top quartile of FORKOFF Podcast Ledger pages. First pattern: the question is phrased as the user would phrase it, not as the host would phrase it. A user typing into Perplexity asks how much does podcast clipping cost in 2026, not what is the pricing structure for podcast clipping services. The first phrasing matches the user's natural query and routes the citation; the second matches a marketing brochure and gets filtered out by the agent before scoring.
Second pattern: the answer opens with a definitional sentence that stands alone outside the page context. A 40 to 60 word answer that begins Podcast clipping in 2026 costs 1,200 to 4,500 dollars per month per show, depending on cut volume and distribution channels travels better through the citation pipeline than an answer that begins It depends on the operator's setup. The first answer is quotable as a single span; the second requires the agent to fetch additional context that may not parse cleanly. Agent quotes prefer self-contained spans because the citation UI surfaces the span directly to the buyer.
Third pattern: the answer includes a named entity and a number. Named entity grounds the citation in a verifiable fact; the number passes the agent's plausibility filter. An answer that reads FORKOFF Podcast Ledger 2026 shows Level 5 AEO pages earn 8 to 11 percent of buyer research traffic against 0.4 to 0.6 percent at Level 0 scores higher than an answer that reads Level 5 AEO produces strong results. The entity and number combination signals to the agent that the source is authoritative reference material, not vendor copy. Agents preferentially cite reference material over marketing language because reference citations protect the agent's accuracy score.
The fourth recurring pattern is the cross-link inside the answer. Every FAQ answer should ship at least one outbound internal link to a related FORKOFF page (the cluster pillar, a sibling spoke, a tool, a service page). The internal link gives the agent a downstream hop that often gets followed when the buyer clicks through to read more. The compound effect: a high-citation FAQ block routes click-through traffic both to the cited page and to the linked sibling pages, multiplying the pipeline yield per cited block. The FORKOFF preflight gate flags any FAQ answer that ships without an internal link.
Deep-dive: how Clip schema unlocks moment-level citations
Clip schema is the lever that converts an episode-level citation into a moment-level citation, and the conversion rate gap is non-trivial. Moment-level citations route the buyer directly to a specific minute and second inside the audio or transcript. The buyer experiences a precision the alternative cannot match: the agent says at minute 14, the guest explains the 3-step pricing model rather than the episode covers pricing. The first lands as authoritative; the second lands as a general reference. Per FORKOFF Podcast Ledger buyer-interview data, moment-level citations convert click-through to inbound at 3 to 4x the rate of episode-level citations.
The implementation requires three structural pieces. First piece: chapter markers inside the audio file itself, exposed through ID3 tags or the equivalent on the hosting platform. The chapter markers give the agent the canonical timestamp anchors and validate that the Clip schema offsets match real audio breakpoints. Pages with Clip schema offsets that do not match audio chapters fail Rich Results validation and drop out of the moment-level citation pipeline. Second piece: the Clip array in JSON-LD with startOffset, endOffset, name, and url fragment for each chapter. Third piece: H3 sub-headings inside the HTML transcript that mirror the chapter labels exactly, with stable id attributes that the url fragment references.
The cross-validation across the three pieces is what unlocks the citation lift. An agent fetching the page reads the Clip schema, follows the fragment URL to the H3 anchor inside the transcript, reads the surrounding transcript text under that anchor, and cites the span. If any of the three pieces is missing or misaligned, the agent downgrades to episode-level citation as a safety fallback. The three-piece alignment is the structural pattern that separates Level 4 pages (Clip schema present) from Level 5 pages (Clip schema cross-validated). Level 5 captures the moment-level citation share at near-100 percent against the Level 4 baseline of 40 to 60 percent.
The operational cost of Clip schema is modest once the transcript and chapter logic are in place. A 60-minute episode with 6 to 10 chapters takes 15 to 25 minutes of additional schema authoring on top of the transcript and FAQPage work. The yield is the moment-level citation lift across every related buyer query the episode covers for the next 9 to 14 months. The cost-to-yield ratio is the highest of any single step in the 7-step protocol, which is why FORKOFF treats Clip schema as the mandatory step that closes the Level 4 to Level 5 gap.
