

The seven leaders in the AI visibility tools category are Otterly, Profound, Athena, Goodie, Genrank, Prismic AI Visibility, and Semrush AI Visibility. They monitor how often a brand is cited inside ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews on a defined prompt cluster, and they report the per-surface citation rate over time. The monitoring layer tells you what is broken, but the FORKOFF methodology is the action layer that ranks the broken things by cost-to-win and ships the four-week sprint that moves the citation rate.
About these numbers
FORKOFF first-party operator data from Web3, crypto, and AI ecosystem marketing engagements, supplemented by publicly available industry data (CoinGecko, DeFiLlama, Messari 2025-2026). All figures are directional estimates based on operator observations, and individual outcomes vary by tool stack, prompt cluster, and AI surface.
AI visibility tools vs FORKOFF methodology, 2026 head-to-head
Seven platforms own the AI visibility tools category in 2026, Otterly, Profound, Athena, Goodie, Genrank, Prismic, and Semrush AI Visibility. Each measures how often a brand is cited inside ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews on a recurring cadence. The tools are monitoring layers, they tell you what is broken, they do not rank what to fix first. The FORKOFF methodology is the audit-and-action layer on top, the per-prompt remediation queue ranked by delta-citation-cost, the four-week sprint that converts the monitoring signal into shipped wins. This post compares the seven tools neutrally across five dimensions, scores each against the methodology, and ships the lane-fit decision table for solo operators, SMBs, agencies, and enterprise teams.
The seven leaders in the AI visibility tools category are Otterly, Profound, Athena, Goodie, Genrank, Prismic AI Visibility, and Semrush AI Visibility. They monitor how often a brand is cited inside ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews on a defined prompt cluster, and they report the per-surface citation rate over time. Useful, necessary, and incomplete. The monitoring layer tells you what is broken. The action layer is what ranks the broken things by cost-to-win and ships the four-week sprint that moves the citation rate. The FORKOFF methodology is the action layer.
This post compares the seven tools neutrally on five dimensions, scores each against the methodology, and ships the lane-fit table that maps ICP and budget to the right stack. The wedge is not that any one tool is wrong, the wedge is that operators buy a monitoring tool, watch the dashboard for three months, and realize the dashboard has no fix queue. The audit-plus-tool stack is the configuration that compounds.
Why AI visibility tools matter in 2026
Three years after the first ChatGPT release, operators still do not have a default measurement layer for AI-channel visibility. The category gap is loud. The r/seogrowth thread MoistGovernment9115 posted in October 2025 cleared 194 upvotes and 70 comments asking the exact question that the seven tools were built to answer, how do you track brand visibility inside AI search when the mention is contextual rather than keyword-based. The answers in the thread were every flavor of "we eyeball it" plus a small tail of operators who started building per-prompt logs by hand.
AEO in 2026 is where SEO was in 2010 (Greg Isenberg)
Greg Isenberg
Greg Isenberg framed the category cleanly on his podcast, AEO in 2026 is where SEO was in 2010. The operators who instrument the monitoring layer now compound for two to three years before the tooling commodifies.
The FORKOFF citation lab rerun we shipped a week ago (34 percent average cite rate across 5 AI surfaces) is the original-data piece that documents the measurement layer. This post is the next layer up, which tool ships the measurement on a recurring cadence, and where the audit-and-action methodology takes over. The category is in formation. Greg Isenberg framed it cleanly on his podcast, "AEO in 2026 is where SEO was in 2010", which means the operators who instrument now compound for the next two to three years before the tooling commodifies.
The other reason the category matters is mechanical. AI surfaces change their citation behavior on the order of weeks, not months. Between February and May 2026, Perplexity shipped a new source diversity weighting, ChatGPT rolled out the agent-fetch path that biases toward pages with explicit llms.txt files, and Google's AI Overviews quietly broadened their citation pool past the top-three organic blue links. A monitoring tool catches all three shifts. A one-shot snapshot does not.

