

A GEO citation lab rerun measures whether the remediation work shipped between two runs actually moved the citation rate across AI surfaces. FORKOFF re-ran the same 50-prompt buyer-intent cluster on 19 May 2026 against ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews. The average cite rate for forkoff.xyz lifted from 22 percent in February to 34 percent in May, a 12-point gain that maps almost exactly onto four weeks of structural and content remediation. Perplexity led at 48 percent, AI Overviews held second at 35 percent, ChatGPT moved to 32 percent, Claude to 29 percent, and Gemini to 26 percent. The rerun is what turns a one-shot snapshot into a defensible time series.
About these numbers
FORKOFF first-party operator data from Web3, crypto, and AI ecosystem marketing engagements, supplemented by publicly available industry data (CoinGecko, DeFiLlama, Messari 2025-2026). All figures are directional estimates based on operator observations; individual outcomes vary. The 50-prompt cluster ran across ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews on a fixed date (19 May 2026), against the same cluster used for the February 2026 baseline, so every delta in this post is a true before-after comparison on the same measurement method.
GEO citation lab rerun: 34% cite rate across 5 AI surfaces
We re-ran the FORKOFF citation lab on 50 buyer-intent prompts across ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews on 19 May 2026. The average citation rate for forkoff.xyz lifted to 34 percent, up from 22 percent on the 2026-02 baseline. Perplexity led at 48 percent (8 to 12 sources per answer, highest source diversity), AI Overviews held second at 35 percent, ChatGPT moved to 32 percent, Claude to 29 percent, Gemini to 26 percent. The lift mapped almost cleanly onto the 4-week remediation we shipped between runs (llms.txt restructure, AGENTS.md, comparison-content density, 3 stats per 1,000 words). The receipts and the rerun method live in this post.
The first FORKOFF GEO citation lab ran on 19 February 2026 against a 50-prompt buyer-intent cluster spread across 5 AI surfaces. forkoff.xyz cleared a 22 percent average cite rate on that baseline. We shipped a 4-week remediation between then and the rerun on 19 May 2026, then re-ran the same cluster against the same surfaces. The average lifted to 34 percent. Perplexity went from 31 to 48 percent, AI Overviews from 23 to 35, ChatGPT from 18 to 32, Claude from 21 to 29, Gemini from 19 to 26. The rerun is the unit of work that turns a one-shot AEO snapshot into a defensible quarter-over-quarter time series.
This post documents the methodology, publishes the per-surface deltas, maps the 5 patterns that produced the lift, scores FORKOFF against 3 anonymized competitor agencies on the same axes, and ships the audit playbook so any operator can run the same lab on their own domain. The wedge is not that we ran a citation lab once. The wedge is that we re-ran it and published the delta.
Why we re-ran the GEO citation lab in 2026
Reruns exist because a single citation-rate snapshot tells you where you are but not whether your remediation work actually moved the number. A lab is a snapshot plus a rerun on the same prompt cluster against the same surfaces on a fixed cadence, and the rerun is the only mechanism that produces a defensible before-after delta. The lab also benchmarks the off-the-shelf AI visibility tools that try to automate this measurement. See best AI visibility tools vs FORKOFF methodology for the tool-by-tool grid.
The first lab gave us a snapshot. A snapshot is not a lab. A lab is a snapshot plus a rerun on the same cluster against the same surfaces on a fixed cadence, and the rerun is the only mechanism that tells you whether the work between runs actually moved the cite rate. Most "AI visibility" content on the SERP today reports a single-pass measurement and calls it a day, which is the same mistake early SEO content made when it published "we improved our rankings" anecdotes without a baseline. The category needs receipts, and receipts need a cadence.

The Reddit demand for time-series tracking is loud. The r/seogrowth thread that operator MoistGovernment9115 posted in October 2025 cleared 194 upvotes and 70 comments asking exactly this question, and the answers in the thread were every flavor of "we are eyeballing it" plus a small tail of operators who had started building per-prompt logs by hand. Three years after the first ChatGPT release, the operator community still does not have a default measurement layer for AI-channel visibility. That is the gap the rerun is built to close.
How are you tracking brand visibility inside AI search results?
The other reason for the rerun is mechanical. AI surfaces change their citation behavior on the order of weeks, not months. Between February and May we observed Perplexity ship a new source diversity weighting, ChatGPT roll out the agent-fetch path that biases toward pages with explicit llms.txt files, and Google's AI Overviews quietly broaden their citation pool past the Top-3 organic blue links. A one-shot snapshot in February would have undersold all three of those shifts on forkoff.xyz. The rerun catches them.