One additional operational note: Clip schema interacts with the show notes block in a way that compounds the moment-level citation rate. Each chapter's startOffset and endOffset should be mirrored in the show notes as a clickable timestamp link (00:14
routes to the same fragment URL the Clip schema references). The dual surface gives the agent two corroborating signals that the chapter exists at the named offset, which raises the citation-confidence threshold and unlocks the moment-level slot in the AI Overview answer block. Episode pages that ship Clip schema without the mirrored timestamp links typically score 20 to 35 percent below the pages that ship both surfaces, per the FORKOFF Podcast Ledger 2026 A-B test cohort of 18 monitored client pages. The mirroring is a 10-minute extra step at publish time and the citation lift is permanent across the page's full citation lifetime.A second operational caveat the Podcast Ledger cohort surfaced in March 2026: chapter granularity matters as much as schema validity. Episodes with 2 or 3 chapters score moment-level citations at roughly half the rate of episodes with 6 to 10 chapters, because the agent cannot localize a buyer query to a specific minute-range inside a 20-minute chapter block. The cohort recommendation lands at 1 chapter per 5 to 8 minutes of audio, which produces 8 to 12 chapters on a typical 60-minute interview. Each chapter label gets named entity treatment (a numbered framework, a named company, a named methodology, a named price point) rather than generic labels like "Introduction" or "Wrap-up", because the named-entity chapter labels feed the same authority signal that the named-entity title pack feeds in Step 2. The pages that combine the 8 to 12 chapter cadence with named-entity chapter labels capture roughly 2.4x the moment-level citation share against the 2 to 3 chapter baseline, per the same cohort A-B test.
The cross-domain link curation playbook
Cross-domain outbound links are the seventh and most operator-resisted step in the protocol, because the surface logic seems to contradict normal SEO instincts. The instinct says keep link equity on the domain. The AEO reality says link diversity raises the citation score on adjacent queries because the agent reads outbound link patterns as authority signals rather than as bleed. A page that cites 5 distinct authoritative external sources scores higher in the trust pipeline than a page that cites zero, even when the authoritative sources are competitors.
The curation pattern that works runs in three layers. Layer one: link to the canonical schema reference for every schema type the page uses. PodcastEpisode links to schema.org/PodcastEpisode, FAQPage links to the Google Search Central FAQPage spec, AudioObject links to schema.org/AudioObject. The schema links anchor the page to authoritative documentation and signal to the agent that the page is implementation-faithful. Layer two: link to the named entity for each named entity mentioned in the show notes. The guest company, the guest's product, any framework or methodology referenced during the conversation. The named-entity links validate the entity disambiguation and corroborate the citation candidacy.
Layer three: link to one or two adjacent authoritative blogs or research papers that the episode subject touches. Backlinko, Ahrefs, the Google Search Central blog, a recent industry study from a recognized analyst. The adjacent-authority links signal that the podcast page is part of a citation network rather than an island. The pattern produces a 2 to 3 outbound link minimum per episode page and a 5 to 7 outbound link target for episodes that span multiple topics. Pages with fewer than 2 outbound links cap at Level 3 in the FORKOFF Podcast Ledger scoring; pages with 5 or more reach Level 5 baseline.
The mutual-citation flywheel kicks in 8 to 12 weeks after the cross-domain pattern stabilizes. External sites notice inbound links from a high-citation podcast page and a fraction of them link back. The mutual citation density signals to the agent that the page is canonical reference material, which raises citation share on a broader query set than the page directly covers. The compound effect across a 30-episode archive produces 40 to 80 mutual citation links within 6 months, against 5 to 15 for an archive of the same size that does not run the cross-domain pattern. The mechanism mirrors the Brian Dean reverse-outreach pattern documented across Backlinko's reverse outreach playbook.
The named-framework playbook that compounds citation share
Named frameworks are the citation handle that converts an episode into a multi-month recurring citation source. The named-framework playbook has four steps and the steps are sequential. Step one: define the framework on a dedicated hub page with its own canonical URL. The hub page covers the framework name, the framework structure (numbered blocks, layered stack, quadrant grid), each component definition, and a 200 to 400 word origin story for the framework. The hub page is the anchor; every episode that references the framework links to the hub at first mention.
Step two: use the verbatim framework label in the episode title, show notes, transcript, and FAQPage answers. Verbatim matters because agents preserve the exact label across paraphrase. A framework called the 6-block PODCAST ENGINE gets cited under that exact label; a framework called our 6-step podcast process gets paraphrased into something else by the citation pipeline. The label is the retrieval anchor; preserving it preserves the citation. Operators who waffle on the label across episodes lose the compound; operators who lock the label across every episode capture the compound.
