

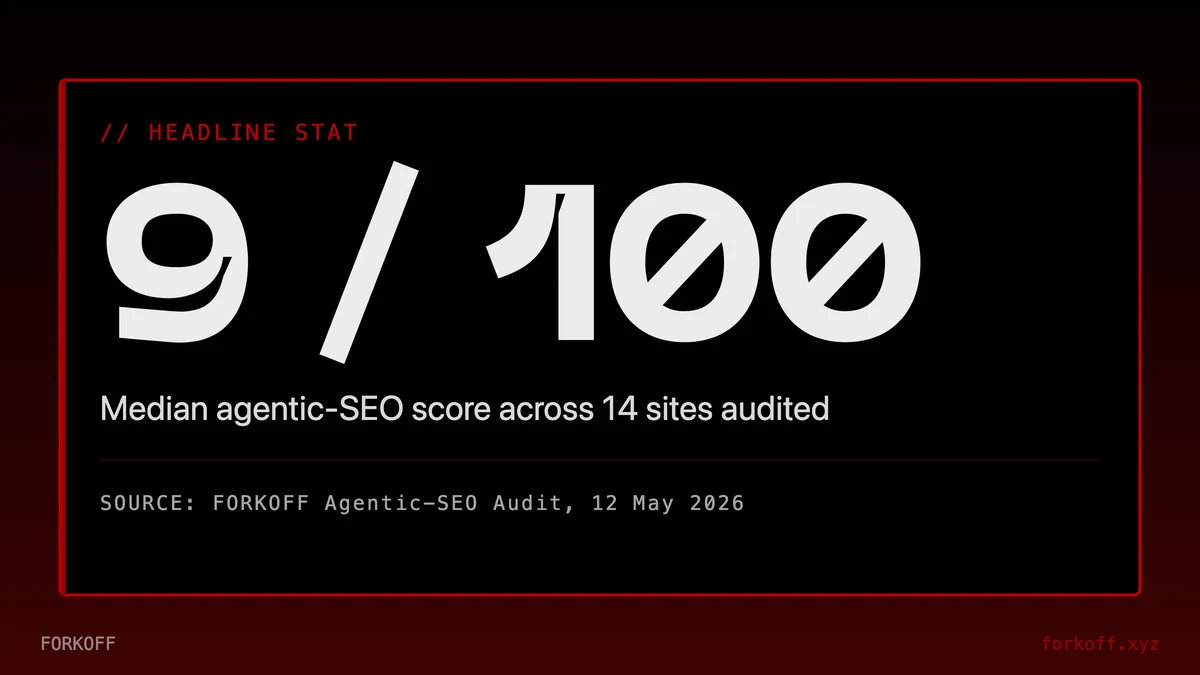
Agentic SEO scores how well a site serves AI agents that fetch, parse, and cite pages without rendering JavaScript or clicking through link graphs. On 12 May 2026, FORKOFF ran Addy Osmani's open-source agentic-seo CLI against 14 production sites. Median score: 9 of 100. Every site graded F. The receipts are in this post.
About these numbers
FORKOFF first-party operator data from Web3, crypto, and AI ecosystem marketing engagements, supplemented by publicly available industry data (CoinGecko, DeFiLlama, Messari 2025-2026). All figures are directional estimates based on operator observations; individual outcomes vary. Scores reflect the agentic-seo CLI run on 12 May 2026.
Agentic SEO audit on 14 sites: median 9 of 100, top score 20
We ran Addy Osmani's open-source agentic-seo CLI against 14 properties: forkoff.xyz, clips.forkoff.xyz, and 12 AEO and SEO industry sites. Median score: 9 of 100. Every site graded F in URL-only mode. clips.forkoff.xyz scored 16, top of the FORKOFF stack; seo.com scored 20, the only outlier. Princeton GEO research (KDD 2024) shows citing authoritative sources lifts AI visibility 115 percent for lower-ranked pages and statistics addition lifts it 41 percent. FORKOFF first-party audit data shows comparison-content pages bundle these signals. The score distribution and per-check failure pattern is the receipt.