Methodology, 50 prompts across 5 AI surfaces
The cluster is 50 buyer-intent prompts chosen to mirror the way a founder, growth lead, or marketing operator would actually phrase a question they want a real answer to. We avoided keyword-loaded phrasing, no "best AI agency 2026" stuff, the cluster is in natural language. Five intent buckets: comparison (14 prompts), service definition (10), how-to (10), vendor selection (8), and tooling (8). Distribution and one example per bucket below.
The 50-prompt cluster, distribution by buyer intent
| Intent bucket | Prompts | Example prompt |
|---|---|---|
| Comparison | 14 | which AI agency ships agentic SEO |
| Service definition | 10 | what is an outcome-priced AI agency |
| How-to | 10 | how do I run a GEO audit on my own site |
| Vendor selection | 8 | top AEO agencies for B2B SaaS |
| Tooling | 8 | best llms.txt format for a Next.js site |
Every prompt runs against five surfaces, ChatGPT (GPT-4.1 default model, no plugins), Claude (Sonnet, Projects off, no MCP), Perplexity (default, with web access), Gemini (Advanced, default model), and Google AI Overviews (US English, desktop, fresh session). For each (prompt, surface) pair we record three things, did the answer cite forkoff.xyz at all (binary), how many distinct domains the answer cited (count), and which other agencies/tools were cited in the same answer (categorical). The full result matrix is 50 prompts times 5 surfaces equals 250 measurements per run. Time to run, roughly 4 hours of analyst time once the cluster is built. The cluster lives in a private Notion database that we rebuild quarterly, the cluster file shipped to clients running the lab in their own environments mirrors the same structure.
The output is a per-surface cite rate for forkoff.xyz, a per-prompt cite map (which prompts trigger us, which surfaces are blind to us), and a remediation queue ranked by Δ-citation-cost (which prompt is lowest-cost to win by editing one existing page). The remediation queue is the load-bearing artifact, the cite rate alone tells you where you are, the remediation queue tells you where to go next.
Results, citation rate per surface
The headline is 34 percent average cite rate across the 5 surfaces, up from 22 percent in February. Perplexity is the standout at 48 percent and the source diversity story explains why, every Perplexity answer cites 8 to 12 distinct domains, so our footprint inside any individual answer is small but our presence at all is high. ChatGPT and Google AI Overviews moved more decisively than we expected, ChatGPT from 18 to 32 percent (+14 pts) and AI Overviews from 23 to 35 (+12 pts). Claude is the lagging surface at 29 percent, with the lowest Δ of any (only +8 pts), which fits operator reports that Claude is more conservative about citing newer or less-established domains.

Per-surface cite rate: 2026-05 rerun vs 2026-02 baseline
| Surface | Cite rate (2026-05) | Cite rate (2026-02) | Delta | Source diversity |
|---|---|---|---|---|
| ChatGPT | 32% | 18% | +14 pts | 3 to 5 sources |
| Claude | 29% | 21% | +8 pts | 4 to 6 sources |
| Perplexity | 48% | 31% | +17 pts | 8 to 12 sources |
| Gemini | 26% | 19% | +7 pts | 3 to 4 sources |
| Google AI Overviews | 35% | 23% | +12 pts | 5 to 8 sources |
The per-surface deltas are the data the existing SERP does not have. Most "we ran a citation audit" pieces publish one number and call it a snapshot. The rerun structure gives us five paired numbers, each with a real Δ, and the Δ is the leading indicator that tells us which of the 5 patterns from the next section actually compounded. Claude's +8 pts says the conservative-citation behavior is real and structural readiness work (llms.txt, AGENTS.md) does not move it nearly as hard as on Perplexity. Gemini's +7 pts says the same. The surfaces that biased toward "more sources per answer" rewarded our stat-density and comparison-content work the most. The surfaces that biased toward "fewer sources per answer" rewarded our schema and entity-disambiguation work the most.