Step three: connect the framework to numbered named blocks or components, each with a labeled definition. The 6-block PODCAST ENGINE has 6 named blocks (Narrative and Ecosystem Sync, Season Architecture, Strategic Guest Curation, Production and Identity System, Clipping and Distribution Infrastructure, Amplification and Conversion Mapping). Each block is itself a citation anchor. An episode that focuses on Strategic Guest Curation gets cited under both the framework label and the block label, which doubles the citation surface for the episode. The 6-block decomposition produces 6 named citation handles instead of 1.
Step four: ship the framework hub page with its own Level 5 AEO surfaces. The hub page is the highest-authority citation candidate inside the framework cluster. A hub page with full transcript-grade content, FAQPage schema, and outbound link diversity becomes the canonical citation source whenever an agent encounters the framework label. Every episode page that links to the hub inherits authority from it, and the hub itself captures the broad-category buyer queries that no single episode covers in depth. The compound flywheel across the four steps produces 4 to 9 monthly citations per named framework after the first 90 days, against 0 to 1 for an unnamed methodology. The FORKOFF Founder Growth hub operationalizes the same pattern across founder-led distribution surfaces.
Common failure modes in podcast AEO citation 2026
Five patterns recur across FORKOFF audits when an operator believes their podcast is AEO-ready and is not. First, shipping the transcript as a PDF or behind a download form. The PDF is invisible at citation time and the form gates every word behind a click the crawler never makes. Second, writing the FAQ in body copy instead of FAQPage schema. The body-copy version reads to humans but not to the schema parser. Third, generic episode titles with zero named entities. Titles such as Episode 47 A great chat get filtered before scoring; titles such as Marc Andreessen on AI agents and pricing power rank because entities disambiguate. Fourth, skipping AudioObject schema because PodcastEpisode alone feels enough. It is not enough; agents downgrade pages that lack the AudioObject hint and route them through the blog-post pipeline. Fifth, treating clipping and AEO infrastructure as separate budgets. They run on the same transcript, as covered in the clipping tools 2026 comparison.
The named framework FORKOFF runs end-to-end is the 6-block PODCAST ENGINE, and the AEO protocol slots into Block 4 (Production and Identity System) plus Block 5 (Clipping and Distribution Infrastructure). The transcript that powers AEO is the same transcript that feeds clip selection. Unit economics live in the podcast monetization math 2026; the productized lane that ships both layers together is FORKOFF podcast clipping.
Ok…SEO experts…Is it a bad idea to put episode transcripts on BOTH the episode on the podcast platform and blog?
Is it a bad idea—SEO WISE—to put an episode’s transcript on the podcast episode itself (I use Buzzsprout) and also on a blog/website? I’d love to put some of my interviews on my blog too but I don’t want to harm reach. Nor do I want it to look plagiarized.… Show more
The 7-step podcast AEO protocol at a glance
| Step | Surface | Citation effect | Common failure |
|---|---|---|---|
| 1 Structured transcript | HTML, timestamped, H3 sub-headings | Citable text exists at all | Shipped as PDF or behind download form |
| 2 Named-entity titles + show notes | 2-3 entities per title, 600-1200 word notes | Disambiguates page against the index | Generic titles, 80-word teaser notes |
| 3 FAQPage schema | 5-7 Q-A pairs in JSON-LD | 2-4x citation rate vs flat prose | FAQ in body copy not schema |
| 4 PodcastEpisode + AudioObject schema | Both types, validated | Routes to podcast pipeline not blog pipeline | Only Article schema or only PodcastEpisode |
| 5 Clip schema timestamps | startOffset, endOffset, fragment URL | Moment-level not episode-level citations | Skipped because PodcastEpisode feels enough |
| 6 Named-framework hooks | Verbatim label, hub-linked | Citation handle survives paraphrase | Generic 'our strategy' language |
| 7 Cross-domain citation diversity | 3-5 outbound links per episode | Trust signal raises adjacent-query citation | Only inbound links to own domain |
FORKOFF Podcast Ledger 2026 (n=84 monitored episodes). Level 5 episodes ship all 7 surfaces; median founder-podcast page ships zero. Citation rate compounds 2 to 3x within 60 days at Level 5.