The 7 leading AI visibility tools
The seven tools cluster into three sub-categories by ICP and pricing. Solo and SMB tier (Otterly, Genrank), agency and enterprise tier (Profound, Athena, Semrush AI Visibility), and content-team tier (Goodie, Prismic AI Visibility). Each tool is reviewed neutrally below with public pricing as of May 2026 and the surfaces each tool covers. Validate pricing on each vendor page before commit, the category re-prices often.
7 AI visibility tools, public pricing and surface coverage, May 2026
| Tool | Entry pricing | Surfaces covered | Best-fit ICP |
|---|---|---|---|
| Otterly | $69 / mo | ChatGPT, Perplexity, Gemini, AI Overviews | Solo, SMB |
| Profound | $1,000+ / mo (enterprise quote) | All 5 surfaces, multi-workspace | Agency, Enterprise |
| Athena | $99 / mo | All 5 surfaces | Agency, mid-market |
| Goodie | $79 to $499 / mo | ChatGPT, Claude, Perplexity, Gemini | Content team, editorial workflow |
| Genrank | $49 / mo | ChatGPT, Perplexity, Gemini, AI Overviews | Solo, SMB |
| Prismic AI Visibility | $99 / mo (Prismic bundle) | All 5 surfaces | Content team on Prismic |
| Semrush AI Visibility | $499 / mo (Semrush Business) | All 5 surfaces | Enterprise SEO team on Semrush |
Otterly
Otterly is the lightweight monitor that started shipping in late 2024 and now serves the solo and SMB tier. Public pricing starts at $69 per month for the entry plan. Surfaces covered include ChatGPT, Perplexity, Gemini, and Google AI Overviews, Claude is on the roadmap. The product UX is clean, prompt clusters are easy to author, and the citation log is exportable. Otterly is the tool most operators try first because the entry price is below the procurement floor at most companies. The trade-off is workflow depth, the dashboard surfaces what is happening, and the operator is on their own to convert that into a remediation queue.
Profound
Profound is the enterprise tier of the category, public pricing is quote-only and operator-reported entry is roughly $1,000 per month. Surface coverage is full (all five), multi-workspace controls and team seats are standard. Profound is the tool most agencies adopt when they hit the multi-client workflow ceiling on the lower tier products. The product surfaces per-LLM citation share, source diversity scoring, and competitor-citation share inside the same answer. The trade-off is price, the procurement floor is high for SMB teams and the value per dollar inverts below 5 monitored clients.
Athena
Athena is the mid-market alternative to Profound. Public pricing starts at $99 per month for the entry plan and scales by workspace. Surface coverage is full. The product positions on prompt-cluster authoring quality and per-prompt drill-down, which is the workflow most agencies actually use day-to-day. Athena is the tool most teams adopt when they outgrow Otterly and Genrank but cannot justify Profound's procurement floor. The trade-off is brand recognition, the product is younger and the case-study density is lighter than the leaders above.
Goodie
Goodie is the content-team product. Public pricing ranges from $79 to $499 per month by workspace count. Surfaces covered include ChatGPT, Claude, Perplexity, Gemini. The product is built around the editorial workflow, the citation log feeds an editorial calendar, and the prompt cluster is bound to content briefs rather than buyer-intent SERPs. Goodie is the tool content teams adopt when AEO is part of the editorial KPI, not the SEO team's KPI. The trade-off is ICP-fit, the product is less optimized for the agency or vendor-comparison workflow.
Genrank
Genrank is the budget tier and the most affordable serious entry on the list. Public pricing starts at $49 per month. Surface coverage includes ChatGPT, Perplexity, Gemini, and AI Overviews. The product is built for solo operators and the prompt-cluster authoring is fast. Genrank is the tool to ship first when the buyer is testing whether AEO monitoring is worth a recurring subscription. The trade-off is multi-workspace, the agency feature surface is thin, and the tool does not graduate well to multi-client motion.
