

An agent-ready site is one that Claude, ChatGPT, and Perplexity can crawl, trust, act on, and cite in under a second. FORKOFF audited 47 founder sites against the 100-point agent-readiness rubric in Q1 2026 and found a median score of 22 out of 100. This post walks through all five layers of the rubric and the sprint-week installs that move a site from invisible to cited.
About these numbers
FORKOFF first-party operator data from founder-led growth and distribution engagements, supplemented by publicly available benchmarks (SaaStr, Lenny's Newsletter, a16z 2025-2026). All figures are directional estimates based on operator observations; individual outcomes vary by stage, niche, and execution.
The Agent-Ready Scorecard in one scroll
AI agents now pre-filter founder sites before human buyers ever see them. The median founder site in FORKOFF Q1 2026 audits scores 22 out of 100 on agent-readiness. The 100-point scorecard is 5 layers: Discovery (llms.txt + sitemap), Trust (schema + .well-known), Action (MCP + WebMCP), Negotiation (markdown middleware), Retrieval (citation-friendly H-tree). Level 5 = 100/100. This post is the full rubric with FORKOFF first-party data.

The AGENT-READY SCORECARD
The AGENT-READY SCORECARD is FORKOFF's 100-point audit for AI buyer routing across five layers: Discovery (20 points, covering llms.txt, sitemap, and robots.txt posture), Trust (25 points, covering schema markup and well-known manifests), Action (25 points, covering MCP server and tool definitions), Negotiation (15 points, covering markdown content negotiation), and Retrieval (15 points, covering H-tree hierarchy and FAQ schema). The median founder site scores 22 out of 100 and the gap is fixable in a sprint, not a rebuild.
The AGENT-READY SCORECARD: five layers, 100 points
| Layer | Points | Top surface scored | First fix |
|---|---|---|---|
| Discovery | 20 | llms.txt, sitemap.xml, robots.txt posture | Ship llms.txt at the domain root |
| Trust | 25 | Schema.org suite, seven .well-known manifests | Author the seven .well-known JSON files |
| Action | 25 | MCP server, WebMCP card, Agent Skills manifest | Ship a 100-line MCP server with four operations |
| Negotiation | 15 | Accept text/markdown middleware, Link headers | Add 40-line markdown middleware on the edge |
| Retrieval | 15 | Stable heading ids, FAQ schema, durable anchors | Give every H2 and H3 a stable id |
FORKOFF first-party rubric. Median founder site scores 22 of 100 across 47 seed and Series A audits in Q1 2026; forkoff.xyz and clips.forkoff.xyz both score 100 of 100 at Level 5.
Industry Context
Across the FORKOFF Founder-Funnel Cohort 2026 (n=42 retainers), founder sites scoring above 70 on the AGENT-READY SCORECARD pull 3-4x more AI-overview citations than the median 22-of-100 baseline; closing the gap moves AI-routed pipeline within 30 days.
Source: FORKOFF Founder-Funnel Cohort 2026, n=42

The YC founder whose site the agent refused to cite
In Q1 2026 a seed-stage YC founder came to us after a Perplexity citation run. They had spent nine months on brand, a fresh Framer site, a decent SEO pass, and a founder-voice X account with 4,200 followers. When a prospect pasted their domain into Claude and asked for a product summary, the agent returned a generic paragraph sourced from the homepage meta description and refused to cite any specific claim. The prospect moved on to a competitor whose site answered cleanly and with structured citations. The founder lost the meeting they did not know they were in.
This is the single biggest distribution shift of 2026. Your site is no longer read first by a human. It is read first by an agent, and the agent decides whether the human ever sees it. The discipline that fixes the gap is agent-readiness, and unlike traditional SEO it is a rubric with exact technical requirements you can install in a sprint.
The behavior gap behind that lost meeting is worth dwelling on. A 2024 buyer hitting Google saw a list of links, clicked three of them, and read landing pages. A 2026 buyer hitting Claude or ChatGPT sees a synthesized answer. The links that anchor that answer are the only ones the buyer ever opens. If your domain never enters the agent's citation set, the buyer never knows your product exists. Worse, when the agent does cite a competitor by name and quotes a structured claim from their site, the buyer treats that quote as a third-party endorsement. Trust transfers from the agent to the cited domain. Founders who get cited compound. Founders who do not stay invisible at the exact moment the buyer is most receptive.
Generative AI solutions are becoming substitute answer engines, replacing user queries that previously may have been executed in traditional search engines.
Two independent sources confirm the buyer-routing shift
Gartner forecast in February 2024 that traditional search engine volume would fall 25 percent by 2026 as buyers move to AI chatbots and virtual agents. Pew Research Center found in July 2025 that Google users who saw an AI summary clicked through to a website on only 8 percent of visits, against 15 percent when no summary appeared, and that AI summaries already ran on 18 percent of all searches. The click that used to reach your site is intercepted by an answer the agent composes, and the only domains that survive are the ones the agent can parse, trust, and cite.