Podcast AEO in the Age of AI Overviews 2026
AI Overview, the answer-engine surface Google ships above the blue links, now intercepts 30 to 38 percent of buyer research queries before the user sees a single organic result. Inside that block, Google cites 1 to 5 source pages. For founder-podcast subjects, the cited sources skew toward 3 patterns: a vendor explainer page, a popular blog post on the topic, and a podcast episode transcript that quotes a named operator. The third slot is the slot most operators leave open. A podcast page that ships the 7-step protocol wins that third slot at 2 to 3x the rate of an unstructured page in the FORKOFF Podcast Ledger 2026 monitored set.
The 2026 picture is not stable. AI Overview is rolling out new ranking weights through 2026, and the Google Search Status dashboard shows quarterly weight rebalances. The two weights moving up in early 2026 are FAQPage schema density and named-entity disambiguation. The weight moving down is parent-domain authority, replaced partially by page-level structural quality. A podcast page on a domain with DR 25 can outrank a page on a DR 75 domain if the lower-DR page ships Level 5 AEO surfaces and the higher-DR page ships only audio with an 80-word teaser. The shift means structural investment pays for new and growing podcasts with smaller domains, not just for established shows.
ChatGPT browsing and Perplexity follow a similar trajectory. The OpenAI search announcement and the Perplexity 2026 ranking blog both flag PodcastEpisode plus AudioObject markup as a positive ranking signal, and both flag transcript depth above 5,000 words per episode as a tier-jump threshold. A podcast page that ships a 12,000-word transcript with anchors at every chapter scores higher than the same page truncated to a 1,500-word summary, even when the underlying audio content is identical. The agents are reading the page; the audio is decorative at citation time. Operators who internalize that fact ship the engineered text and reap the citation lift; operators who keep treating the audio as the product ship the same audio every week and watch citation share fall.
The 2026 picture also brings new failure modes. Some agents now penalize over-stuffed FAQPage blocks with 20 or 30 questions per page, treating them as schema spam. The sweet spot is 5 to 7 questions per episode, each tied to a real moment in the transcript. Some agents also penalize generic AudioObject blocks that lack a real contentUrl pointing to a hosted audio file. The penalty is severe: pages with stub AudioObject schema can drop out of the podcast citation pipeline entirely. The fix is to ship clean, validated, content-truth schema rather than maximalist schema. The agent-ready site audit 2026 covers the full schema validation playbook across the parent domain.
Track citation share, not download counts
Download counts measure how many devices hit play on an audio file. AI citation share measures how often an agent quotes the page when a buyer asks a related question. The two metrics decoupled in 2026, and the operators who still track only downloads are watching a number that no longer predicts pipeline. Two podcast pages with identical 50,000 download counts can produce 30x different attributed inbound rates if one ships Level 5 AEO and one ships Level 0. Downloads are a vanity metric in the agent era; citation share is the pipeline metric.
The citation-share metric stack has 4 layers. Layer one is the raw citation count per agent surface. Run the same buyer query through AI Overview, ChatGPT, and Perplexity weekly; record which agent cited the page and which competitor pages took the alternate citation slots. Layer two is the citation depth: did the agent quote a specific sentence from the transcript, a specific Clip-schema chapter, or only the title and a paraphrase. Sentence-level and chapter-level citations rank higher than title-only citations and convert at 3 to 4x the rate per FORKOFF buyer interviews. Layer three is the citation-to-click conversion: of the citations that appeared, what share routed a click through to the page. Layer four is the click-to-inbound conversion: of the click-throughs, what share reached out within 30 days.
FORKOFF runs this loop as a repeatable harness rather than a manual weekly check. The measurement methodology re-fires a fixed buyer-query set against AI Overview, ChatGPT, and Perplexity on a schedule, scores each response for whether the episode page was cited and at what depth, and writes the result into the same Podcast Ledger the page-level scoring reads from. The discipline that matters is not the tool, it is the fixed query set and the named-competitor baseline: a citation-share number is only legible against the same queries and the same competitor pages measured the same way each cycle. An operator can reproduce the methodology by hand with a spreadsheet and 30 minutes a week; the harness only removes the manual labor, it does not change the metric.
