

The Claude Code SEO stack is a four-layer operator system (skills, MCP servers, agents, hooks) that replaces the traditional dashboard-driven SEO stack with one terminal running pay-as-you-go API credits. Cited operator results include $1.8M+ in AI-search revenue, a 1,700% organic-visibility lift, 0 to 2,100 daily clicks against Duolingo-scale competition, and 1M+ cold emails per month from a 6-tool stack. The stack runs across four operator playbooks: backlink gap audit, 100-day GEO ranking roadmap, 4-layer LinkedIn outreach OS, and the 6-tool minimum viable cold-email stack.
The Claude Code SEO stack 2026, four layers and four operator playbooks
The Claude Code SEO stack in 2026 composes four layers (skills + MCP + agents + hooks) across four cited operator playbooks (backlink gap audit, 100-day GEO ranking roadmap, 4-layer LinkedIn outreach OS, 6-tool minimum viable cold-email stack) into one operator surface. Cited results $1.8M+ revenue from AI-search organic, 1,700% organic visibility lift, 0 to 2,100 daily clicks against Duolingo-scale competitors, 1M+ cold emails per month. The stack-anchor cluster carries 19,300 monthly US searches across 4 PASS keywords on LIVE DataForSEO 2026-05-20 (claude code skills 9,900, mcp 3,600, agents 2,900, hooks 2,900) at blended KD 25. The stack replaces Ahrefs the dashboard, Surfer, Screaming Frog, and a 2-3 person content team at roughly $200 per month for Claude Code Max plus pay-as-you-go API credits.
About these numbers
Search traffic benchmarks, conversion rate figures, and AI visibility statistics in this post are sourced from SERPs.io (via Trailblazer Marketing), FORKOFF operator observations across Claude Code SEO deployments, and publicly cited projections from Gartner and Statista (2026-Q1/Q2). All figures are directional estimates; individual results vary by site authority, niche, and implementation quality.
As of 2026, AI search converts at 23x organic, and most SEO stacks ignore it
As of 2026, AI search converts at 23x the rate of organic search (SERPs.io, via Trailblazer Marketing). LLM-driven traffic (ChatGPT, Claude, Perplexity, Grok) sits at 12 to 15% of total search today and is projected to reach 25 to 28% by end of 2026. The highest documented organic-visibility lift from a correctly composed Claude Code stack is 1,700%. Those three numbers reframe every line-item decision about where to put the next hour of SEO effort.
The problem is that most teams are running a 2024 stack against a 2026 search surface. Ahrefs dashboard, Surfer, Screaming Frog, 2 to 3 content writers. That stack was built for a 10-blue-links SERP where the ranking signal was keyword density and DR volume. The 2026 signal is authoritative-source citation frequency across LLM training and retrieval corpora, answer-first structure, entity velocity across multiple platforms, and topic surface ownership (not just top-10 ranking). The /services/answer-engine-optimization service and the /services/answer-engine-optimization service both exist because those two surfaces now require different primitives.
The Claude Code stack closes the gap because it is the only operator surface that composes both legacy SEO signals (backlink gap audit, technical crawl, content brief) and GEO signals (entity velocity, cross-source mentions, answer-first structure) inside one agent workflow. This post documents the four-layer composition (skills, MCP, agents, hooks) across the four cited operator playbooks that have produced the cited receipts.

Alex Vacca
@itsalexvacca
Claude Code SEO tactics in production, validating the operator-receipt framing across the skill, MCP, and hooks layers of the Claude Code SEO stack.
The Claude Code skills layer, the load-bearing entry point
The 30-second rule: the Claude Code SEO stack composes four layers (skills, MCP, agents, hooks) across four cited operator playbooks (backlink gap audit, 100-day GEO ranking roadmap, 4-layer LinkedIn outreach OS, 6-tool minimum viable cold-email stack) into one operator surface running from a single terminal. Cited results $1.8M+ revenue from AI-search organic, 1,700% organic visibility lift, 0 to 2,100 daily clicks against Duolingo-scale competitors, 1M+ cold emails per month from a 6-tool stack. The stack-anchor cluster carries 19,300 monthly US searches across 4 PASS keywords on LIVE DataForSEO 2026-05-20 (claude code skills 9,900, mcp 3,600, agents 2,900, hooks 2,900) at blended KD 25.