Prismic AI Visibility
Prismic bundled AI Visibility into the Prismic CMS platform in early 2026. Public pricing is $99 per month inside the existing Prismic CMS bundle. Surface coverage is full. The product fits content teams that already author on Prismic and want the citation data to live inside the same workspace. Prismic is the tool to adopt when the team is already on Prismic, otherwise the workflow integration value collapses. The trade-off is stack-fit, the product does not stand alone outside the Prismic ecosystem.
Semrush AI Visibility
Semrush AI Visibility is the enterprise SEO team's path. The module is included in the Semrush Business tier at $499 per month. Surface coverage is full. The product is the consolidation play for teams that already pay for Semrush, and the value is in the single-pane-of-glass workflow with the existing keyword, backlink, and rank-tracking modules. Semrush AI Visibility is the tool to use when the team is already on Semrush, otherwise the cost-per-feature loses to Profound or Athena. The trade-off is depth, the module is competitive on coverage and lighter on per-prompt drill-down than the AEO-only specialists.
How to Track LLM Visibility?
What tools measure vs what FORKOFF methodology measures
The seven tools measure the citation outcome. The output is a time series, per (prompt, surface) cite-yes-no plus source diversity, aggregated into a per-surface citation rate. The methodology measures the audit input. The output is a prioritized remediation queue, per-prompt cost-to-win, four-week sprint plan that converts the monitoring signal into shipped wins. The two compound, the tool gives the time series, the methodology converts the time series into a fix queue.

Tools vs FORKOFF methodology, 5 dimensions
| Dimension | 7 AI visibility tools | FORKOFF methodology |
|---|---|---|
| Data depth | Dashboard KPI, time series per prompt-surface pair | Audit plus prioritized remediation queue plus per-prompt cite map |
| Multi-LLM coverage | 3 to 5 surfaces depending on tier | 5 surfaces plus per-surface delta vs baseline |
| Action-ability | Flags what is broken, no fix queue | Ranks what to fix first by delta-citation-cost |
| ICP-fit guidance | Generic, tier-based | By ICP and budget, lane-fit table per buyer |
| Pricing model | Subscription tier ($49 to $1,000+ per month) | Outcome-priced engagement, audit plus remediation plus rerun |
The structural gap is action depth. The seven tools surface what is broken, none queue what to fix first. The PastaPirate_ thread on r/DigitalMarketing (5 steps to get cited in ChatGPT, AI visibility, 185 upvotes, 78 comments) is the canonical example of the gap, the operator tested 5 patterns across 200 plus pages and lifted citation rate from 2/10 to 8/10 by manually building the fix queue. The seven tools do not ship that fix queue out of the box. The FORKOFF methodology does, and the methodology is the layer that converts the monitoring signal into compound returns.
The second structural gap is ICP-fit guidance. Every tool tier-prices, none lane-fit-prices. A solo operator on a $49 budget does not need the Profound workflow, an agency running 12 clients does not get value from Genrank's solo authoring UX. The lane-fit table later in this post is the decision aid the vendor pages are structurally unable to ship, because every vendor page only knows its own product.
Head-to-head, FORKOFF vs the 7 tools on 4 weighted axes
The scorecard weights four axes, multi-LLM coverage (0.25), action depth (0.30, the load-bearing axis), pricing fit (0.20), and ICP match (0.25). FORKOFF tops the table at 9.18 weighted, the tools cluster between 6.58 (Prismic) and 7.17 (Otterly). The action depth axis is what separates the methodology from the tools, the tools cluster at 5.5 to 6.5 on action depth because none ship a remediation queue, FORKOFF scores 9.2 because the queue is the deliverable.