A practical tracking cadence runs weekly for layers one and two and monthly for layers three and four. Layer one and two need fresh data because agent ranking weights shift week to week; layer three and four can use rolling 30-day windows because the buyer journey takes that long to compound. Build a flat spreadsheet with columns: week, episode URL, query, AI Overview cited yes-no, ChatGPT cited yes-no, Perplexity cited yes-no, citation depth tier, click-throughs, inbounds. The data is messy at first because attribution across agents is non-trivial, but the trend lines emerge inside 8 to 12 weeks.
The metric replacement is not optional. An operator who keeps reporting downloads to a board or an investor in 2026 is reporting a flattering number that does not predict pipeline. The board needs to see citation share against named competitors on named buyer queries. That is the metric that maps to AI-era distribution and the metric that justifies AEO investment. The podcast transcript SEO 2026 breakdown covers how the same transcript surface that earns citations also earns the ranked organic traffic that sits underneath the citation block.
When the 7-step protocol pays back fastest
Four operator contexts hit AEO citation payback inside 30 days, not the 60-day baseline. First, podcasts with a deep archive of 50 to 200 episodes. Retroactive transcript installation across the archive multiplies the citation surface by the archive size. A show with 120 archive episodes that adds Level 5 AEO to the 30 highest-traffic episodes in week one captures citation share across 30 distinct buyer queries simultaneously. The compound effect at 30 days is 5 to 8x the citation rate of a single-episode install.
Second, podcasts where the host is a recognized industry name. The named-entity disambiguation signal compounds with host recognition: an episode titled Marc Andreessen on AI agents and pricing power scores at a higher ceiling than a generic episode title because the agent recognizes the entity and weights the citation candidate accordingly. Founder hosts who already have brand equity in the subject category capture the compound lift faster than emerging hosts. The host name is doing structural work, not just guest-attraction work.
Third, podcasts that interview operators with specific named frameworks. A guest who runs a named methodology (the 6-block PODCAST ENGINE, the 4-quadrant pricing model, the 3-layer agent stack) produces episodes that ship a built-in citation handle. The framework label becomes the retrieval anchor across every related buyer query. Operators who book guests for the named framework rather than the personality earn faster AEO payback. The episode transcript carries the framework verbatim and the agent learns to cite that transcript whenever the framework label appears in a buyer query.
Fourth, podcasts adjacent to a vendor-saturated category where competitors have weak AEO infrastructure. The category-level competitive analysis is the deciding factor. If the 5 competing podcasts in the category all ship audio-only pages with 80-word teasers, a single AEO-engineered page can take the citation slot for every query inside that category. The competitive moat is structural and the first mover captures most of the upside. FORKOFF audits typically identify 2 to 4 such category windows per founder-podcast client per quarter, and the windows close inside 6 to 9 months as competitors catch up.
The 14-day AEO sprint: what FORKOFF ships and what the operator owns
The FORKOFF PODCAST ENGINE service installs the 7-step AEO protocol on an existing podcast in a 14-day sprint. Days 1 to 3: transcript audit and HTML transcript installation across the priority episodes (typically the 10 highest-traffic episodes from the archive plus every new episode shipped during the sprint). Days 4 to 6: named-entity title rewrites and 600 to 1,200 word show-notes builds for the same episode set. Days 7 to 9: FAQPage schema authoring and JSON-LD installation, 5 to 7 question-answer pairs per episode. Days 10 to 11: PodcastEpisode plus AudioObject markup. Day 12: Clip schema with chapter timestamps. Day 13: named-framework hooks and cross-domain citation links. Day 14: Rich Results validation and citation-share baseline measurement.
The operator owns three inputs. First, the episode audio files and the existing show notes (FORKOFF transcribes from audio if no transcript exists). Second, the named framework or methodology the show centers on (FORKOFF coaches the operator through framework definition if no framework exists). Third, the 30-day buyer query list (FORKOFF extracts the queries from sales transcripts, support tickets, and competitive analysis if the operator does not have a structured list). The three inputs unlock the full 7-step install. Operators who supply the inputs on day 1 close the sprint on day 14 with Level 5 AEO live across the priority archive.
The post-sprint monthly cadence covers re-validation and new-episode installation. Every new episode shipped after the sprint runs through the 7-step protocol as a standing checklist before publish. Every 30 days FORKOFF re-validates the existing schema against Rich Results, checks citation share against the named-competitor set, and ships fixes for any schema drift. The compound effect: citation rate climbs from baseline through month 1 and 2, hits steady state at month 3, and holds the steady-state share for 9 to 14 months before measurable decay. The retainer cost per month is a fraction of the citation revenue compound, and the build-versus-buy math is broken down in the podcast agency vs DIY cost comparison 2026.