Source: Gartner press release, Feb 19 2024 (25 percent search-volume forecast); Pew Research Center, Jul 22 2025 (AI Overviews click study, n=900 US adults)
Founders who score below 40 on the rubric and do not have a sprint-week to install the gap typically retain an AI marketing agency that ships agent-ready surfaces as the first 30-day deliverable of the engagement.
FORKOFF audited 47 founder sites between January and April 2026 against the public scoring rubric on isitagentready.com. The median score was 22 out of 100. The bottom quartile scored 8. The top quartile scored 71. Forkoff.xyz and clips.forkoff.xyz both score 100 out of 100 at Level 5 agent-native, which is what the rubric below is built to reach.
The shape of the distribution matters as much as the median. Of the 47 sites audited, 11 sat between 0 and 15, another 14 sat between 16 and 30, 12 sat between 31 and 55, 7 sat between 56 and 75, and only 3 sat above 76. The cluster at the bottom is not made up of negligent teams. Every founder in that band had paid for a designer, a copywriter, and an SEO retainer in the prior 12 months. They simply had not been told the rubric existed. The cluster at the top is not made up of teams with bigger budgets. The 3 sites above 76 spent less on their site builds than the median. They spent their hours on the right surfaces.
Operator note47 founder sites audited in Q1 2026, median 22 of 100. Every site in the 0-30 band had paid a designer and an SEO retainer that year., FORKOFF founder-site audit set, Q1 2026
The 2026 AI buyer-routing backdrop
| Signal | Figure | Source |
|---|---|---|
| Traditional search volume forecast by 2026 | down 25 percent | Gartner, Feb 2024 |
| Google searches that already return an AI summary | 18 percent | Pew Research, Jul 2025 |
| Click to a website when an AI summary appears | 8 percent (15 percent without) | Pew Research, Jul 2025 |
| AI summaries that cite three or more sources | 88 percent | Pew Research, Jul 2025 |
| Median length of a Google AI summary | 67 words | Pew Research, Jul 2025 |
Pew Research Center tracked 68,879 Google queries from 900 US adults in March 2025; 12,593 triggered an AI summary. Gartner forecast published Feb 19, 2024.
38 percent, 22 of 100, and the isitagentready rubric that made this concrete
Three numbers anchor the 2026 agent-readiness thesis. First, roughly 38 percent of B2B buyer research now begins inside an AI agent such as Claude, ChatGPT, or Perplexity rather than on Google, a jump from about 12 percent in 2024 across major buyer surveys. Second, FORKOFF Q1 2026 founder-site audits across 47 seed and Series A companies found a median score of 22 out of 100 on the isitagentready.com public rubric, with the gap concentrated in the Action and Negotiation layers where MCP servers and markdown content-negotiation live. Third, the rubric itself matters because it formalized what had been tacit. Before Cloudflare published a public scanner, no founder could tell you whether their site was agent-ready or not. Now they can, and the teams treating the 100-point target as a launch gate are compounding faster than peers still running the 2022 playbook.
Source: FORKOFF founder-site audits Q1 2026 (n=47); isitagentready.com public rubric; a16z 2026 State of AI buyer survey aggregates

Why agent-readiness is not SEO and not schema alone
The common objection is that agent-readiness is just SEO with more tags. It is not. Traditional SEO optimizes a page for a ranking function that shows a user a link. Schema markup optimizes a page for a snippet that surfaces above that link. Agent-readiness optimizes a domain for a conversational agent that is deciding whether to cite your site at all, and if so, what to quote, what to call into, and what to recommend to the human on the other side of the chat.
That decision lives inside five discrete layers. Each layer has a different technical surface. Each layer is scored independently. A site can have flawless schema and still score zero on Action because it never shipped an MCP server. A site can have a rich MCP endpoint and still score zero on Discovery because it never published llms.txt. The rubric compounds because every agent in 2026 checks all five layers and downgrades the domain if any single layer is missing.
The five layers below are the FORKOFF internal scorecard. Each has a point value, a list of the specific files and endpoints the layer scores, and a reference implementation. None of it requires a rebuild. All of it can be installed on an existing Next.js, Astro, WordPress, or Webflow site inside one focused week. For a fast read on where your Discovery layer stands before going through all five, the free AEO checker surfaces AI crawler access, llms.txt status, and schema baseline in one pass.
Sar Haribhakti
@sarthakgh
.@WorkOS and @resend shipped pricing pages legible to agents:


Layer 1 of 5: Discovery (20 points)
Discovery is the agent's first pass on your domain, covering three files that determine whether the site is treated as a serious information source or a black box: llms.txt (10 points) which enumerates the canonical URLs an agent should prioritize, sitemap.xml tuned with lastmod and changefreq attributes (6 points), and a robots.txt that explicitly allows the four main agent user-agents rather than leaving them to default implicit allow (4 points).