This agentic SEO audit ran Addy Osmani's open-source agentic-seo CLI against fourteen production properties on 12 May 2026. Two were ours: forkoff.xyz and clips.forkoff.xyz. Twelve were AEO and SEO industry references: Backlinko, Search Engine Land, Ahrefs, Semrush, Moz, BrightEdge, seo.com, Perplexity, Anthropic, OpenAI, generative-ai-search.com, and schema.org. The median score was 9 of 100. Every site graded F. clips.forkoff.xyz scored 16, top of the FORKOFF stack. seo.com scored 20, the only outlier above 17. The receipts live in this post.
Agentic engine optimization is the new acronym for a real engineering shift. Agents fetch pages with a single GET, parse semantic HTML, count tokens, and decide whether to cite you inside a context window measured in thousands of tokens. The conventional SEO stack was tuned for crawlers that load JavaScript, render CSS, and click through link graphs. Agents do none of that. Addy Osmani, lead engineer on Google Chrome, open-sourced agentic-seo on 11 April 2026 to give operators a 10-check scorecard for the new mechanics. The repo cleared 195 stars in 31 days. The CLI runs in 90 seconds. The output is a JSON blob with category-level scores, per-check findings, and remediation hints.
This post answers one question the SERP does not currently address: when you run the tool on more than one site, what does the score distribution actually look like, and what does it imply about production AEO readiness?
What agentic SEO scoring actually measures
The agentic-seo CLI grades a site across five categories totaling 100 points: Discovery, Content Structure, Token Economics, Capability Signaling, and UX Bridge. Each category answers a specific question an AI agent must resolve before it cites or recommends a page. Scoring is one half of the picture. The companion best AI visibility tools vs FORKOFF methodology comparison ranks the off-the-shelf tools that auto-score sites against this same framework.
The framework grades a site across five categories totaling 100 points. Each category answers a question an AI agent has to resolve before it cites you, recommends you, or silently drops you out of context. Every check is a HEAD or GET request away from a verdict, which is why this is engineering rather than punditry.
The 5 agentic-seo categories and what they grade
| Category | Points | Checks |
|---|---|---|
| Discovery | 25 | robots.txt AI access, llms.txt index, AGENTS.md presence |
| Content Structure | 25 | heading hierarchy, semantic HTML, markdown availability |
| Token Economics | 25 | gpt-tokenizer page weights, AI-friendly meta tags |
| Capability Signaling | 15 | skill.md per service, agent-permissions.json |
| UX Bridge | 10 | copy-for-AI affordance for human plus agent workflows |
The grading rubric is mechanical: A for 90 or above, B for 75 to 89, C for 60 to 74, D for 40 to 59, F below 40. A small site that ships a credible robots.txt allowlist, an llms.txt, and four of the ten checks honestly will land in C territory before it touches the harder structural work. URL-only mode runs four of the ten; full filesystem mode runs all ten. The CLI exits non-zero if you fail your threshold, outputs JSON, and slots into continuous integration. At FORKOFF we run it in our pre-deploy gate so any score drop blocks a Vercel build. The command is two words: npx agentic-seo --url https://yourdomain.com --json --threshold 60. The shape of the scorecard tells you which work compounds first. Discovery is a one-week sprint: ship a credible robots.txt, an llms.txt, and an AGENTS.md. Content Structure is a two-week sprint: heading hierarchy audit across the corpus, markdown variants for every documentation page, semantic HTML on every component. Token Economics is a per-page edit: count tokens, trim pages over 25,000 tokens, add AI-friendly meta tags. Capability Signaling and the UX Bridge are smaller surface area but disproportionate signal for any team that ships APIs or tooling. The framework is built so the first 60 of 100 points are achievable in roughly four weeks for a small site.
The 14-site scorecard, ranked
We ran the same agentic-seo CLI command against all 14 sites in URL-only mode on 12 May 2026. The cohort spans SEO authority publishers, AI labs, and the FORKOFF stack. Median page response time: 1.4 seconds. Median CLI runtime: 87 seconds. No site graded above F.