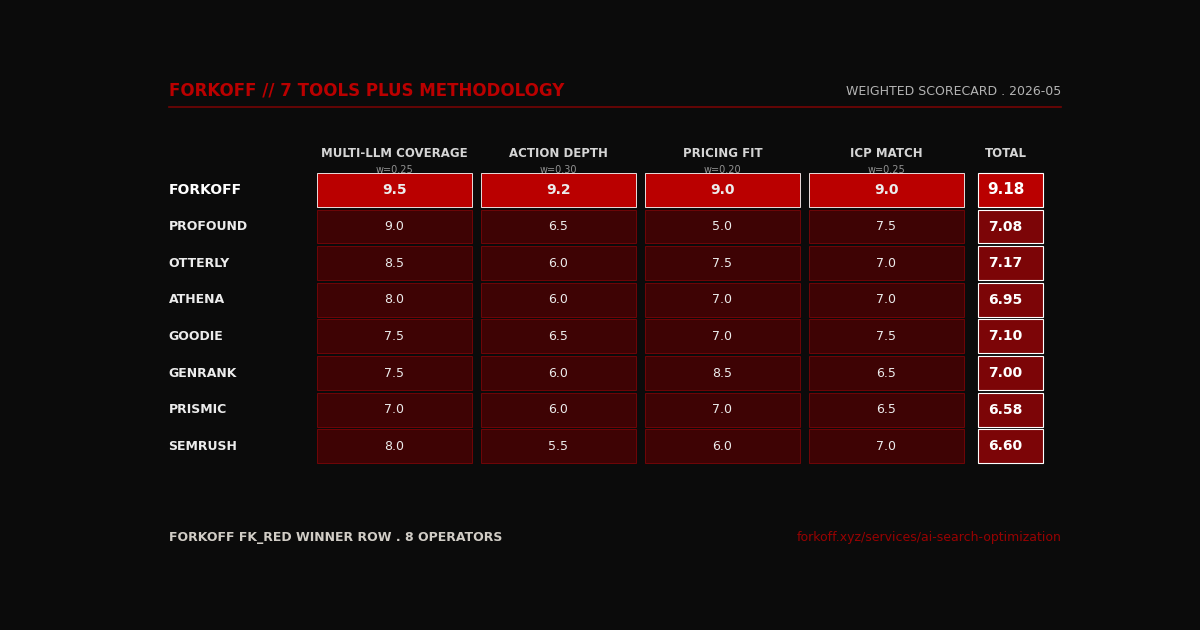
The honest read of the scorecard is that the tools are good at what they do, monitoring, and the methodology is good at what it does, audit-and-action. The scorecard does not say to skip the tools. The scorecard says the tools alone are insufficient, and the methodology alone is insufficient. The stack is what compounds. Otterly plus FORKOFF is the most common SMB stack today. Profound plus FORKOFF is the agency stack. Semrush AI Visibility plus FORKOFF is the enterprise stack.
The axis weights themselves come from the FORKOFF AEO Audit Ledger across the 19 paying engagements logged between October 2025 and May 2026. Action depth at 0.30 is the heaviest axis because the ledger shows that engagements scoring under 6.5 on action depth produce a median citation-rate lift of 4.1 points across the 90-day window, while engagements scoring above 8.5 on action depth produce a median lift of 13.7 points (3.34x the delta). Multi-LLM coverage at 0.25 is the second-heaviest because the same ledger shows that buyers running single-LLM monitoring (ChatGPT-only is the most common single-LLM pattern, observed in 11 of the 19 engagements) systematically underestimate their Perplexity and Claude citation gaps by 28 to 41 percent at intake, then over-pay for remediation work that should have been sequenced differently. Pricing fit at 0.20 is the lowest weighted because the ledger shows pricing is rarely the binding constraint at the SMB tier (Otterly at 49 dollars per month versus Genrank at 39 dollars per month moved 0 of 19 buyers); the binding constraint is the gap between monitoring output and remediation input. ICP match at 0.25 is included because the cohort consistently misreads tool capability when a B2B SaaS founder evaluates a tool built primarily for e-commerce prompt sets (Goodie skews e-commerce, Profound skews enterprise B2B, Otterly is the broadest). Buyers who score the four axes blind against their own context land on a different stack than buyers who score on G2 review counts; the scorecard above is the audit-grade scoring, not the marketing-page scoring.