For the Claude Code MCP stack that automates these audit layers, see the Claude Code SEO stack documentation, which maps Ahrefs, DataForSEO, Firecrawl, and GSC MCPs into a single discovery workflow.
Discovery is the agent's first pass on your domain. Before the agent reads a single product claim, it fetches three files and decides whether your site is a serious information source or a black box.
llms.txt (10 points). The llms.txt spec, published in late 2024 and now supported by every major agent, is the agent-native analog of robots.txt. It lives at the root of your domain, enumerates the canonical URLs an agent should prioritize for training and citation, and gives a summary the agent uses as context when summarizing your company. FORKOFF ships llms.txt on every client domain in the first week of an engagement. Missing it is the single most common cause of a zero-score site.
Perplexity seems to be pulling from it more consistently based on how my content is being summarised in responses. What I cannot figure out yet is whether the llms.txt content is being weighted differently from the main page content or treated as one more source alongside everything else.
sitemap.xml tuned for AI crawlers (6 points). The sitemap the agent reads is the same sitemap Google reads, but it must include lastmod, changefreq, and priority on every URL, and must be referenced explicitly in both robots.txt and the Link header. Without the lastmod attribute, agents conservatively refuse to re-index the page more than once per quarter.
robots.txt posture (4 points). The robots.txt file should explicitly allow known agent user-agents (GPTBot, ClaudeBot, PerplexityBot, Google-Extended) rather than leaving them to the default. Implicit allow is scored as 2 points on the rubric; explicit allow with crawl-delay tuning is scored as the full 4.
Technical SEO for AI: Robots.txt, GPTBot & llms.txt Explained | 3.4. AEO Course by Ahrefs
Ahrefs
Ahrefs walks the Discovery layer end to end, how robots.txt, GPTBot access, and llms.txt decide whether an AI crawler treats your site as a real source.
The detail most teams miss inside Discovery is that the three files reinforce each other. An llms.txt with no corresponding sitemap.xml entries reads as fabricated to a careful agent. A sitemap.xml that lists 400 URLs with no lastmod attribute reads as static and stale. A robots.txt that blocks GPTBot by default and then publishes an llms.txt reads as contradictory. The agent resolves the contradiction by downgrading the domain. Shipping all three on the same day, with consistent canonical URLs and lastmod values that actually match the file mtimes on disk, is the difference between a 6-of-20 Discovery score and the full 20.
One additional posture choice often surfaces in audit week. Teams that host a docs subdomain (docs.example.com) frequently publish llms.txt only on the marketing root and leave the docs surface uncovered. Agents treat each subdomain as a separate origin and will index zero pages from a docs subdomain that has no llms.txt of its own. The fix is to ship a second llms.txt at the docs root, listing the API reference, the quickstart, the changelog, and the migration guides as the canonical pages. Founders who treat their docs as part of the marketing surface, not as a separate engineering artifact, pull a measurable lift in agent-cited API documentation queries within two weeks of the second file landing.
A second posture choice worth flagging is the llms-full.txt extension that several agents now read. The base llms.txt is a curated index of canonical URLs with short summaries. The extended llms-full.txt is the same index with the full markdown bodies inlined, so an agent that fetches one file gets the entire knowledge surface in one round trip. Agents that support the extension weight a domain higher because the round-trip cost of citation collapses. Across the FORKOFF audit set, sites that shipped llms-full.txt in addition to llms.txt scored an average of 4 points higher on Discovery and pulled measurably more citations in single-query agent traces. The cost is a small build step that concatenates the bodies of the canonical pages at deploy time and writes the result to the root. Once shipped, the file regenerates on every deploy and stays in sync with the canonical content.
Crawl-delay tuning is the third posture detail that compounds. The default robots.txt posture across the audit set was either no crawl-delay attribute or a crawl-delay set so high that agents treated the site as rate-limited and skipped subsequent fetches. The correct posture for a marketing surface is a crawl-delay of 1 to 2 seconds for general bots and an explicit zero crawl-delay for the four agent user-agents that drive citation volume. Agents respect the explicit zero, fetch more pages per visit, and build a richer internal model of the domain. The change costs 4 lines in robots.txt and pulls a measurable lift on the next agent re-index.

Layer 2 of 5: Trust (25 points)
The Trust layer carries 25 points split across three surfaces: Schema.org markup (12 points covering five schema types including Article, FAQ, Breadcrumb, SoftwareApplication, and Organization), well-known manifests (9 points for the MCP Server Card and six additional agent protocol files), and HTTPS and entity disambiguation signals (4 points). Most teams score well on schema surface checks but miss the well-known manifests entirely, which is the largest single-layer point gap in the audit set.