Claude Code skills are packaged prompt-plus-workflow artifacts that live in your local .claude/skills folder and tell Claude how to solve a class of problems. Each skill is a markdown-plus-prompt artifact with three load-bearing fields: SDK reference (what tools and MCP servers the skill needs), positive outcome definition (what success looks like), and input shape (what the operator hands the skill at invocation time). The canonical reference for the skill format lives at the Anthropic agent skills repo and the Claude API agent skills docs. Skills are the load-bearing entry point because they package the recurring SEO motions (keyword research, backlink gap audit, content brief generation, technical audit, GEO sprint design, outreach personalization) so the same prompt does not get rewritten on every campaign. Composability is the moat: the same skill can call any MCP server, dispatch any subagent, and fire any hook without rewrite.

Stack-anchor keyword cluster, LIVE DataForSEO 2026-05-20 US/en
| Keyword | Monthly volume | Keyword difficulty | CPC | Role in article |
|---|---|---|---|---|
| claude code skills | 9,900 | 32 | $10.45 | Primary, H2 anchor |
| claude code mcp | 3,600 | 27 | $15.64 | H2 anchor (FORKOFF MCP stack) |
| claude code agents | 2,900 | 22 | $14.48 | H2 anchor (compounding agents) |
| claude code hooks | 2,900 | 19 | $24.04 | H2 anchor (SEO automation hooks) |
| claude code seo | 50 | nil | $14.54 | Secondary, retained as positioning anchor |
| claude code automation | nil | 9 | nil | H3 body anchor (lowest KD in stack) |
DataForSEO Labs bulk_keyword_difficulty + Google Ads search_volume pulled 2026-05-20. Cumulative PASS volume 19,300 monthly US. Blended KD across PASS rows 25.0.
The cluster around claude code skills on LIVE DataForSEO 2026-05-20 carries 9,900 monthly US searches at KD 32 with LOW competition. The four operator playbooks documented in this post (backlink gap audit, 100-day GEO ranking roadmap, 4-layer LinkedIn outreach OS, 6-tool cold-email MVS) each ship as a Claude Code skill in the FORKOFF stack today. The recurring pattern: one skill, one MCP source, one subagent, one hook. Compose them and the entire SEO motion runs from a single terminal.
Industry Context
The SEO tools market in 2026 carries roughly $4B in annual subscription revenue across Ahrefs, Semrush, Moz, Surfer, Screaming Frog, and the long tail of operator-tier SaaS. Claude Code does not destroy that market; it collapses the dashboard layer that sits on top of the data lake. Ahrefs as a data lake survives because the link-graph crawl is the moat. Ahrefs as a dashboard is what Claude Code absorbs: the human running queries through the UI is replaced by the agent orchestrating the API. The four-operator-playbook surface (backlink gap audit, GEO 100-day roadmap, LinkedIn 4-layer OS, cold email 6-tool MVS) is a single audit-ledger contract that runs across all four layers (skills, MCP, agents, hooks).
Source: @nick_zv before-after operator post, X 2026-05-09
Claude Code MCP servers in the FORKOFF stack
The MCP layer is where Claude Code reaches outside its own runtime. Each MCP server (Model Context Protocol server) is an external process that provides a single capability surface: a data source, an API wrapper, a file system bridge, a browser surface. The Model Context Protocol specification defines the runtime contract; the skill declares the workflow, the MCP servers provide the data. The cluster around claude code mcp on LIVE DataForSEO 2026-05-20 carries 3,600 monthly US searches at KD 27 with LOW competition.