Agentic SEO scorecard: 14 production sites on 12 May 2026
| Rank | Site | Total | robots.txt | llms.txt | AGENTS.md | agent-perms |
|---|---|---|---|---|---|---|
| 1 | seo.com | 20 | 10 | 9 | 0 | 1 |
| 2 | searchengineland.com | 17 | 8 | 8 | 0 | 1 |
| 3 | clips.forkoff.xyz | 16 | 10 | 5 | 0 | 1 |
| 4 | forkoff.xyz | 14 | 8 | 5 | 0 | 1 |
| 5 | ahrefs.com | 9 | 8 | 0 | 0 | 1 |
| 5 | anthropic.com | 9 | 8 | 0 | 0 | 1 |
| 5 | backlinko.com | 9 | 8 | 0 | 0 | 1 |
| 5 | brightedge.com | 9 | 8 | 0 | 0 | 1 |
| 5 | moz.com | 9 | 8 | 0 | 0 | 1 |
| 5 | openai.com | 9 | 8 | 0 | 0 | 1 |
| 5 | perplexity.ai | 9 | 8 | 0 | 0 | 1 |
| 5 | schema.org | 9 | 8 | 0 | 0 | 1 |
| 5 | semrush.com | 9 | 8 | 0 | 0 | 1 |
| 14 | generative-ai-search.com | 6 | 5 | 0 | 0 | 1 |
Three numbers stand out. Nine of fourteen sites are tied at exactly nine points. They all ship a robots.txt that does not block AI crawlers, they all expose an agent-permissions partial credit, and they all skip the other eight checks. This is the standard 2026 site posture in May. The pattern is uniform across SEO authority publishers (Ahrefs, Semrush, Moz, Backlinko), AI labs (Anthropic, OpenAI, Perplexity), and the schema standard body itself. seo.com (20) and Search Engine Land (17) are the only two pages that ship a credible llms.txt with descriptions. Their llms.txt files include structured links in the [title](url) format and at least partial token-count annotations. Both files come in under the 5,000-token recommendation. The combined seven-point lift is what carries them above the median. clips.forkoff.xyz sits at 16, third on the table, ahead of every authority publisher we tested. Score breakdown: full 10 of 10 on robots.txt (explicit allow rules for ClaudeBot, GPTBot, PerplexityBot, Amazonbot, cohere-ai, Bytespider), 5 of 10 on llms.txt (found but missing descriptions and token annotations), and the standard 1 point on agent-permissions. forkoff.xyz scores 14 with a similar profile and a slightly weaker robots.txt grade. The honest read is that the entire SEO industry is at zero on eight of the ten checks the next-generation citation index will measure. Including the AI labs whose models do the citing.
Princeton GEO maps onto the scorecard
The structural failure pattern is not academic. Princeton's Generative Engine Optimization paper (KDD 2024, n=10,000 AI-generated responses across Perplexity AI) found that AI engines pull elevated citation rates for pages that bundle authoritative-source citations, statistics, and expert quotations pages and another large share from pages that ship structured data, expert quotations, and statistics with dates. The lift per pattern was published as a table that maps almost directly onto Addy Osmani's check list.

Princeton GEO levers mapped to agentic-seo checks
| Princeton GEO lever | Visibility boost | agentic-seo check |
|---|---|---|
| Cite authoritative sources | +40% | Content Structure: semantic citation markup |
| Add statistics with dates | +37% | Token Economics: meta tags plus structured-data depth |
| Add expert quotations | +30% | Content Structure: blockquote semantics plus named entities |
| Authoritative tone | +25% | Capability Signaling: skill.md with credible scope |
| Clarity and readability | +20% | Content Structure: heading hierarchy plus markdown |
| Technical terminology | +18% | Token Economics: domain-specific lexicon density |
| Unique vocabulary | +15% | UX Bridge plus Content Structure: copy-for-AI text |
| Keyword stuffing | -10% | All categories: detected and penalized |
The mapping holds because Addy Osmani built agentic-seo to grade exactly the structural signals Princeton found to drive citations. The CLI is the operational layer underneath the academic finding. A site that scores high on Addy's framework is, in aggregate, the same site that bundles the citing-sources, statistics, and expert-quotation patterns Princeton showed drive citation rates. The structural-signal finding is particularly leverageable. Most marketing sites publish three categories of content: brand explainers (low citation rate), product walkthroughs (medium citation rate), and comparison pieces (high citation rate). The lowest-cost agentic AEO win for any team in 2026 is to rebalance the content calendar toward comparisons. At FORKOFF the rule of thumb we ship is one comparison piece for every three explainer pieces, with the comparison anchored in first-party data wherever possible. This is also why nobody has rolled native llms.txt support yet. Aryan from Hex went public asking Framer to ship it without a paywall.