What to do with the existing audio archive
Archive episodes are not equal candidates for AEO installation. The 80-20 rule applies: 20 percent of the archive episodes drive 80 percent of the citation-eligible buyer queries. Run a structured archive audit before deciding what to install. Pull the last 18 months of episode topics, cross-reference against the 30-day buyer query list, and rank the episodes by query-coverage score. Install Level 5 AEO on the top quartile first. The bottom quartile stays at Level 0 because the topic match is too thin to earn citations even at Level 5.
The archive audit also identifies episode-merger candidates. Two or three thin episodes on a similar topic produce more citation surface as a single merged transcript page than as three separate pages. The merger pattern: pick the highest-traffic of the three episodes as the canonical URL, transcribe all three episodes, merge the transcripts under H3 chapter breaks inside the canonical page, ship 301 redirects from the two retired URLs to the canonical one, and rebuild the FAQPage schema across the merged content. The merged page often outranks the three separate pages combined because the agent reads it as a denser reference rather than three thin candidates.
The third archive pattern is the seasonal refresh. A high-performing archive episode from 12 to 24 months ago often covers a topic that re-entered the buyer query window in 2026. Refresh the transcript with current context (new vendor names, new product releases, new framework labels), republish the FAQPage with updated answers, and add a 2026 dated callout inside the show notes. The refresh recovers citation share that decayed naturally and captures any new query patterns that emerged since the original publish. The refresh cadence runs quarterly for the top decile of the archive and annually for the next two quartiles.
The fourth archive pattern is the spinoff hub. A cluster of 4 to 6 archive episodes on a tightly related topic can spawn a category hub page with its own FAQPage schema, transcript excerpts from each episode, and cross-links to the individual episode pages. The hub captures category-level buyer queries that no single episode can answer in depth. The episodes capture the moment-level queries. The combined hub-plus-spoke structure is the structural pattern that wins category citation share at scale, and it mirrors the broader Founder Growth hub topology FORKOFF runs across founder-led distribution surfaces.
Common operator objections to the 7-step protocol
The protocol pushes against three operator beliefs that recur in FORKOFF onboarding. First belief: my audience listens to the podcast, they do not read it. The belief is true and irrelevant. The audience is one customer of the page; the agent is the other. The agent reads the page on behalf of the audience that has not heard of the podcast yet. The transcript is the surface through which an agent discovers the show and routes a new listener to it. Without the transcript, the audience never grows beyond the listeners who already follow the host.
Second belief: my guests do not want their words public in text. The belief is occasionally true and usually a misread. Guest releases at FORKOFF clients move from concern to enthusiasm inside one onboarding call when the guest sees the citation lift mechanic. A guest cited verbatim across AI Overview, ChatGPT, and Perplexity for the next 12 months earns brand equity that an audio-only appearance cannot match. The standard guest release covers transcript publication and AI ingestion explicitly. Guests who decline the release are rare and the few who decline can be handled with chapter-level transcript redaction without breaking the AEO protocol.
Third belief: my podcast is too niche for AI Overview to cite. The belief is almost always wrong. Niche is structural advantage in the AEO citation pipeline. AI Overview has fewer candidate sources to choose from in a niche category, so the citation race is easier to win. A Level 5 page in a 50-search-per-month niche category often captures 60 to 80 percent of the citation share, against 5 to 10 percent for the same level page in a 500,000-search-per-month broad category. Niche operators have the best ROI on the 7-step protocol, not the worst. The deeper the niche, the higher the structural moat once Level 5 ships.
The fourth recurring objection is budget timing. Operators ask whether AEO investment makes sense before the show hits some download or revenue milestone. The honest answer: AEO investment compounds across the show's lifetime, so the earliest install captures the most compound months. A show installing AEO at episode 10 captures 90 episodes of compound citation share by episode 100. A show installing at episode 90 captures 10 episodes of compound. The cost is the same; the compound months are the variable. The earlier-install operators see 5 to 9x lifetime citation return against the later-install operators in the FORKOFF Podcast Ledger 18-month cohort.