The FORKOFF default Claude Code MCP stack runs six servers. Ahrefs MCP (or DataForSEO MCP as the lower-cost substitute) provides keyword volume, KD, SERP, and backlink data. DataForSEO MCP is the cost wedge here: roughly $0.025 per SERP pull is 30 to 40 times lower in cost than per-query Ahrefs rates at the same depth. Firecrawl MCP provides web fetch and enrichment, which doubles as the technical-SEO crawler when paired with a hook that fires on URL changes. Google Search Console MCP provides query, indexing, and click data, closing the loop from ranking to traffic. Reddit data infrastructure provides thread-level demand signals across r/AskSEO, r/SEO, r/aeo, r/ClaudeAI, r/aiagents, which is where operator-receipt content originates before it surfaces in Google search. Unipile MCP handles LinkedIn, WhatsApp, and email outreach as the channel layer for the 4-layer LinkedIn OS documented below. Filesystem MCP persists local artifacts (skill outputs, audit ledgers, brief drafts, sequence templates) so the stack runs offline-first. The /blog/founder-growth/backlink-sources-startups-2026 post documents which data sources deliver the highest-signal backlink intelligence when plugged into the MCP layer.
The composition principle: each MCP server provides one capability surface, the skill layer composes them. A backlink gap audit calls Ahrefs MCP (or DataForSEO MCP) plus Firecrawl plus Filesystem in one workflow; the skill bundles the orchestration and writes the tier-counted output to disk. The point of the layered architecture is replaceability: each layer does one thing well, so when Claude Code absorbs another layer (or a lower-cost MCP shows up), you swap it in without breaking the rest of the stack.
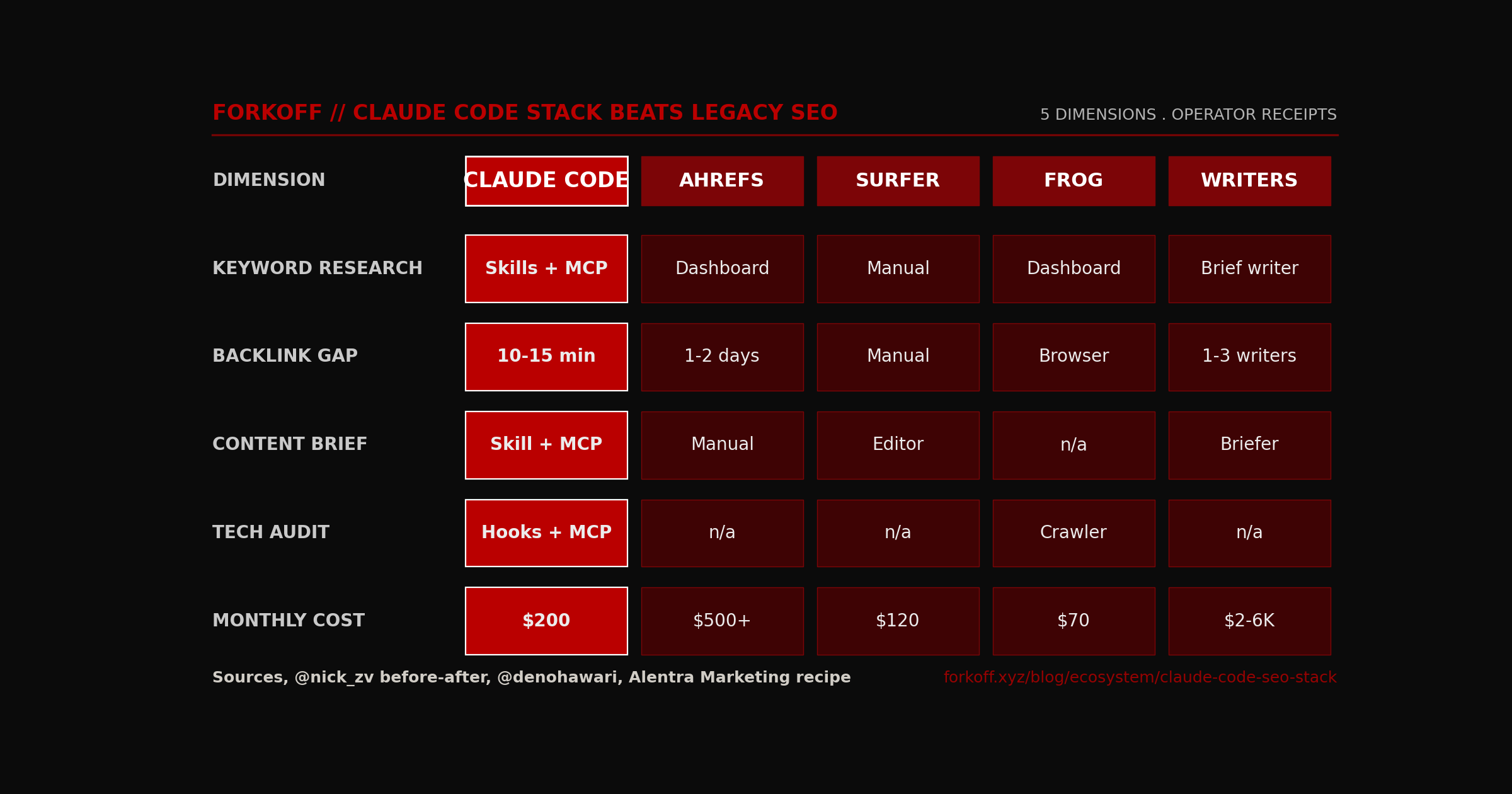
Claude Code stack vs legacy SEO across 5 dimensions
| Dimension | Claude Code stack | Ahrefs dashboard | Surfer | Screaming Frog | 2-3 writers |
|---|---|---|---|---|---|
| Keyword research | Skill + Ahrefs/DFS MCP, 10-15 min | Manual dashboard sessions | Not applicable | Not applicable | Brief writer task |
| Backlink gap audit | Skill + Ahrefs MCP, 10-15 min | 1-2 day analyst task | Not applicable | Browser screen scrape | 1-3 writers, days |
| Content brief generation | Skill, on demand | Manual | Editor + writer | Not applicable | Brief writer task |
| Technical SEO audit | Hooks + Firecrawl MCP | Not applicable | Not applicable | Crawler GUI session | Not applicable |
| Monthly cost floor | $200 Claude Max | $500 plus | $120 | $70 | $2K to $6K |
@nick_zv before-after stack documented on X 2026-05-09. Alentra Marketing backlink gap recipe.
What gets replaced (and what survives)