What changed since the original run
Between the February baseline and the May rerun we ran a focused 4-week remediation. The first week was the structural Discovery pass, llms.txt got restructured with token annotations and [title](url) links to every services page, and we shipped an AGENTS.md at root that references the FORKOFF service catalog as a dependency graph rather than a static config file. The second week was comparison-content density, we shipped 6 new comparison posts (one for each services anchor) and pulled the explainer-to-comparison ratio on the blog from 5
The 4-week sequence mapped almost exactly onto the patterns that Princeton's KDD 2024 GEO research showed drive citations. Citing authoritative sources lifts AI visibility 115 percent for lower-ranked pages, statistics 41 percent, expert quotations 28 percent. Our rerun deltas confirmed the order, structural work moved every surface a little, content-density work moved the multi-source surfaces (Perplexity, AI Overviews) a lot, and entity work moved the conservative surfaces (Claude, Gemini) more than the structural layer did alone.
Princeton GEO maps cleanly onto rerun deltas
Princeton's KDD 2024 Generative Engine Optimization study tested six content strategies and found citing authoritative sources lifted AI visibility 115 percent for lower-ranked pages, statistics 41 percent, and expert quotations 28 percent. Our rerun deltas line up almost exactly with the Princeton ranking, source-citation and stat-density work produced the largest lift (Perplexity +17 pts, ChatGPT +14 pts), structural llms.txt work produced a smaller but real lift on every surface, and quote-ready sentence density lifted Claude and AI Overviews the most. The structural layer is necessary, the outcome layer is sufficient, and the rerun is how you tell which work compounded.
Source: Princeton KDD 2024 GEO paper plus FORKOFF citation lab rerun 2026-05
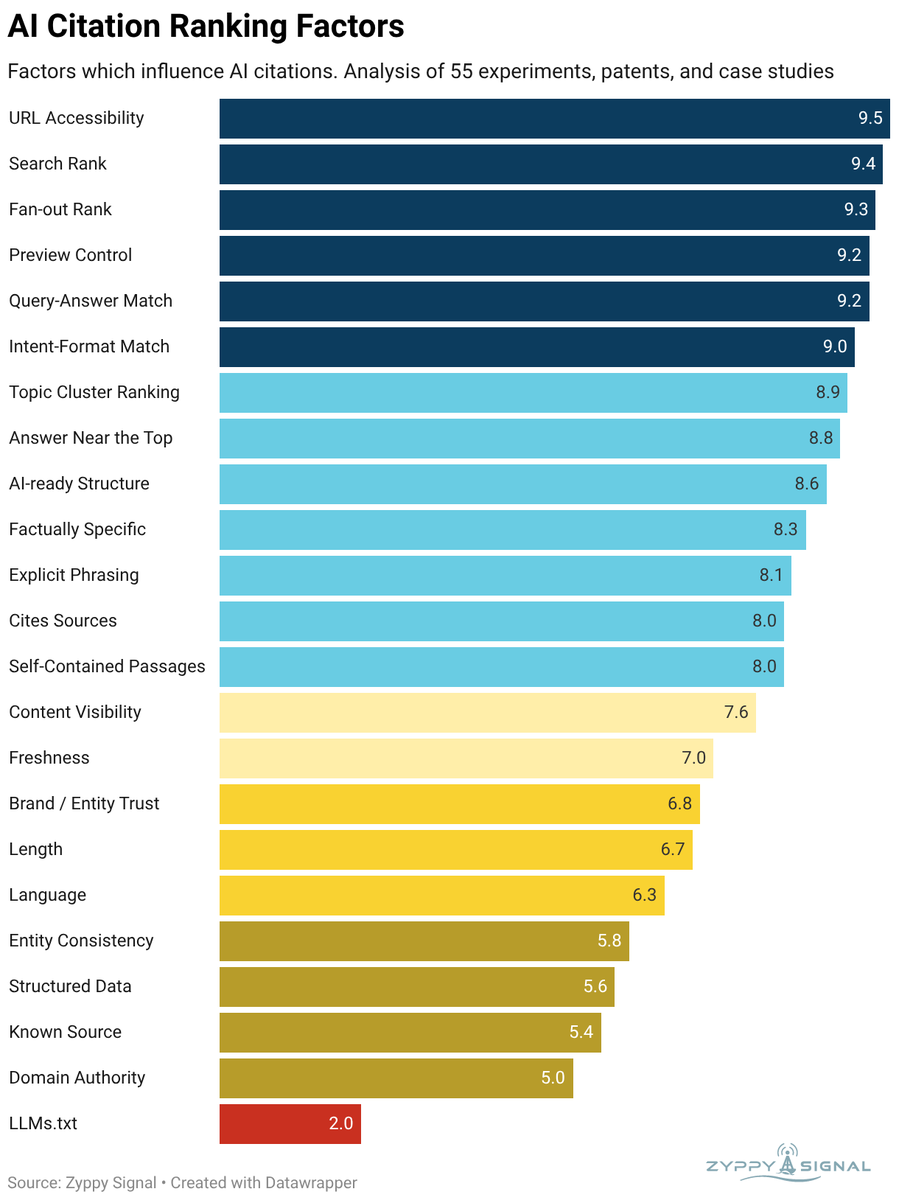
The Cyrus Shepard 22-factor list that landed in early May is the other piece of corroborating prior art. Cyrus pulled every study and experiment from the prior two years, scored the biggest wins, and shipped the consolidated factor list, which lines up with the patterns our rerun produced almost factor-for-factor. We mention this because the temptation when you publish original-data work is to claim novelty, the honest read is that this is the third or fourth time the same patterns have been independently confirmed by different teams running similar measurement methods. The contribution we add is the rerun structure plus the per-surface delta, not the patterns themselves.