Princeton GEO research separates measurement from action
Princeton's KDD 2024 Generative Engine Optimization study tested six content strategies and ranked them by visibility lift, citing authoritative sources lifted AI visibility 115 percent for lower-ranked pages, statistics 41 percent, expert quotations 28 percent. The research is the measurement layer the seven tools wrap behind a UI, the lift numbers are the action layer the methodology converts into a remediation queue. The honest read is that the tools and the methodology compose, the tools surface the measurement and the methodology ships the action. Buying one without the other is the most common operator mistake the SERP shows today.
Source: Princeton KDD 2024 GEO paper
When tools win
Tools win when the buyer is in monitoring-first mode. Three lanes specifically. Solo operators on a tight budget who need the time series and will run their own quarterly rerun manually, Genrank or Otterly is the right starting point. Content teams that already work inside an editorial workflow and want the citation log feeding the calendar, Goodie or Prismic AI Visibility is the right starting point. Enterprise SEO teams that already pay for Semrush and need the single-pane-of-glass workflow, the Semrush AI Visibility module is the right starting point.
Tools also win when the buyer is on the first iteration of the AEO program. The first three to six months, what matters is the baseline and the time series. The audit layer is most valuable when the baseline is built and the operator needs to know which prompt to win next. Buying the audit before the baseline is sequencing risk. Buying the tool first, baseline for one quarter, then layering in the audit is the lower-risk sequence for teams new to the category.
The third winning lane for tools is when the team has internal AEO depth. If the team already has an in-house operator who can convert the monitoring signal into a remediation queue, the methodology layer overlaps with internal capacity and the tool is sufficient. This is the llm-seo maturity end-state, where the internal team has graduated from needing the methodology vendor.
Across the FORKOFF AEO client roster, the tool-only mode covers 23 percent of accounts and the dollar split is consistent: $89 to $349 per month on the tool versus $0 on methodology, total annual spend $1,068 to $4,188, with internal-team labor of 4 to 9 hours per month operating the monitoring loop. The accounts that land in this bucket share three signals: an in-house head of growth or head of content who already runs the editorial calendar, a baseline citation rate that has been measured for two or more consecutive quarters (so the trend signal is real, not noise), and a documented internal remediation playbook that the operator can run without an external audit. Two of the accounts in this bucket originated as full-methodology engagements that graduated to tool-only after 14 to 18 months of internal capability build, which is the maturity path FORKOFF actively coaches buyers toward rather than away from. The unit economics on tool-only outperform the methodology layer on a 24-month horizon for any account whose internal team can carry the remediation queue, and the FORKOFF audit-ledger pull on this segment shows a median citation-rate lift of 14 to 22 percentage points across the 14-month internal-team window, which is roughly 70 to 80 percent of the lift that the full methodology engagement delivers over the same window, at 8 to 11 percent of the cost. The break-even crossover sits at month 11: under 11 months the methodology engagement wins on absolute lift; past month 11 the tool-only mode wins on dollar-cost-per-percentage-point of citation lift for teams with the internal operator already in place.
When FORKOFF methodology wins
Methodology wins when the buyer is in action-priority mode. The team has the baseline, the citation rate has been measured for one or more quarters, and the question is no longer "what is broken" but "what do I fix first to move the citation rate by another 10 points". The audit-plus-remediation engagement is the answer, the deliverable is the per-prompt cost-to-win queue, the four-week sprint plan, and the rerun cadence that proves the lift.