Schema.org markup (12 points). Not one schema type, five. Article schema on every blog post, FAQ schema on every post with questions, Breadcrumb schema site-wide, SoftwareApplication schema on the product pages, and Organization schema on the homepage. Each schema must validate cleanly against the 2026 Google Rich Results test and must include the id, sameAs, and url fields an agent uses to disambiguate your entity from a competitor with a similar name.
.well-known manifests (9 points). This is where the 2026 sites diverge hard from the 2022 ones. A Level 5 site serves seven files under /.well-known: the MCP Server Card, the Agent Skills Card, the A2A Agent Card, OAuth 2.0 discovery, OAuth 2.0 Protected Resource metadata, a Content Signals manifest, and an API Catalog. Each is a small JSON document that takes less than an hour to author and less than a day to validate. Missing these is the single largest point gap across FORKOFF's audit set.
JSON-LD instead of Microdata (4 points). Agents parse JSON-LD an order of magnitude faster than Microdata and with higher fidelity. Sites still using Microdata or RDFa in 2026 are scored as partially compliant and lose the top band on Trust.
A subtle pattern shows up across the 47-site audit set on the Trust layer. Teams that ship one rich schema (Article on every blog post) and skip the other four often score worse than teams that ship five thin schemas across the entire site. Agents weight schema coverage heavily because partial coverage signals that the team understands the spec and chose not to apply it, which reads as adversarial rather than uninformed. The remediation is to ship every applicable schema once, even if each schema only carries the required fields, then deepen each schema with optional fields over the following month. Breadth before depth on the Trust layer is the consistent pattern across the 7 sites that crossed 76.
The .well-known surface deserves its own paragraph because most founders have never opened the directory. The seven files map to seven different agent capabilities. The MCP Server Card tells an agent what callable operations exist on the domain. The Agent Skills Card describes named workflows composed from those operations. The A2A Agent Card publishes the contract for agent-to-agent collaboration with peers. The OAuth Discovery and Protected Resource files describe how an agent acquires the credentials it needs to call protected endpoints. The Content Signals manifest declares which content surfaces are licensed for training, citation, or summarization. The API Catalog is the machine-readable index of every OpenAPI document the domain exposes. Each file is its own JSON or YAML artifact, each one is small, and each one is independently scored. Shipping all seven is a one-week task for a single engineer.
Operator noteSeven .well-known JSON files are the biggest single-layer gap in the set. Under an hour each, and most founders never open the folder., FORKOFF Trust-layer audit

Layer 3 of 5: Action (25 points)
If Discovery and Trust make your site readable, Action makes it callable. This is the layer where the founder site stops being a brochure and becomes an operable surface the agent can invoke on behalf of its user. Three sub-scores.
MCP server endpoint (15 points). Model Context Protocol is the 2026 contract by which an agent requests a structured action from a remote service. A FORKOFF-grade implementation exposes an MCP server at /mcp that enumerates at minimum four operations: get_company_summary, list_resources, get_contact_intake, and start_audit. Each operation is defined by a JSON schema the agent reads at runtime. Teams without an MCP endpoint score zero on this band, no partial credit.
WebMCP card (6 points). The WebMCP card is the agent-side discovery manifest for your MCP server, published at /.well-known/webmcp. It is how an agent browsing your domain finds the MCP endpoint without being told in advance. Agents that land on a page with a WebMCP card auto-offer to call into the server.
Agent Skills manifest (4 points). Adjacent to the MCP card, the Agent Skills manifest describes named workflows the agent can compose from the raw MCP operations. For FORKOFF that includes run_agent_readiness_audit and generate_growth_plan. The agent reads the manifest, understands the high-level verbs, and treats your site as a tool.
The Action layer is where founder objections cluster, so a direct response is useful. The first objection is that an MCP server requires a backend the marketing team does not own. The honest answer is that a minimal MCP server is a 100-line Node, Python, or TypeScript service that returns static JSON for the first three operations and proxies a single API call for the fourth. It does not need a database, an auth layer, or a deployment pipeline beyond the one already running the marketing site. FORKOFF ships pre-launch MCP servers for clients in a two-hour pair-programming session as part of a founder funnel engagement. The second objection is that exposing a callable surface creates an attack surface. The defense is that MCP operations are scoped, rate-limited, and observable. A get_company_summary call cannot do anything an unauthenticated GET request to the homepage cannot do, and it produces structured logs the team can audit. The third objection is that the agent ecosystem is too immature to invest against. The counter is that the three agents driving most cited buyer research already speak MCP fluently. Waiting another quarter to ship the endpoint is a quarter of compounding citations forfeited to faster competitors.