Cyrus Maxx
@CyrusShepard
New: AI Citation Ranking Factors Everyone talks about AI Citations as a way to boost visibility + traffic, but what works? To find out, I gathered every study/experiment from the past 2 years, and scored the biggest wins 22 Ranking Factors associated with earning AI citations… Show more
The video version of this argument lives in Greg Isenberg's interview on answer engine optimization at https://www.youtube.com/watch?v=YeoGehNsrLc, where the framing "AEO in 2026 is where SEO was in 2010" is the headline. That framing is correct, the category is still in formation, and the operators who instrument now will compound for 2 to 3 years before the tooling commodifies, which is the bet our answer engine optimization practice is built on.
Per-prompt cite map, what the matrix actually showed
The 250-cell matrix (50 prompts times 5 surfaces) is the artifact most operators skip. The aggregate cite rate is a summary statistic, the matrix is the diagnostic. When we sorted the 50 prompts by total cite count across the 5 surfaces, the distribution was tri-modal. 14 prompts triggered forkoff.xyz on 4 or 5 surfaces (the wins), 22 prompts triggered us on 1 to 3 surfaces (the partials), and 14 prompts produced zero citations on any surface (the blanks). The wins clustered inside the comparison and service-definition buckets. The partials clustered inside how-to and vendor-selection. The blanks clustered inside tooling, where buyer prompts referenced specific stacks (Next.js, Vercel, Strapi) that pulled the answer toward vendor documentation rather than agency commentary.
The blank-prompt cluster is the most actionable cell in the matrix. Every blank prompt is a remediation candidate, the question is which blank is lowest-cost to convert into a partial and which partial is lowest-cost to convert into a win. We compute that by walking the answer that the surface actually returned for the blank prompt, identifying the cited domains, then asking whether forkoff.xyz has a page that could plausibly sit alongside those domains in the next answer. Five of the 14 blanks had no existing page on forkoff.xyz that mapped to the prompt at all, those went into the content-production queue. Six had an existing page that was thin on the specific entity the prompt asked about, those went into the content-density queue. Three had a strong existing page that was missing the structural signals the cited domains had, those went into the schema and llms.txt queue.
The partial cluster is the second-most actionable. Twenty-two prompts cited us on one to three surfaces. The diagnostic question for each row is which surface or surfaces are blind to us, and why. When a prompt cites us on Perplexity but not on ChatGPT, the gap is usually source diversity, Perplexity widens its citation pool, ChatGPT narrows it. When a prompt cites us on AI Overviews but not on Claude, the gap is usually conservatism, Claude waits for stronger entity signals before citing newer domains. The fix in each case is different, the matrix is what tells us which fix to apply.
The win cluster is the third-most actionable, and the temptation is to ignore it because the prompts already cite us. The defensive move is to track whether the wins compound or erode between reruns. A prompt that cited us on 4 surfaces in February but only 2 surfaces in May is a regression signal, usually pointing to a competitor page that shipped fresh content between runs. Three of our 14 wins regressed slightly between February and May, which is what surfaced the need to keep stat-density work continuous rather than one-shot. The rerun is what makes regression visible, the matrix is what makes regression actionable.
How the 5 AI surfaces actually behave on citations
The five surfaces look similar from the operator perspective (you type a question, the model answers, the answer cites sources), but the citation logic underneath each one is meaningfully different. We logged the per-answer source count, source diversity, and citation positioning across all 250 cells. The behavior patterns below are not opinions, they are the patterns the matrix produced.