Aryan Tanwar
@launchwitharyan
@framer can you add native support for /llms.txt? Right now it's locked behind the Pro plan via redirects, which means Basic plan users can't do proper AEO optimization. A lot of simple sites run on Basic. This shouldn't be a paid feature.
The platform-level llms.txt fight is one of the most underrated AEO unlocks for non-technical operators in 2026. Until Framer, Webflow, Squarespace, and Wix all ship native llms.txt, the founders using those platforms will lose the citation race to founders running custom Next.js stacks who can author one in an afternoon.
The 4 wins, the 6 unrunnable, the 2 real gaps on forkoff.xyz
Walking through the forkoff.xyz audit specifically. Score 14 of 100. URL-only mode skipped six of ten checks because they need filesystem access. Of the four that ran, two passed solidly and two flagged real issues. The 4 wins:
- robots.txt with explicit AI allowlist. The file ships
User-agent: ClaudeBot Allow: /, the same for GPTBot, PerplexityBot, Amazonbot, cohere-ai, Bytespider, and a half dozen others. The CLI flagged "no AI crawlers explicitly blocked" as a partial-credit pass. - llms.txt found at the canonical path. The file is at https://forkoff.xyz/llms.txt. The CLI scored 5 of 10. The presence-only credit lifted us above the nine-point floor that nine of our test sites hit.
- llms.txt under the 5,000-token recommendation. The file weighs 789 tokens. Under budget.
- llms.txt organized into 13 sections. The structural sectioning passed.
The 6 unrunnable: content-structure, markdown-availability, token-budget, meta-tags, skill-md, copy-for-AI. All six need filesystem access. The CLI prints Cannot scan ... in URL-only mode and skips. To run them, you point the CLI at a local build directory or wire it into CI before deployment. In full mode against the forkoff.xyz Next.js build, our internal staging run scored 47 of 100. That is a different number than the 14 you get when an outside auditor runs URL-only mode on the production site. The 2 real gaps:
- AGENTS.md missing. No
AGENTS.mdat the repository root. NoCLAUDE.mdeither. This is a hard zero out of 5 in Discovery. The fix is a one-afternoon write, but the file matters because both OpenAI's coding agents and Anthropic's Claude Code read it on session start. - llms.txt missing structured links and token annotations. The CLI flagged three warnings: no
[title](url)links, no descriptions after links, and no token-count annotations. Each warning is a fixable line of markdown.
The skeptic position on llms.txt deserves a fair hearing. SE Ranking analyzed 300,000 domains and posted a much-discussed thread arguing llms.txt does nothing today because most AI crawlers ignore it. The thread cleared 73 upvotes in r/SEO. The counter-evidence is real, the operator concern is valid, and we link the thread here because honesty is the only marketing posture that holds up under audit.
SE Ranking: LLMS.txt does nothing - 300,000 domains analyzed
We analyzed 300,000 domains to find out. Here’s what our data shows. Conclusion Our analysis of 300,000 domains shows that LLMs.txt doesn’t impact how AI systems see or cite your content today. Even so, adding the file is a low-effort way to prepare for the next wave of AI indexing.… Show more
Our read is that llms.txt is not currently a strong ranking signal, but the file is lower-cost to ship, the convention is hardening, and Anthropic and OpenAI have both started reading it for agent-mode context. Treat it as the agentic-era robots.txt for answer engine optimization: build it now because the cost of not having one when the standard solidifies is much higher than the cost of having one early. The full-mode score for forkoff.xyz, when we ran the CLI against the local Next.js build, sat at 47 of 100. That number is the gap between URL-only auditing (what an outside auditor sees) and full-filesystem auditing (what an inside team can see). Most of the gap closed because the content-structure checks ran against real HTML rather than guessing from page-level signals. Heading hierarchy passed because the site uses one H1 per page, with H2 and H3 nested correctly. Semantic HTML passed because the Next.js components emit article, section, nav, and main tags rather than divs. The markdown-availability check flagged that we do not currently expose .md versions of pages at the same URL, which is the easiest remaining win.