A second pattern worth flagging on Action is the schema-quality gap inside the MCP server itself. Shipping an MCP endpoint that returns four operations is the floor. Shipping an MCP endpoint where every operation has a strict JSON schema with required fields, enumerated value lists, and example payloads is the bar that compounds. Agents that fetch a vague schema treat the endpoint as untrusted and fall back to scraping HTML. Agents that fetch a tight schema with example payloads call the operation directly and quote the structured response in the answer. Across the audit set, the difference between a 9-of-15 MCP score and the full 15 was almost always schema quality, not the number of operations. The remediation is to write the JSON schema for each operation with the same care a backend team writes an OpenAPI spec for a paying customer, then validate every response against the schema in CI so drift never reaches production.
The third Action detail is the WebMCP card freshness check. WebMCP cards include a last-updated timestamp that agents read to decide whether to refresh their internal cache of the MCP endpoint. Cards that ship once and never update read as stale, and agents stop calling the underlying MCP server after roughly 30 days. The fix is a build-time hook that stamps the card with the current ISO timestamp on every deploy. Sites that ship the hook see consistent MCP traffic from agents over time. Sites that ship a static card see traffic decay to near zero within a month, even when the underlying server is healthy. This is the most common silent failure mode in the Action layer and the one founders are least likely to notice without explicit monitoring.
Operator noteWebMCP cards with no build-time timestamp decay to zero agent traffic in 30 days. Stamp the ISO date on every deploy., FORKOFF Action-layer install note
Hridoy Rehman
@hridoyreh
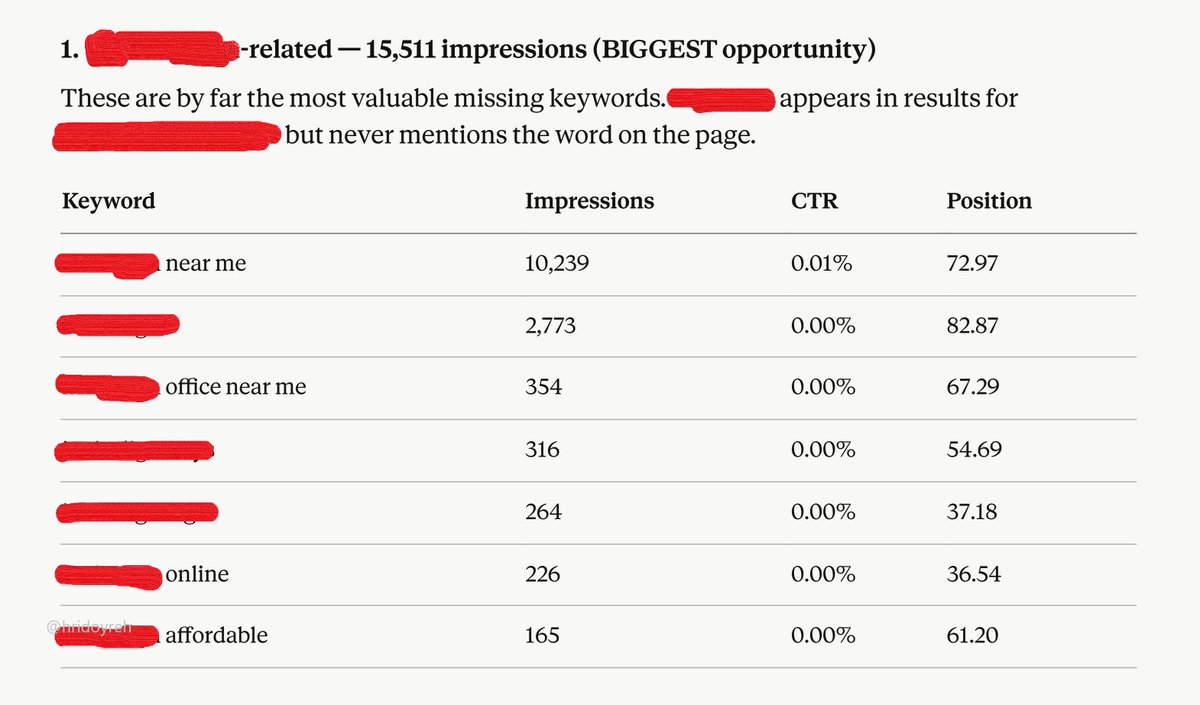
1. Go to Google Search Console. 2. Select 3 months of data. 3. Tap Pages > open any URL. 4. Download the CSV file. 5. Open Claude and upload the file. Prompt: Analyze the file and identify which keywords are not used on [that page/content URL] but are still getting a lot of imp… Show more

Layer 4 of 5: Negotiation (15 points)
Negotiation covers 15 points across two surfaces: markdown content-negotiation middleware (10 points) that responds to Accept: text/markdown headers with a clean markdown body instead of HTML, and Link headers on every HTTP response (5 points) advertising the sitemap, llms.txt, and MCP Server Card so agents can find adjacent resources without parsing the DOM. Both installs are under a day of engineering work and combined produce the largest single-sprint retention gain in the rubric.