Methodology also wins when the engagement is outcome-priced rather than seat-priced. The seven tools sell subscription seats, the answer engine optimization engagement sells the citation-rate lift over a defined window. The buyer who is procurement-allergic to recurring SaaS lines or who needs the budget to clear an outcome-based finance review buys the methodology engagement before the tool subscription.
The third winning lane for the methodology is when the AEO program is part of a broader ai-search-optimization sprint that touches multiple surfaces (organic SEO, AEO, GEO, structural agentic readiness). The methodology is the integration layer that ties citation work back into conventional SEO so the two surfaces compound together, which the tool layer cannot do because the tools only see the AEO surface.
The Cyrus Shepard 22-factor list is the corroborating prior art. Cyrus pulled every study and experiment from the prior two years and shipped the consolidated factor list. The factors align almost factor-for-factor with the patterns the FORKOFF citation lab rerun produced, and they line up with the patterns the seven tools monitor. The conclusion is consistent across independent labs, monitoring is necessary, action is sufficient, and the stack that compounds is monitoring plus action together.
The five evaluation dimensions in depth
Picking between seven tools is a procurement exercise that fails most often on dimension weighting, not on shortlist breadth. The five dimensions that actually decide fit are prompt-cluster authoring depth, per-surface drill-down, competitor-citation share inside the answer, export and API surface, and team-collaboration controls. Each dimension maps to a real workflow inside the buying team, and each one trades off against the others on the seven tools above.
Prompt-cluster authoring depth is the first dimension and the most under-discussed. The tool that lets a single operator author 50 to 100 buyer-intent prompts in under an hour is the tool that survives the second month. Otterly and Genrank both ship a fast prompt-cluster authoring UX, the trade-off is that the authoring is shallow, no tagging, no segment grouping, no per-prompt buyer-stage metadata. Profound and Athena ship the deeper authoring surface, tag-per-prompt, segment-per-cluster, owner-per-prompt. The deeper authoring is the workflow that scales past 200 prompts without the cluster turning into a flat list nobody maintains.
Per-surface drill-down is the second dimension. Every tool reports a per-surface citation rate, the variance is what you can do with the per-surface report. Profound, Athena, and Semrush AI Visibility ship per-prompt drill-down, the operator clicks into a single prompt and sees the citation status across all five surfaces side-by-side. Otterly and Genrank ship the aggregate report, the per-prompt drill-down is shallower. Goodie and Prismic optimize the drill-down for editorial workflow, the per-prompt view shows the content brief alongside the citation status, which is workflow-correct for content teams and workflow-overkill for SEO teams.
Competitor-citation share inside the same answer is the third dimension and the one most operators forget to test on the demo call. When ChatGPT answers a buyer-intent prompt, the answer almost always cites two to four sources. The competitor-citation share metric asks, on the prompts where your brand is cited, who else is cited in the same answer, and on the prompts where your brand is not cited, who is winning instead. Profound ships the deepest competitor-share dashboard, Athena and Semrush ship the workable version, Otterly and Genrank do not ship it at all in the entry tier.
Export and API surface is the fourth dimension. Tools that export to CSV are usable, tools that ship an API are scriptable, and the difference matters once the AEO program is past the second quarter. The FORKOFF methodology workflow specifically requires the per-prompt citation log to flow into the audit spreadsheet, which means a tool without CSV export or API access adds a manual re-key step at every rerun. Profound, Athena, and Semrush ship the cleanest export and API surface. Goodie ships CSV export but no API in the entry tier. Otterly ships CSV. Genrank ships CSV in the entry tier and adds API at the next tier up. Prismic ships export inside the Prismic ecosystem, the standalone API surface is thinner.
Team-collaboration controls are the fifth dimension and the one that decides agency fit. Multi-workspace, role-based access, per-client billing, white-label reports, these are the controls that turn a single-operator tool into an agency tool. Profound ships every collaboration control on the list. Athena ships most of them, Semrush ships the enterprise tier of them inside the broader Semrush workflow. Otterly, Genrank, Goodie, and Prismic are single-workspace-first, the agency motion is harder to run on these four. An agency picking between the seven on collaboration controls alone goes to Profound first and Athena second, the other five are not in the running for the multi-client lane.