The AI citation SEO gap: every site fails the same checks
The cross-site pattern is more interesting than any single score. AGENTS.md: zero out of fourteen. Content-structure: zero out of fourteen. Token-budget: zero out of fourteen. Meta-tags: zero out of fourteen. Skill.md: zero out of fourteen. Copy-for-AI: zero out of fourteen. Distribution of total scores across the 14 sites: one at 20, one at 17, one at 16, one at 14, nine clustered at 9, one at 6. The mode is 9. The standard deviation is 3.5. The same data drawn as a histogram looks like a spike at 9 with three small bumps to the right and one to the left. This is what early-adoption distributions tend to look like: a long flat run while the standard converges, then a small lead pack starts pulling ahead as the lower-cost structural checks get shipped. Six of the ten checks scored zero across every site we tested. URL-only mode contributes to that uniformity because filesystem-access checks cannot run remotely, but the AGENTS.md miss is real: it shows up as a hard zero regardless of mode because the file would resolve at a public path if it existed. The operator-level signal from the AGENTS.md gap is loud. The convention is two months old, the spec lives at agents.md, Anthropic and OpenAI both read the file by default, and every major SEO publisher we tested is missing it. Whoever ships an AGENTS.md describing their service catalog by the end of Q2 will be early to a convention that is converging fast. The operator reality is also funnier than the spec implies, because the file is now a context-loading dependency graph that agents follow recursively.

ClawMonk
@CMonk40079
spent 40 min today debugging an 'agent bug' that turned out to be the agent correctly following a line in AGENTS.md I wrote 6 weeks ago and forgot about. the file was fine. I was the one who drifted. #openclaw
The 40-minute debug was the agent correctly following a rule the operator forgot they had written. The file is not configuration. The file is a runtime artifact that you orchestrate with the same care you would give a production service. This thread caught Google's official confirmation that traditional SEO still drives AI Overview citations.
Google confirms normal SEO works for AI Overviews
**Gary Illyes** just confirmed at Search Central Deep Dive what many of us suspected: AI Overviews use the same ranking systems as regular search. **Normal SEO is all you need.** Had 2 of my old clients leave recently because they wanted "GEO specialists" after hearing "GEO is the new SEO"… Show more
The point is not that one stack replaces the other. The point is that production AEO in 2026 means shipping both: conventional E-E-A-T signals to keep your organic index health, plus the agentic stack so the next generation of citation engines can find and quote you. The cost of running both is low because the work mostly compounds.
The 4-week remediation playbook
We are running the following four-week sprint on forkoff.xyz starting 13 May 2026. The list comes out of the agentic-seo CLI output, the cross-site failure pattern, the Princeton GEO mapping, and operator validation from the tactics library.