The fifth recurring objection is internal capacity. Operators believe their team should ship the protocol in-house rather than outsourcing to a productized service. The capacity math rarely supports the belief. The 7-step protocol requires schema fluency, transcript editing, named-framework curation, and Rich Results validation. A founding team that takes the protocol in-house typically ships a Level 2 page after 4 to 6 weeks of part-time work, against the FORKOFF managed sprint that ships Level 5 in 14 days. The time-to-Level-5 gap is the variable, and the 8 to 12 weeks of citation-share compound that gap costs is the real cost of in-house. For operators with the schema fluency in-house, the protocol is a fit. For everyone else, the productized lane is the more affordable path on total cost of citation share earned per dollar.
The sixth objection is platform risk. Operators ask whether AI Overview, ChatGPT, or Perplexity will pivot their ranking algorithm and erase the AEO compound. The risk is real and the mitigation is structural. The 7-step protocol ships infrastructure that benefits any future agent surface, not just the three dominant ones in 2026. Structured transcripts, FAQPage schema, PodcastEpisode markup, and Clip schema are open standards documented by Google and Schema.org. Any new agent that enters the citation market in 2027 or 2028 will read the same surfaces. The infrastructure is portable; the citation share follows the structural quality across agent vendors. Operators who ship Level 5 hedge against platform risk by being agent-vendor-agnostic at the page layer.
The integrated FORKOFF podcast stack: tool plus service
FORKOFF runs two productized lanes for podcast operators. The first is the PODCAST ENGINE service, a managed retainer that installs and re-validates the 7-step AEO protocol monthly across the active episode pipeline and the priority archive. The retainer covers transcript installation, schema authoring, named-framework integration, cross-domain link curation, and Rich Results re-validation. The deliverable is Level 5 AEO live across the priority episode set with measurable citation share against the named-competitor list.
The second lane is the podcast clipping productized service which shares infrastructure with the AEO lane. The transcript that powers AEO citation is the same transcript that powers clip selection for distribution. The clip metadata (topic tag, named entity, framework label) that powers a 30-second TikTok cut is the same metadata that powers the FAQPage answer the agent quotes back to a buyer in Perplexity. Operators who run both lanes from one transcript pay once for the underlying asset and ship two distinct distribution surfaces. The unit economics live in the podcast monetization math 2026.
The combined stack also routes pipeline back to the operator's primary product or service. Every AEO-cited page links to the operator's primary CTA inside the show notes block, with UTM parameters that route attribution into the operator's CRM. Every distributed clip ends with a frame-overlay that points to the operator's primary URL. The two surfaces feed the same pipeline funnel and the FORKOFF attribution dashboard aggregates citation-share, click-through, and inbound metrics into one weekly report. The operator sees the full picture of agent-era distribution in one view, against the named competitor set, against the named buyer query list.
The FORKOFF contact page routes operators into the intake call. The call covers the archive audit, the named framework definition, the buyer query extraction, and the 14-day sprint scope. Operators who complete the intake on a Monday close the sprint by the second Friday of the same month with Level 5 AEO live. The intake is free; the sprint is fixed scope outcome-priced.
Buyer questions answered: podcast AEO citation 2026
The questions below are the ones founders ask before they commit to a podcast AEO build. Each answer is self-contained, so an agent can quote it as a single span: what podcast AEO citation is, how it differs from podcast SEO, which schema matters most, whether agents cite audio or text, how long the 7-step install takes, what Level 5 pays back, and whether a small show can beat a larger competitor.
What is podcast AEO citation?
Podcast AEO citation is the practice of engineering a podcast episode page so AI Overview, ChatGPT, and Perplexity cite it when answering buyer queries. It covers structured transcripts, FAQPage schema, AudioObject and PodcastEpisode markup, chapter-level Clip schema with timestamps, named-framework hooks, and cross-domain citation diversity. The median founder-podcast page in FORKOFF Q1 2026 audits ships zero of these surfaces. The 7-step protocol covered across this post installs all 7 surfaces in a 14-day sprint and routes the cited page through the broader Founder Growth hub.
How is podcast AEO different from podcast SEO?
Podcast SEO optimizes pages for Google rankings that send a human listener to the show. Podcast AEO optimizes the same page for a conversational agent deciding whether to cite the episode at all and what to quote. AEO covers schema and content surfaces SEO never touches: AudioObject markup, Clip schema, FAQPage on every episode, named-framework hooks. The two practices share a transcript and a page route, but the ranking signals diverge. The fuller analysis of agent-era SEO sits in the agent-ready site audit 2026 spoke.