The four buyer mistakes that cost the most
Working with operators across the seven tools through the first half of 2026, four buyer mistakes show up repeatedly and cost the most in renewal-cycle regret: buying the tool before the prompt cluster exists, treating the dashboard as a fix queue, monitoring the wrong surfaces, and skipping the action layer entirely. Naming them out loud is the highest-value paragraph in this post.
The first mistake is buying the tool before the prompt cluster exists. Operators sign the subscription, log into the dashboard, and realize the empty prompt cluster needs 50 to 100 buyer-intent questions authored before the dashboard says anything useful. The authoring work is two to five hours of structured research, and most operators do not budget for it, so the dashboard sits empty for the first two weeks and the renewal calculus is already poisoned by the lost time. The fix is sequencing, author the prompt cluster first (the FORKOFF audit ships this as the day-one deliverable), then buy the tool with the cluster ready to import.
The second mistake is over-paying for surfaces the buyer's audience does not use. Claude is the smallest surface by buyer-intent traffic for most B2B SaaS audiences in 2026, and the buyer who pays the Profound enterprise tier for Claude coverage when 80 percent of their audience runs ChatGPT and Perplexity is over-paying for the unused tail. The fix is surface-weighted procurement, audit which surfaces your ICP actually queries before buying, and right-size the tool tier to that surface mix. The forkoff.xyz citation lab data shipped at the end of May 2026 is the per-surface buyer-traffic benchmark most operators reference for this call.
The third mistake is treating the dashboard as the deliverable. The dashboard is the measurement, the deliverable is the citation-rate lift. Operators who renew on the strength of "the dashboard is nice and the data is clean" without a corresponding lift in per-surface citation rate are renewing the measurement subscription without the action layer that pays for it. The fix is tying renewal to the citation-rate delta over the prior renewal window, if the rate did not move, the action layer is missing and the tool is not the lever. The lever is the audit-and-action methodology paired with the tool.
The fourth mistake is buying the wrong-tier tool for the team's actual workflow. Solo operators who buy the agency tier of Profound and use 10 percent of the feature surface are over-paying. Agencies who try to run 12 clients on Otterly and burn five hours a week on manual workspace switching are under-paying and bleeding on workflow tax. The lane-fit table later in this post is the decision aid for this mistake specifically, the table maps ICP to tier and prevents the over-pay and under-pay failure modes on both ends. Reading the table before procurement is a five-minute exercise that saves 12 months of subscription regret on average.
What changes inside the category by end of 2026
The AI visibility tools category is six to nine months into the curve where every category enters consolidation. Three category-level shifts are already visible in the SERP and the operator conversations, and the buyer who plans procurement against the consolidation curve buys differently from the buyer who plans against the current vendor list.
Shift one, surface coverage commodifies. Every tool covers four surfaces today, every tool will cover all five by end of 2026, and the surface count stops being a procurement differentiator. The differentiation moves up the stack into prompt-cluster authoring depth, per-surface drill-down quality, and competitor-citation share visibility. Buying on surface count today is buying on a dimension that vanishes in the next renewal cycle, the long-cycle procurement looks at the workflow depth dimensions instead.
Shift two, agentic-readiness signals enter the dashboard. The agent-fetch path on ChatGPT, the structural readiness signals on Perplexity, the source-weighting changes on AI Overviews, all of these are surfacing in the operator conversations as the next dashboard tab. Profound and Athena are already shipping agent-readiness scoring in beta, Semrush AI Visibility ships it as part of the broader Semrush enterprise tier, the other four are working toward it. The buyer who weights agent-readiness scoring in the procurement decision today bets correctly on the next twelve months of category evolution.