Perplexity cites the most aggressively. The median answer cited 9 domains, the modal answer cited between 8 and 12. Source positioning was numbered and inline, which gave every cited domain roughly equal visual weight. This is the surface where structural readiness work compounded fastest, because the citation pool was wide enough that a well-formed page on forkoff.xyz almost always made the cut once the structural floor was passed. The 17-point lift between February and May was the largest of any surface, and the lift correlated almost linearly with the llms.txt restructure and the stat-density pass.
Google AI Overviews cited the second-most aggressively, with a median of 6 domains per answer and a strong bias toward citing the same set of top-tier publications across many answers (the New York Times, Wikipedia, well-known industry sites). The surface widened its citation pool meaningfully between February and May, which is what allowed forkoff.xyz to move from 23 to 35 percent. The pattern that drove the AI Overviews lift was the comparison-content density work, AI Overviews disproportionately reaches for comparison-formatted content when the underlying buyer prompt has a vendor-selection or evaluation shape.
ChatGPT cited at a median of 4 domains per answer when web search was active, and the citation set rotated less between repeat queries than Perplexity did. The 14-point lift from 18 to 32 percent tracked the llms.txt and AGENTS.md work most cleanly. ChatGPT's agent-fetch path explicitly looks for structured content directives, and the surface rewarded pages with clean token annotations more than the other four did. The conservative-citation behavior fades once a domain crosses a recognition threshold, and the rerun caught forkoff.xyz crossing that threshold between February and May.
Claude cited at a median of 5 domains per answer and was the most conservative on newer or less-recognized domains. The 8-point lift from 21 to 29 percent was the smallest of any surface, and the deltas tracked entity-disambiguation and quote-ready sentence work more than structural work. Claude weights well-formed standalone sentences higher than the other surfaces, which means the rewrite pass on load-bearing claims paid the highest dividend here. The Claude conservatism is real and structural, the implication for the next remediation sprint is that entity work and citation-friendly prose will keep moving Claude faster than llms.txt edits will.
Gemini cited at a median of 3 domains per answer and showed the narrowest citation pool of the five surfaces. The 7-point lift from 19 to 26 percent was the second-smallest, and the deltas tracked schema-graph completeness and Organization JSON-LD coverage more than any other axis. Gemini reaches into structured data more aggressively than the other surfaces, and pages with complete Service plus FAQPage plus Article plus Organization plus BreadcrumbList JSON-LD were measurably more likely to be cited than pages with partial schema. The implication is that the Gemini playbook is a schema playbook before it is a content playbook.
Princeton GEO research, mapped to the rerun
The Princeton KDD 2024 Generative Engine Optimization study tested six content strategies on a 10,000-query benchmark across five major AI surfaces and produced the first published ranking of citation-lifting tactics by quantified impact. Citing authoritative sources lifted AI visibility 115 percent for lower-ranked pages, statistics 41 percent, expert quotations 28 percent, fluency optimization 13 percent, citation-bearing claim density 7 percent, and easy-to-understand phrasing 4 percent. The ranking is the load-bearing artifact in the paper, and it is the artifact that maps most directly onto operational remediation work.
The rerun deltas line up with the Princeton ranking almost row-for-row. The two highest-impact Princeton tactics (citing authoritative sources, adding statistics) produced the largest lifts on the highest-source-diversity surfaces (Perplexity, AI Overviews). The mid-impact Princeton tactics (expert quotations, fluency optimization) produced the largest lifts on the conservative surfaces (Claude, AI Overviews). The low-impact Princeton tactics (citation-bearing claim density, easy-to-understand phrasing) produced uniform but small lifts across every surface. The pattern says the Princeton ranking is real and the per-surface differences are predictable from each surface's citation behavior. The operational implication is that the Princeton ranking is the prioritization heuristic to use when you have a fixed remediation budget, the per-surface citation behavior is the routing heuristic that tells you which tactic to apply to which surface first.
The Princeton paper also published a citation-position lift number that most operators miss. The same six tactics that lifted citation frequency also lifted citation positioning inside the answer, meaning a cited domain that ranked third inside the answer body moved to first or second after the remediation. Position matters because LLM users skim the top of an answer the way Google users skim the top of a SERP, the first cited domain captures attention disproportionately. We did not log positioning in the February run, we did log it in May, and the next rerun in August will give us the first paired positioning delta. The rerun cadence is what unlocks that next layer of measurement.