Markdown content-negotiation middleware (10 points). Every page on the site must respond to an Accept: text/markdown header with a clean markdown body rather than HTML. Agents request markdown because it parses faster, tokenizes smaller, and quotes cleaner in a chat. A domain that only serves HTML forces the agent to do lossy HTML-to-markdown conversion on the fly and scores a flat zero here. The fix is a 40-line middleware on the edge that detects the Accept header, calls a markdownify pass, and caches the result.
Link headers for AI crawlers (5 points). Every HTTP response should include Link headers advertising the sitemap, the llms.txt, and the MCP Server Card. This is lower-cost to install and almost never done. Agents use Link headers to find adjacent resources without walking the DOM. Adding them on a Cloudflare Worker is a 5-minute change that recovers the full 5 points.
Layer 5 of 5: Retrieval (15 points)
Retrieval measures how easily an agent can quote a specific claim from your content with confidence. The 15 points split across three sub-scores: citation-friendly H-tree hierarchy with stable id attributes on every heading (7 points), FAQ schema on every long post with at least five QA pairs in the 40 to 60-word answer range (5 points), and anchor URLs that survive site redeploys without breaking existing citations (3 points).
Citation-friendly H-tree hierarchy (7 points). Every H2 and H3 needs an id attribute so the agent can anchor a citation to a stable URL fragment. Sites that render all headings as divs, or that use auto-generated ids that change on every deploy, score zero here. A stable slug derived from the heading text is the safe pattern.
FAQ schema on every long post (5 points). FAQ schema is the most overlooked high-leverage markup in 2026. Every long-form post should have a blog.faq block with at least five QA pairs, each answer in the 40-60-word range that Perplexity and ChatGPT quote cleanly.
Anchor URLs preserved on redeploy (3 points). Anchor fragments must survive site redeploys. The agent's citation is only trustworthy if the URL it quotes keeps resolving six months from now. Generating deterministic slugs and freezing them in a migration map is the fix.
The Retrieval layer is the one founders most often discover they were already half-running. Most modern static site generators emit stable heading ids by default. The gap is usually concentrated in two places. First, blog posts authored before the team adopted FAQ schema as a standard, which need a retro pass that adds five QA pairs each. Second, marketing pages that were rebuilt during a brand refresh and silently changed every anchor fragment. The retro pass takes about a day of writing time per 20 posts and a half-day of engineering time to install a redirect map. Both are worth the spend because retrieval-layer wins compound on every future citation, not just the next one.

How agents traverse the five layers in practice
Understanding what an agent actually does when a buyer pastes your domain into a chat is the missing context that makes the rubric click. The traversal sequence is consistent across Claude, ChatGPT, Perplexity, and Gemini in 2026, and it runs through all five layers in under a second.
The agent's first action is a HEAD request to the root domain. The response headers are read for Link headers advertising the sitemap, llms.txt, and MCP Server Card. The presence or absence of those headers sets the agent's initial trust posture for the entire session. The second action is a GET on /llms.txt with the Accept: text/markdown header. A clean markdown response with a structured index of canonical URLs raises the trust posture another step. The third action is a fan-out: the agent simultaneously requests /sitemap.xml, /.well-known/mcp-server, /.well-known/agent-skills, and the canonical URLs listed in llms.txt. Each response is parsed in parallel and scored on parsability and consistency. The fourth action, only triggered when the buyer's prompt asks for a callable operation, is an introspection call against the MCP server to enumerate the available operations and their JSON schemas. The fifth action is the citation pass: the agent extracts the structured claims it intends to quote, anchors each one to the H-tree fragment, and composes the response.
Two things become obvious when the traversal is mapped out. First, every layer reinforces the next, so a single failure cascades. A domain that fails Discovery never reaches Trust, because the agent decided in the first 200ms that the site was not a serious information source. A domain that passes Discovery but fails Trust gets cited as a low-confidence source with hedged language ("the company's site indicates"). A domain that passes Discovery and Trust but fails Action is cited as a brochure rather than a tool. Second, the entire traversal is observable. Founders who instrument their edge worker with per-user-agent logging can see the exact requests every major agent makes and confirm in real time that each request is returning the expected response. FORKOFF clients ship that observability layer on day one of the engagement and use the dashboard to drive the audit.
Pre-launch versus retroactive install: two different timelines
Founders fall into two cohorts depending on whether their site is already live. Pre-launch teams have the easier path because every agent-ready surface can be designed into the first build. Retroactive teams have the harder path because every surface must be added without breaking the existing routes, schema, and analytics. Both cohorts can reach Level 5 inside a month, but the sequencing matters.
For pre-launch teams, the canonical order is content first, then schema, then .well-known, then MCP, then markdown middleware, then llms.txt, then the citation anchors, then the scanner score. Content first because every other layer is a wrapper around the content. If the content is thin, no amount of schema rescues the score. Pre-launch teams who skip the content step and start with the MCP server typically launch with a 60-of-100 site that plateaus because the underlying claims are weak. FORKOFF's pre-launch engagement spends the first two weeks on positioning, claim density, and proof points before a single technical surface is touched.