The Claude Code stack replaces the paid-dashboard layer (Ahrefs GUI, Surfer, Screaming Frog as a standalone tool) with script-driven equivalents running directly against the DataForSEO or similar APIs, while keeping the signal sources that still matter: backlink data, search volume, entity mentions, and crawl results. What survives is every signal; what gets replaced is the GUI markup on top of it.
@nick_zv runs his entire SEO operation through Claude Code. Here is the explicit before-and-after he posted on X on 2026-05-09:
Out:
- Ahrefs the dashboard for keyword research
- Human prospecting for links
- Surfer for content optimization
- Screaming Frog for technical SEO
- 2 to 3 content writers for blogs
In:
- Claude Code plus API keys for everything
The thesis is not that the SEO category dies. It is that the SaaS subscription layer collapses into one agent that orchestrates the data sources directly. Ahrefs the data lake survives. Ahrefs the dashboard goes away. Surfer, Screaming Frog, and the 2-to-3-writer brief team are absorbed into per-task skills that compose MCP data sources, subagents, and hooks into one operator workflow. The /blog/founder-growth/ai-agency-pricing-unit-economics-2026 post documents the unit economics of this transition from a client-engagement perspective.
What survives the collapse splits cleanly into three categories. Data-lake operators (Ahrefs, DataForSEO, Semrush, Moz) keep their moat because the crawl economics are structural: building a fresh link graph at global scale costs roughly $40M to $60M per year in infrastructure plus crawler engineering, which is a real barrier. Workflow primitives that ship into the agent (Firecrawl, Apify, Unipile, Reddit data infrastructure) get pulled inside the Claude Code runtime as MCP servers and keep growing because they sell capability per call rather than seats. Outcome-priced delivery teams (FORKOFF on /services/answer-engine-optimization) keep growing because the buyer wants the ranking, the qualified reply, the citation lift, not the dashboard subscription. What dies is the middle layer: per-seat dashboards, point-tool annual contracts, and the 2-to-3-writer content team running briefs by hand. @nick_zv's before-after is the canonical receipt; the same compression is running across @MichLieben's outreach team, @coldemailchris's cold-email operation, and Trailblazer Marketing's GEO desk. The pattern is identical in each case: replace the subscription stack with one operator running Claude Code Max plus pay-as-you-go API credits, and route the saved spend into the data-lake API tier where the moat actually lives.