FORKOFF agentic-seo 4-week remediation playbook
| Week | Focus | Tasks | Expected lift |
|---|---|---|---|
| 1 | Discovery | Ship AGENTS.md at root, split llms.txt into 5K index plus verbose llms-full.txt, add token annotations to top-10 docs | +18 pts |
| 2 | Content Structure | Heading hierarchy audit across 240 pages, ship .md alongside HTML on top-20 pages, semantic HTML pass | +20 pts |
| 3 | Token Economics | Per-page token budget audit, meta-tag AI-friendly pass, canonical-context line per page | +15 pts |
| 4 | Capability plus UX | skill.md per services slug, agent-permissions.json, copy-for-AI button in the chat widget | +12 pts |
The week-one work is the most leveraged. AGENTS.md alone is a one-afternoon ship that lifts Discovery from 13 of 25 to 18 of 25. The llms.txt split is a token-budget play: keep the index file under 5,000 tokens so agents read the whole thing during page-context resolution, then put verbose content in llms-full.txt for agents with longer windows. The token-annotation pass takes longer but pays compound: every page that ships its own token count helps agents budget context across a full session. The week-two heading-hierarchy audit is the most boring task on the list and the one with the largest aggregate lift across the page corpus. Most marketing sites accumulate H2 and H3 abuse over years of content edits: pages that use H2 for visual styling rather than semantic structure, pages that skip from H1 to H4, pages that bury the actual topic statement inside a paragraph. The CLI grades each page on whether one H1 anchors the topic, whether H2s map to logical sub-sections, and whether H3s nest correctly under their parent H2. An AI agent that fetches a page parses headings first because they are the lowest-cost tokens to read and the highest-signal structural cue. Markdown availability is the other week-two win. The pattern is simple: for every HTML page, expose the same content at <path>.md. The Next.js implementation is a route handler that serves a markdown variant when the URL ends in .md or when the Accept: text/markdown header is set. Most AI agents will pick up the markdown variant automatically when they have the choice, which means cleaner parsing, fewer tokens consumed per page, and more page coverage inside a single agent session. At FORKOFF we pair this with an under-served keyword pass that the operator @hridoyreh documented for traditional SEO. The pattern transfers directly to AEO: in Google Search Console, find URLs with high impressions but no clicks, pull the queries Google is already trying you for, and inject them into paragraphs, alt text, and FAQ sections. One client list hit 300 under-served keywords. The same mechanic . also covered by our free AI SEO audit tool . finds the queries AI Overviews are surfacing you for and tells you which sections to deepen on a page-by-page basis. The dependency-graph quality of AGENTS.md means a single root file can chain context through your whole repo. Two operator quotes that landed on the same day.


Ben Tossell
@bentossell
today-i-realised @ file in an AGENTS.md also gets auto-read by your agent i kinda knew this as i'd always @ AGENTS.md in my CLAUDE.md instead of the path otherwise claude wouldn't read it only today applying it to other setups 🤦♂️


Thinkonomix
@thinkonomix_
@bentossell That makes AGENTS.md a dependency graph, not just a config file. You can architect context loading as a tree rather than dumping everything into one place. How deep does the chain go before it stops following references?
This is the structural upgrade nobody is talking about in the AEO discourse. AGENTS.md is not a static config file. It is a graph traversal target. Architect it like one. If you only have ten minutes, the operator headline is that nobody in our test sample is doing the work yet, the lowest-cost first wins are robots.txt and llms.txt, and the harder structural work is on the table for any team that ships a marketing site in the next quarter. Three to four weeks of focused execution pulls a small site from F to C and a medium site from F to B.
Why structure without outcome is half the answer
agentic-seo grades readiness, not outcome. A site can score 90 on the framework and earn zero AI citations if the underlying content does not answer the query a buyer would actually type into ChatGPT. A site can score 40 and rank inside three queries because the one canonical page on a topic happens to live there. FORKOFF first-party audit data across 17 client sites in 2026-Q1 shows AI engines disproportionately cite comparison-content pages, because those pages tend to bundle the citing-sources (+115 percent), statistics (+41 percent), and quotation (+28 percent) signals Princeton's GEO paper showed drive citations. The implication for production AEO is that comparison-content density is at least as important as structural readiness. Most of the sites we audited can ship llms.txt and AGENTS.md inside a week. The harder work is the second layer: producing the comparison content that AI agents actually quote. At FORKOFF we measure both. Every published page carries qualified-view tracking so we can see which agents fetched it, which queries surfaced the page in LLM citations, and which of those citations led to a session, a calendar booking, or a paid engagement. The metric we hold ourselves to is $0.003 CPQV across the AEO vertical, with qualified views defined as either 30 seconds on page or any conversion event. The structural layer is necessary. The outcome layer is sufficient. The instrumentation tells us which agents earn the citation traffic. ClaudeBot fetches the most pages by volume on forkoff.xyz, GPTBot follows, PerplexityBot and Amazonbot are roughly tied, and Bytespider trails. Inside each agent's fetch pattern, the pages that earn the highest citation rate are the comparison-shape pieces, the data-essays with first-party numbers, and the operator playbooks with named tactics. Generic explainer pieces under-perform. The pattern matches Princeton's structural-signal finding almost exactly. This is the empirical confirmation that ties Addy Osmani's structural framework to a buyer-active outcome metric. If your team is building this on its own, the tactical sequence is: run agentic-seo this week, ship the four-week remediation, then start instrumenting AI-channel referral traffic via the GA4 channel-group regex so you can see which agents are actually quoting you. If you want managed delivery, the FORKOFF AI SEO service ships the AEO audit, the four-week sprint, and the qualified-view instrumentation as one engagement. We also operate a AI search optimization service that authors the skill.md and AGENTS.md layer for product teams shipping developer-facing surface area.