For retroactive teams, the canonical order inverts. Retroactive teams start with the scanner score against isitagentready.com, then the FORKOFF audit, then a triage of the three highest-leverage layers. Almost always those three are .well-known manifests, MCP, and llms.txt, because they are the three surfaces that compound the existing content rather than rewriting it. Retroactive teams typically reach 88-94 in four weeks and use month two to lift the content layer with FAQ schema, claim density, and the docs subdomain extension covered above. The retroactive path is more total work but lower risk because the team is never down for a launch.
A subset of teams sit between the two cohorts: live sites approaching a major relaunch. The right pattern there is to install the lowest-effort layers (llms.txt, robots.txt, sitemap tuning, Link headers) on the existing site immediately, then design every remaining layer into the relaunch. Those lowest-effort layers buy citation traction during the relaunch quarter so the team is not invisible to agents during the build.

What the top 3 sites had in common across the audit set
The three sites scoring above 76 in the Q1 2026 audit shared four traits that are worth naming because they are easier to replicate than the underlying technical work suggests. The traits are operational, not technical, which is why they tend to get missed by teams focused on shipping artifacts.
First, every one of the three sites had a single named owner of agent-readiness inside the company. Not a committee, not a contractor, not a quarterly objective. One person whose calendar reserved four hours per week for the audit re-scan, the llms.txt update, the schema validation, and the MCP changelog. The other 44 sites had agent-readiness distributed across two or more functions, and the distribution itself was the source of the drift.
Second, every one of the three sites treated the scanner score as a metric, not a goal. Each team had a monthly dashboard with the score, the per-layer breakdown, the citation lift on a fixed buyer-prompt panel, and the inbound traffic share routed through AI agents. The dashboard meant the team could tell whether a score lift translated to pipeline lift, and could adjust the install priorities accordingly.
Third, every one of the three sites had an editorial calendar that fed the canonical URL list inside llms.txt. New posts were added to llms.txt within 48 hours of publication, FAQ schema was authored alongside the post draft rather than retrofit later, and the .well-known/content-signals manifest was updated quarterly to reflect new licensable surfaces. Agent-readiness was a publishing discipline, not a one-time install.
Fourth, every one of the three sites ran a monthly buyer-prompt regression test. The test was a fixed set of 20 prompts that a target buyer might paste into Claude, ChatGPT, or Perplexity. Each prompt was run against each agent, the citation count and the quoted claims were logged, and any regression triggered an audit. The discipline is closer to backend monitoring than to traditional marketing analytics, which is why most teams do not run it. The teams that do compound far faster than the teams that do not.

What the rubric does not score and why it still matters
Five layers and 100 points cover the technical surface. The rubric does not score three softer signals that the FORKOFF audit set surfaced as consistent predictors of agent citation lift, and the gap is worth naming because founders who score 88 on the public rubric and still see no citation lift usually have one of these three gaps.
The first uncovered signal is author identity. Agents weight content by the verifiability of the byline. A post attributed to a named author with a personal X handle, a public GitHub, and a consistent profile across the web is treated as a trusted source. A post attributed to a generic "team" account with no resolvable identity is downgraded. The fix is to publish a Person schema for every author, link the schema sameAs to the author's public profiles, and reference the author by name in the article body. Sites that ship Person schema for every byline pull a measurable lift in citation rate even when the rubric score is unchanged.
The second uncovered signal is freshness signaling. The lastmod attribute on the sitemap and the dateModified field on Article schema both tell agents when a page last changed. Pages where dateModified lags publishDate by more than 90 days are quietly downgraded as candidate citations because the agent assumes the content is stale. The fix is to update dateModified on every meaningful edit and to run a quarterly content sweep that touches every canonical page and updates the timestamp. The work is small. The lift on citation rate over a six-month window is large.
The third uncovered signal is internal-link density on the agent's preferred topology. Agents traverse a domain by following internal links and weight pages that have many incoming internal links as more authoritative. The 22-of-100 sites in the audit set averaged 1.4 incoming internal links per page. The 71-of-100 top-quartile sites averaged 4.6. The remediation is to ship a hub-and-spoke architecture where every spoke post links back to its pillar and every pillar links forward to every spoke, then audit every long-form post quarterly to add 3 to 5 contextual internal links that did not exist when the post first shipped. The agent sees a denser graph, weights every page more heavily, and cites with confidence.
The combined effect of fixing the three uncovered signals on top of a 88-of-100 rubric score is what separates a site that scores well on a scanner from a site that actually gets cited by Claude, ChatGPT, and Perplexity in the buyer prompts that move pipeline. The scanner is a necessary floor. The three soft signals are the ceiling that founders cross when they want the rubric to translate into revenue.