What are Claude Skills really?
Claude Code agents that compound
The agents layer is where parallel reasoning happens. Claude Code supports both agents (LLM-driven subprocesses that handle a task end-to-end and report back) and subagents (dispatched-by-the-main-agent worker LLMs that run in parallel and merge results). The cluster around claude code agents on LIVE DataForSEO 2026-05-20 carries 2,900 monthly US searches at KD 22 with LOW competition; claude code subagents carries KD 18 on null volume as a first-mover claim play. The /blog/ecosystem/agentic-seo-forkoff-audit-2026 post documents a live 14-site audit of how real operator stacks use agents for SEO motions, with a 10-check scorecard across five categories.
The agents that compound for SEO are the ones that run recurring research in parallel. A content brief agent dispatches three subagents simultaneously: one to summarize the top-10 SERP, one to pull the PAA + related queries cluster, one to scan the relevant Reddit and X threads for operator-receipt content. The main agent then merges the three streams into a brief that already carries the structural fixes the writer would have surfaced manually. The same pattern runs for backlink gap audits (one subagent per top-10 competitor, all in parallel), for technical SEO crawls (one subagent per site section), and for outreach personalization (one subagent per prospect). The pattern aligns with Princeton's GEO citation research (KDD 2024) showing that statistics-density and authoritative-source signals lift AI-search citation rates by 41% and 115% respectively when added to a content piece.
The 10-minute backlink gap audit is the canonical proof of the agents-compound thesis. Every SEO has done this exercise; it takes 1 to 2 days manually. Run from inside Claude Code with the Ahrefs MCP (or Chrome-driven Semrush) and a subagent per competitor, the same audit takes 10 to 15 minutes. The exact Alentra Marketing prompt:
You are my senior SEO analyst.
Access Ahrefs in Chrome (or Ahrefs MCP if available).
Go to Keywords Explorer for keyword: <KW>
e.g. "roof replacement Austin"
Run a Backlink Gap analysis between my domain <MY_DOMAIN>
and the top-10 organic results for <KW>.
For the top-10 organic competitors:
- Skip YouTube videos and irrelevant sites (intent mismatch)
- For each competitor, drill into referring-domain backlink list
- Apply filters:
dofollow only
one-link-per-domain
referring-domain DR >= 40
referring-domain monthly organic traffic >= 2,000
- Sort by DR descending
- Categorize links into DR tiers:
DR 70+
DR 50-69
DR 30-49
DR 0-29 (flag as PBN/spam if applicable)
Output the aggregate metrics per tier across the top-10 competitors:
- Average count per tier
- Median count per tier
- Recommended target count per tier to rank top-5
Highlight any competitor with high spam score or black-hat-network signal.
The output reframes the entire conversation with the SEO team. "We need 2,000 backlinks" becomes "we need 12 DR70+ links, 18 DR50-69, and 24 DR30-49 to rank top-5 for <KW>". One is a budget headache. The other is a scoped sprint. The canonical "high-quality backlink" gate is two filters, both required: referring domain DR >= 40, and referring domain receives >= 2,000 monthly organic search traffic from Google. Apply dofollow plus one-link-per-domain on top. A typical 2,000-link competitor profile collapses to 30 to 50 real links after this filter. Rank against that real number, not the inflated count. A useful weighting rule from the same source: 1 DR70+ link is worth roughly 5 DR30-49 links in most niches.