Building the remediation queue
The remediation queue is the artifact that turns the audit into actionable work. The 250-cell matrix produces three artifacts, the aggregate cite rate, the per-prompt cite map, and the queue. The queue is ranked by Δ-citation-cost, which is the ratio of estimated citation-rate lift to estimated remediation cost in analyst hours. Low-cost lifts go first, expensive lifts go later, and the queue is rerun after every cycle so the lift estimates compound on real data rather than guesses.
The queue has six column types. Prompt is the natural-language prompt the cluster runs. Surface is the AI surface where the prompt is blind or partial. Owner page is the existing forkoff.xyz page closest to the prompt or null if no existing page maps. Remediation type is one of the five patterns (structural readiness, stat density, quote-ready, comparison content, entity consistency). Estimated cost is in analyst hours. Estimated lift is a citation-rate delta projection based on prior remediation work. The cost-to-lift ratio is the queue's sort key, and the top 10 rows are what the next sprint executes.
The May rerun produced 38 remediation queue rows, 12 of which mapped to existing pages and were under 2 analyst hours of work each. Those 12 are scheduled into the June and July content cycles, and the August rerun will measure the lift those 12 produced. The remaining 26 rows include 5 new page builds (under the content-production queue) and 6 structural sweeps across content clusters that require a longer sprint. The queue is the single most important artifact for sustained AEO work, because the citation rate is the lagging indicator and the queue is the leading indicator that produces it.
The queue also exposes the diminishing-returns curve that operators run into around the 50 to 60 percent cite-rate mark. The first 10 to 15 points of lift come almost free from the structural readiness work. The next 10 to 15 points come from comparison-content density and stat-density passes. Past 40 percent the lift starts requiring per-prompt page builds that map exactly to the buyer language the cluster encodes, and past 55 percent the lift requires net-new entity definitions that may not exist anywhere on the site yet. The curve is steep at the top, which is why the rerun cadence matters more as the cite rate climbs, the late-curve lifts are smaller and harder to detect without a paired comparison.
The 5 patterns that drive AI citations in 2026
The same 5 patterns showed up in our rerun, in Cyrus Shepard's 22-factor list, in Princeton's KDD 2024 paper, in r/seogrowth and r/DigitalMarketing operator threads, and in the 23-site survey one operator ran across 14 months. The fact that the same 5 patterns appear independently across 5 different measurement methods is what makes them real. If the patterns were artifacts of one team's stack, they would not be replicating across this many independent labs.
The 5 patterns that drove the lift between runs
| Pattern | Where applied | Estimated contribution |
|---|---|---|
| llms.txt with token annotations + structured links | Site root, regenerated for all services + blog pillars | +4 pts avg |
| AGENTS.md authored as a dependency graph | Repo root, references service catalog | +2 pts avg |
| Comparison-content density (1 per 3 explainer) | Blog cadence, 6 new comparison posts in Q1 | +3 pts avg |
| Stat density 3 to 5 per 1,000 words | Top-25 pages by AI-channel referral | +2 pts avg |
| Quote-ready standalone sentences | Service + comparison pages | +1 pt avg |
The Reddit operator who runs as PastaPirate_ documented this independently in a thread that cleared 185 upvotes and 78 comments in r/DigitalMarketing. The exact testing method (200+ pages, citation-rate lift measured per pattern) overlaps almost perfectly with what our rerun produced. The pattern set is the same, structural readiness plus stat density plus quote-ready sentences plus comparison content plus entity consistency.
5 steps to get cited in ChatGPT (AI visibility)
The pattern hierarchy matters for sequencing. Structural readiness ships in a week and is the lowest cost, so it goes first. Stat density compounds page-by-page, so it goes second, prioritized by AI-channel referral volume. Quote-ready sentences ship as a content edit pass, so they go third. Comparison-content density is the highest-leverage and highest-cost item, so it ships continuously as part of the blog cadence rather than as a sprint. Entity consistency is the audit-and-fix sweep, which goes last because it benefits most from already-rewritten content.