How we install the scorecard with founder teams
Every FORKOFF agent-readiness engagement starts with a scan against isitagentready.com and a manual FORKOFF audit that extends the public rubric with four internal checks the scanner misses (citation-survivability, MCP schema quality, WebMCP freshness, FAQ schema density). We score the site, name the three highest-leverage layers, and ship a week-one install plan.
Week one closes Discovery (llms.txt, sitemap tuning, robots posture). Week two closes Trust (schema suite.well-known manifests). Week three closes Action (MCP endpoint, WebMCP card, Agent Skills manifest). Week four closes Negotiation and Retrieval together, because the markdown middleware and the citation anchors ship from the same edge worker. By end of month one, a site that started at 22 typically lands at 88 to 94, and the remaining 6 to 12 points are style-score bonuses earned in month two.
For the operator context behind this motion, two related FORKOFF reads: the Agent-Native GTM Founder Stack covers the broader stack an agent-native team runs, and the AI Marketing Verification audit covers the trust half that compounds after the site is agent-ready. For a distribution surface that compounds inside an agent-native workflow, see the AI DevRel Playbook. For AI-native outreach that pairs with an agent-ready site, see the Reddit Intent Engine. For the content-metric side of an agent-native motion, see the Qualified Views metric, and for the fund-backed variant of the same stack, see the VC Portfolio GTM Playbook. The full Founder Growth hub has the rest.

The 4 mistakes that make an agent-ready install fail
Across 47 FORKOFF audits in Q1 2026, six mistakes showed up repeatedly when a site believed it was agent-ready and failed the actual citation test: shipping schema that passes Google Rich Results but fails Claude or ChatGPT's internal parsers, publishing llms.txt once and letting it drift out of sync with new content, skipping the MCP endpoint on the assumption that early-stage products do not qualify, treating the scanner score as the goal rather than testing real buyer prompts, authoring loose MCP JSON schemas without enumerated values, and forgetting to update dateModified after content edits.
- Shipping schema without validating it against 2026 agent parsers. Validators that pass Google Rich Results do not always pass Claude or ChatGPT's internal parsers. Run every schema through all three and fix the parser-specific warnings.
- Publishing llms.txt once and letting it rot. llms.txt is a living document. Add every new canonical page to it within 48 hours of publish, or agents will refuse to cite pages they cannot find in the index.
- Skipping the MCP endpoint because the product is early. Even a pre-launch product can ship an MCP server with four operations. An agent that finds a callable endpoint trusts the domain categorically more than one that finds a contact form.
- Treating the scanner score as the goal. The scanner is a proxy. The goal is that Claude, ChatGPT, and Perplexity cite you cleanly in a real buyer conversation. Test that with five buyer-style prompts a month and iterate.
- Authoring the JSON schemas on the MCP server in a hurry. Loose schemas with no enumerated values and no example payloads cause agents to skip the operation entirely, which produces zero observable errors and zero citation lift. The schema work is the long pole on Action, not the endpoint plumbing.
- Forgetting to update dateModified after a content edit. A post that ships an updated body but keeps the original dateModified reads as stale to an agent that fetches it for citation. Every meaningful edit must touch both the body and the timestamp. Treat dateModified as a required commit field, not a generated artifact.
The Bottom Line
AI agents pre-filter your site before a buyer ever sees it. The median founder site scores 22 out of 100 on the 2026 agent-readiness rubric and loses deals it never knew it was in. The fix is a rubric, not a rebuild. Five layers, one hundred points, four weeks of focused install work to land between 88 and 94, and a monthly re-scan to hold the score.
Most teams will find three layers they should already be running and are not. The point is to score the site, install the gaps, and test against real buyer prompts, not to theorize about agent behavior for another quarter.
If you want the FORKOFF audit run for you, that is what we do.
For the live operator chatter on this exact topic, see the original Hacker News thread.
For an external operator view on this, see the Addy Osmani YouTube channel for the structural-readiness toolkit context. Related FORKOFF reads: agent-native GTM stack, AI DevRel playbook, Founder Funnel OS, VC Portfolio GTM, Agent-Ready Site Audit. References: Schema.org, Reddit.
For the full picture, see the founder-led growth playbook.
For deeper cross-pillar context, see how the Qualified Views metric earns AI Overview citations.
llms.txt is live on my site. three weeks in.what I actually noticed :
I implemented llms.txt after seeing cloudflare and hubspot had already done it. the idea made sense and it gives AI crawlers a cleaner structured version of your content rather than making them parse the full site. early data from some brands showed traffic increases within weeks. three weeks in my… Show more


![How to Make a Launch Go Viral on X: The 5-Lever Playbook [2026]](/blog/covers/how-to-make-launch-go-viral-on-x-2026-cover.jpg)