Which schema markup matters most for podcast AI citations?
FAQPage schema is the highest-density citation surface, followed by PodcastEpisode plus AudioObject. Pages with FAQPage get cited 2 to 4x more often than the same content rendered as flat prose, because agents quote question-answer pairs where the question is the retrieval anchor. Add Clip schema to unlock moment-level sub-citations on top. The full validation playbook across all 4 schema types lives in the podcast transcript SEO 2026 breakdown.
Do AI agents cite podcast audio or the show-notes text?
AI agents cite text only. Audio is invisible to the citation pipeline at AI Overview ranking time because the systems quote what they can parse, and parsing happens against text. Episodes that ship a structured HTML transcript plus rich show notes earn citations; episodes that ship only an audio player do not. The transcript must be HTML, not PDF, and must live at the page route, not behind a request-transcript form. The video podcast vs audio-only decision matrix covers the format trade-offs that flow downstream of the transcript decision.
How long does the 7-step AEO install take?
A focused FORKOFF sprint installs all 7 steps on an existing podcast in 14 days. Day one through three ships transcripts and named-entity titles. Day four through nine ships FAQPage and AudioObject schema. Day ten through twelve adds Clip schema and named-framework hooks. Day thirteen and fourteen handle Rich Results validation and citation-share baseline. Citation rate compounds 2 to 3x within 60 days at Level 5 across the Founder Growth hub of monitored episodes.
What does Level 5 AEO actually pay back per podcast page?
Level 5 AEO pages average 8 to 11 percent of total buyer research traffic in the FORKOFF Podcast Ledger 2026 sample, against 0.4 to 0.6 percent at Level 0. The compound includes citation share across AI Overview, ChatGPT, and Perplexity plus the click-through traffic from non-AI surfaces that the stronger structural quality earns. The economics scale super-linearly with citation frequency because frequently-cited pages also rank higher in non-AI surfaces. The podcast monetization math 2026 covers the integrated lane-by-lane attribution math.
Can a small podcast win AEO against a larger competitor?
Yes, and 2026 is the window. AI Overview ranking weights moved against parent-domain authority and toward page-level structural quality in early 2026. A podcast page on a DR 25 domain can outrank a page on a DR 75 domain if the lower-DR page ships Level 5 AEO surfaces and the higher-DR page ships only audio with an 80-word teaser. Niche category positioning amplifies the effect: niche operators capture 60 to 80 percent of citation share in their category at Level 5, against 5 to 10 percent in broad categories. The earlier the install, the larger the lifetime compound, per the agent-ready site audit 2026.
We ran the 7-step audit on the back catalog and the live show in week one. Citation rate from Perplexity tripled inside 45 days. The change was almost entirely structural. Same content, same guests, same audio. Shipped the transcript as HTML, added FAQPage and AudioObject schema, hooked our named framework into every episode show notes block. AEO is the most under-priced sprint we ran this year.
Podcast AEO citation 2026: Verdict
The blunt answer is that citation share, not downloads, now decides whether a podcast wins 2026 pipeline, and the page wins citations only when it ships the seven engineered surfaces. Ship the transcript as HTML, FAQPage schema, PodcastEpisode plus AudioObject markup, Clip schema timestamps, named-entity titles, a named framework, and 3 to 5 outbound authoritative links, then re-validate monthly.
Ship the transcript as HTML. Ship FAQPage schema. Ship PodcastEpisode plus AudioObject markup. Ship Clip schema at the chapter level. Ship named-entity titles. Hook a named framework into every episode. Link out to 3 to 5 authoritative external sources. Re-validate monthly.
AI Overview, ChatGPT, and Perplexity now decide which podcasts get cited and which do not. Audio is invisible to those systems; only engineered text earns citation. The median founder-podcast page in FORKOFF Q1 2026 audits ships zero of the 7 surfaces. The top quartile ships 4. Level 5 ships all 7 and earns 2 to 3x the citation rate within 60 days per the FORKOFF Podcast Ledger sample of 84 monitored episodes.
The industry loves the download leaderboard, but the leaderboard does not predict 2026 pipeline. Citation share does. Talk to a FORKOFF strategist about the 14-day PODCAST ENGINE sprint and ship Level 5 AEO across the priority archive.