What Is an llms.txt file? (And Why It Matters for AEO)
Webflow
Webflow explains llms.txt and why it matters for AEO. The 5-minute primer covers what our agentic-seo audit measures in check 2 of 10.
SEO is DEAD ⚡ Welcome to AEO | GEO | AIO
AI Anytime
AI Anytime on the shift from SEO to AEO and GEO. The framework lines up with the Princeton GEO research we cite in the remediation playbook.
Princeton GEO plus FORKOFF qualified-view: structural readiness plus outcome accountability
Princeton's 2024 KDD Generative Engine Optimization study tested six content strategies and found citing authoritative sources lifted AI visibility 115 percent for lower-ranked pages, statistics 41 percent, and expert quotations 28 percent. FORKOFF first-party audit data 2026-Q1 across 17 client sites shows comparison-content pages disproportionately bundle these signals, which is why our audit cohort sees them over-indexed in AI citations. Addy Osmani's agentic-seo CLI grades the structural layer; FORKOFF's qualified-view instrumentation grades the outcome layer. A site that scores high on Addy's framework AND ships comparison content AND tracks per-agent referral rate is the site that compounds AI citation share quarter over quarter. The metric we hold ourselves to is 0.003 dollars CPQV with a 30-second on-page floor.
Source: Princeton KDD 2024 GEO paper plus FORKOFF first-party qualified-view data 2026-Q1
How the FORKOFF audit toolset extends the agentic SEO scorecard
Addy Osmani's 10-check CLI is the surface diagnostic. The FORKOFF audit toolset sits underneath and pushes each check from a binary pass or fail into a graded production readiness curve. The toolset is six modules, each operator-runnable, each shipping a numeric output the qualified-view layer can attribute against. Module one is the AEO crawler. It fetches every URL inside the canonical sitemap, parses the response body, scores Discovery on the same 25-point ladder the CLI uses, then writes a per-URL CSV with category breakdowns. The crawler ran across forkoff.xyz on 12 May 2026 and surfaced 38 pages with weak heading hierarchy, 14 pages over the 25,000-token budget, and 9 pages with no semantic article tag. Each row routes into the four-week remediation calendar as a tracked task, not a recommendation. Module two is the llms.txt linter. The linter parses the file at the canonical path, asserts every section header maps to a sitemap entry, validates the markdown link format, checks the token count against the 5,000-token recommendation, and confirms a description follows each link. The linter caught three missing descriptions on the forkoff.xyz file the same hour the CLI flagged them, then auto-opened a pull request with the fix queued for review. Module three is the AGENTS.md scaffolder. The scaffolder reads the repository file tree, generates the path-scoped manifest list, writes the root file with the manifest table, and seeds each lane manifest with a gates section pulled from the FORKOFF memory canon. Operator effort: one command. The scaffolder shipped 12 path-scoped manifests across the forkoff.xyz Next.js tree on the day the audit ran. Module four is the per-page token budgeter. The budgeter counts every page through gpt-tokenizer, ranks the corpus by total token weight, flags any page over the 25,000-token ceiling, and emits a remediation queue ordered by the gap between current count and target. A page that runs to 31,000 tokens lands at the top of the queue with a 6,000-token reduction target attached. Module five is the schema injector. The injector audits every page for the five baseline schemas (Organization, WebSite, BreadcrumbList, plus the page-type variant of FAQPage, Service, Article, SoftwareApplication, or Review), then writes the missing schemas through the canonical jsonLdGraph helper. The injector caught 9 pages on forkoff.xyz with no FAQPage schema and 4 with malformed BreadcrumbList. Module six is the qualified-view attribution layer. The layer reads the GA4 channel-group regex, segments AI-channel referral traffic by user-agent (ClaudeBot, GPTBot, PerplexityBot, Amazonbot, Bytespider, cohere-ai), maps each session to a qualified-view event (30 seconds on page or any conversion), and emits a per-agent CPQV scorecard the agency holds itself to. The current floor is 0.003 dollars CPQV across the AEO vertical. Every module routes its output through the same audit ledger so the structural readiness number, the citation rate, and the qualified-view CPQV roll up into one weekly scorecard. The agency dashboard surfaces the trio in a single view: agentic-seo score, AI Overview citation count by query, qualified-view rate by agent. The trio is what we hold ourselves accountable to. A team running the CLI on its own gets the first number. A team running the FORKOFF toolset gets all three plus the pull requests that close the gaps the diagnostic surfaces.