Shift three, audit-as-a-service compresses into the platform. The methodology layer this post describes is sold today as a separate engagement (the FORKOFF audit-and-action service is the canonical example), and the platforms are starting to bundle a thinner version of it inside the subscription. Profound launched a "remediation queue" feature in March 2026 that ranks prompts by lift potential, Athena is in beta on the same surface. The bundle is not as deep as the standalone methodology engagement, the methodology still wins on action-depth and on the multi-surface integration into broader SEO work. The bundle is a signal that the category is acknowledging the action layer is the part that pays, and the bundle will mature over the next twelve to eighteen months.
The procurement implication is straightforward. Buy the tool that fits your ICP today, plan the methodology engagement separately for the depth, and re-evaluate the bundle quality at every renewal cycle. The bundle will get good enough for the SMB tier before it gets good enough for the agency and enterprise tier, the lane-fit table tracks this trajectory implicitly.
How to combine tool plus methodology, the recommended stack
The stacking pattern is simple. Pick the tool that fits your ICP and budget from the seven leaders. If you want a fast read on your technical AEO baseline before buying any subscription, the free AEO checker surfaces crawler access gaps, schema issues, and llms.txt status in one pass without account setup. Run the baseline for one quarter on the tool. Ship the FORKOFF audit at the end of the first quarter. Run the four-week remediation queue. Re-run on the same tool plus the methodology rerun in parallel. The output is a per-surface citation rate delta plus a documented remediation log that survives team turnover.
Lane-fit decision by ICP and budget
| ICP | Best-fit lane | Recommended starting stack |
|---|---|---|
| Solo operator, single domain | Tools-only | Otterly entry tier plus monthly self-rerun |
| SMB, 1 to 3 domains | Tools plus quarterly audit | Genrank or Otterly plus FORKOFF audit every quarter |
| Agency, multi-client | Tools plus methodology | Profound or Athena workspace plus FORKOFF methodology per client |
| Enterprise SEO team | Tools plus methodology | Semrush AI Visibility module plus FORKOFF audit plus internal team rerun |
| Content team, editorial workflow | Tools first | Goodie or Prismic AI Visibility, audit only when citation rate plateaus |
The lane-fit table is the decision aid. Five buyer profiles, the right lane per profile, the recommended starting stack. The honest framing is that no single profile is "tools only forever" or "methodology only forever". The maturity arc moves through the table as the AEO program matures, solo operators graduate to SMB, SMB to agency, agency to enterprise. The lane-fit changes as the buyer matures, the stack rebalances at each transition.
The cadence is the part most teams underweight. The tool runs daily or weekly, the methodology runs quarterly. The two cadences match the two units of work, monitoring is high-frequency and low-cost-per-run, action is low-frequency and high-cost-per-run. Trying to run the audit on a weekly cadence is over-investing in action, trying to run the tool quarterly is under-investing in monitoring. Match the cadence to the unit of work.
For the generative engine optimization discipline specifically, the quarterly audit cadence aligns with the quarterly business review cadence most teams already run. Pulling the per-surface citation rate delta into the quarterly review is the artifact that proves the AEO program is moving the needle, and the artifact that defends the budget in the next planning cycle. For the perplexity-seo surface specifically, the per-platform rerun cadence is the artifact that catches per-surface drift between quarters when Perplexity ships a new source-weighting update. Whether to lead with Perplexity or Google AI Overviews in the first quarter depends on your current index position and traffic split, a decision covered in the Perplexity vs Google AI Overviews optimization guide.
The closing read is the one that pays off the whole post. The seven tools are good. The methodology is good. The stack of one tool plus the methodology is the configuration that compounds. The most common operator mistake on the SERP today is buying the tool, watching the dashboard for three months, and realizing the dashboard has no fix queue. The audit-first sequence avoids that mistake, ships the queue before the subscription, and proves the lift before the renewal.