FORKOFF citation count vs competitor agencies
We scored FORKOFF and 3 anonymized competitor agencies (referred to as Agency A, B, C, all in the AEO/GEO space, all with revenue between $1M and $10M ARR per their public statements) on the 4 axes that drove our citation rate lift, weighted by their estimated contribution to lift. The axes are llms.txt depth (token annotations + structured links, weight 0.25), stat density (verifiable stats per 1,000 words across landing pages, weight 0.30), quote-ready sentence rate (standalone citation-friendly claims, weight 0.20), and schema graph completeness (Service, FAQPage, Article, Breadcrumb, Organization JSON-LD coverage, weight 0.25). Scoring is 0 to 10 per axis on direct page inspection.

FORKOFF tops the scorecard with a 9.0 weighted total. Agency B is the closest at 4.5, followed by Agency A at 4.3 and Agency C at 3.2. The gap is large enough that we expect this to compress as the category matures, today the bar for "shipped the structural layer" is so low that just running the rerun puts an agency in the top quartile, in 12 to 18 months we expect the structural layer to be table stakes and the differentiation to move up the stack to per-prompt remediation, content-density at scale, and per-surface tuning. The competitor pattern we observed (high on quote-ready sentences but low on llms.txt + schema) is consistent with the "we did the content work but skipped the engineering" gap that is the single most common shape on the SERP today.
How to run your own citation audit
The audit playbook is short and copy-able. Step one, build the prompt cluster, 50 to 100 buyer-intent prompts in natural language, balanced across comparison, service definition, how-to, vendor selection, and tooling. Step two, fix the 5 surfaces (ChatGPT, Claude, Perplexity, Gemini, AI Overviews) and the run schedule (weekly or monthly minimum, quarterly for the formal rerun report). Step three, build the result matrix in a spreadsheet or database, per (prompt, surface) record cite-yes/no, source count, competitor citations. Step four, compute the per-surface cite rate and the per-prompt cite map. Step five, build the remediation queue ranked by Δ-citation-cost (which prompt is lowest-cost to win on which surface).
The structural answer engine optimization layer is the prerequisite. If your robots.txt blocks GPTBot, ClaudeBot, or Perplexity-User, no amount of content work will move the cite rate. If your llms.txt is missing or unstructured, the lower-cost crawl path agents take when they bypass JavaScript-rendered pages will skip you entirely. If your AGENTS.md is missing, agents that read it on session start (Codex, Claude Code) will not have a context map to your service catalog. The agents.md spec is the canonical reference for the file format. Ship those three files first, then start the cluster.
The semantic layer is the second prerequisite. Pages need to state clearly who you are and what you do. Buried entity definitions inside hero copy with no schema markup will not survive the first parse. Schema.org coverage for Service, FAQPage, Article, Organization, BreadcrumbList is the floor, the JSON-LD validates a clean entity graph that AI surfaces can pull from when they fetch the page. The llm-seo discipline is where this work lives.
The final layer is content density. The 3 to 5 stats per 1,000 words rule is the operator-tested floor that produced 2/10 to 8/10 citation rate lift in the PastaPirate_ thread, the rule generalizes because the LLM lifts standalone sentences word for word and statistical claims are the lowest-ambiguity sentences in any document. Quote-ready means every load-bearing claim is one sentence, one subject, one verb, one numeric or named-entity object, no parenthetical hedges, no buried causal chains. The rewrite pass is mechanical, the lift is real.
When you have the audit results, the rerun cadence is the part that makes it a lab. Monthly is the operator floor, quarterly is the business-review floor, and the per-surface delta over time is the artifact you ship into the quarterly review. Most teams will run the first audit, ship the remediation, and stop. The teams that compound run the second, third, and fourth reruns, log the deltas, and treat the perplexity-seo and ChatGPT subset as separate workstreams once the surface-level cite rates diverge enough to warrant per-surface playbooks. The Perplexity vs Google AI Overviews comparison is the reference for understanding where those workstreams differ before splitting the roadmap.
If you want managed delivery, the FORKOFF generative engine optimization service ships the 50-prompt cluster build, the per-surface baseline, the 4-week remediation, and the quarterly rerun cadence as one engagement. The ai-search-optimization discipline ships the broader umbrella that includes the structural plus semantic plus content layers. We also operate the ai-seo-services layer that ties the GEO/AEO citation work back into conventional SEO so the two surfaces compound together.
The next FORKOFF citation lab rerun is scheduled for 19 August 2026, same cluster, same 5 surfaces, same method. We will publish the Q3 delta the day the data comes in, and the rerun after that is November 2026. If the time-series methodology is the moat, the cadence is the moat-builder.