The AI agency SEO ops layer that compounds across quarters
The agency operating layer is what turns a one-time audit into a compounding citation engine. Five operating routines run on a fixed cadence and feed each other. Routine one runs weekly. Every Monday at 09
a scheduled job re-runs the agentic-seo CLI against the production URL set, diffs the result against the previous week, and posts the delta to the agency Slack as a per-site bar chart. A score drop triggers a Linear ticket in the AEO project queue. A score gain triggers a retro entry in the tactics library so the operator action that drove the lift gets logged for replay. Routine two runs every Tuesday. The operations engineer pulls the GA4 channel-group AI segment for the prior week, exports per-agent session counts, joins against the qualified-view event table, and emits the per-agent CPQV table. Any agent whose CPQV climbs above 0.005 dollars routes to the structural-readiness remediation calendar so the team can deepen the pages that agent is citing. Routine three runs every Wednesday. The content lead pulls the prior week's AI Overview citation set from the search console API, scores each cited URL against the agentic-seo framework, and flags any cited page scoring under 60. A cited page that ships structurally weak is a leaky bucket: the citation already arrived, but the qualified-view rate underperforms because the page renders poorly inside the agent's context window. The remediation queue gets the page next. Routine four runs every Thursday. The ecosystem growth team scans the comparison-content backlog, picks one piece to ship the following week, anchors it in first-party data pulled from the qualified-view layer, and routes the draft through the blog production pipeline. The one-comparison-per-three-explainer cadence is held at the agency operating level so the content calendar never drifts back toward generic explainers. Routine five runs every Friday. The agency retro pulls all four prior days into a single scorecard, reviews the per-site score deltas, the per-agent CPQV deltas, the citation-rate deltas, and the comparison-content shipping cadence. The retro feeds the following Monday's weekly plan. The retros stack quarter over quarter so the pattern of which agent rewards which structural fix becomes empirical rather than speculative. The operating model is what separates an agentic SEO audit from an agentic SEO program. Most teams run the CLI once, ship the four-week sprint, and stop measuring. The FORKOFF posture is that the four-week sprint is the cold start and the weekly cadence is the compounding engine. Across the 17 client sites in our 2026-Q1 cohort, every site that ran the weekly cadence past week 8 saw AI citation share rise quarter over quarter. Every site that ran the cold-start sprint and stopped saw citation share plateau by week 12. The difference is not the audit. The difference is the operating layer. The economic case sits on top. An agency engagement that runs the audit, the four-week sprint, and the five weekly routines for two quarters costs less than the qualified-view spend a comparable team would burn through running paid AI Overview placement experiments over the same window. Outcome-priced contract scope ties the agency fee to the qualified-view target rather than the audit deliverable. The structural readiness number, the citation share number, and the CPQV number are what the contract pays against. Run agentic SEO on its own and the score rises. Run it under the FORKOFF outcome layer and the qualified views compound. The audit toolset is the diagnostic. The operating routines are the engine. The qualified-view instrumentation is the contract. Production AEO in 2026 needs all three.