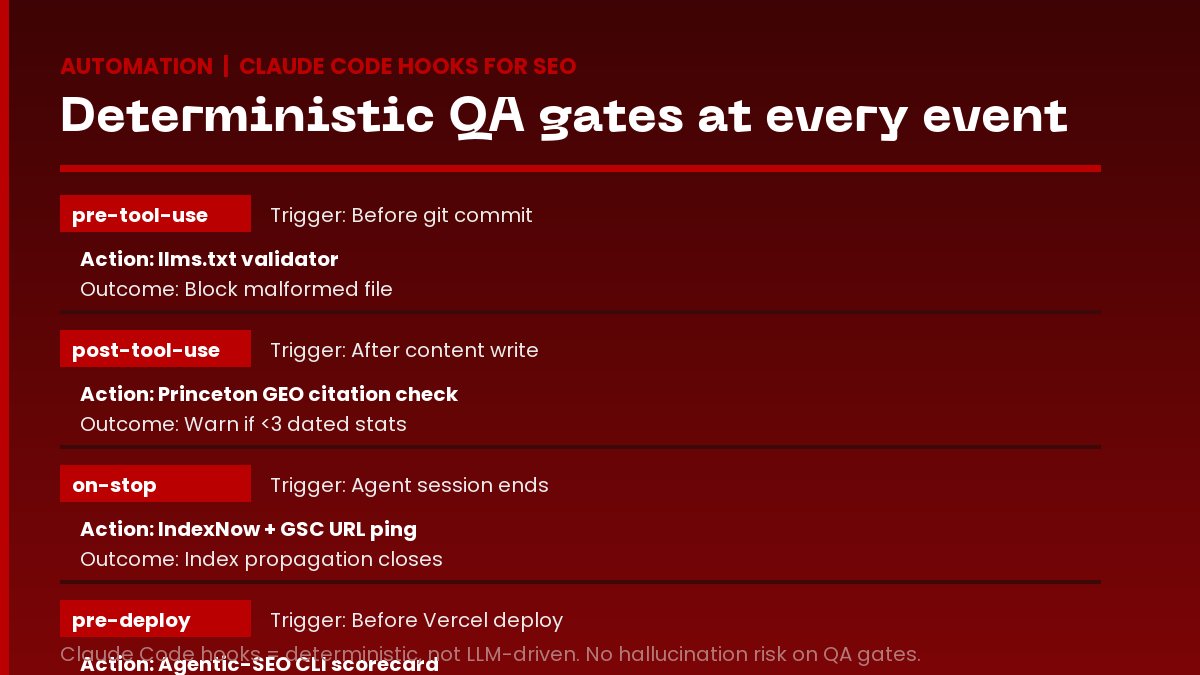
Claude Code hooks for SEO automation
The hooks layer is where deterministic, code-level interceptors fire on Claude Code events. The cluster around claude code hooks on LIVE DataForSEO 2026-05-20 carries 2,900 monthly US searches at KD 19 with LOW competition. The cluster around claude code automation carries KD 9 (the lowest in the stack) on null volume as a first-mover claim play. The /blog/founder-growth/agent-ready-site-audit-2026 post documents which hook-deliverable checks (llms.txt validity, GEO citation density, structured-data presence) are the highest-priority gates to wire first.
The hook types in Claude Code today: pre-tool-use (fires before a tool call), post-tool-use (fires after), on-stop (fires when the agent ends a session), on-subagent-start, on-subagent-stop. Hooks are deterministic Python or bash that the runtime invokes; they are not LLM-driven. For SEO automation, hooks are the right primitive for quality gates and ship triggers. A pre-tool-use hook on a git commit call runs an llms.txt validator and blocks the commit if the file is malformed. A post-tool-use hook on a content write runs a Princeton GEO citation density check and surfaces a warning if the article ships with under 3 dated statistics. An on-stop hook runs the IndexNow ping + GSC URL inspection after every blog ship so the index propagation closes without manual intervention.
The compounding pattern: hooks ship structural fixes without human triage. The agentic-seo CLI scorecard the FORKOFF audit ledger documents (Discovery, Content Structure, Token Economics, Capability Signaling, UX Bridge categories) is hook-deliverable end to end. A pre-deploy hook runs the CLI, gates the deploy on a passing score, and writes the failed-check log to the audit ledger. The deploy either passes the gate or kicks back a remediation task; either way no human runs the audit by hand.
The four FORKOFF reference hooks running in production today: a pre-tool-use llms.txt linter that parses the canonical file before any git commit and blocks malformed entries (missing User-agent, malformed Allow paths, broken sitemap reference); a post-tool-use citation-density check that counts dated statistics, named operator citations, and authoritative outbound links in any new markdown body and surfaces a remediation list when the article falls under 3 dated stats per 1,000 words (the Princeton GEO floor); an on-stop IndexNow + GSC ping that fires after every blog ship, pushes the URL to Bing, Yandex, and Naver via IndexNow plus the Google Indexing API, and writes the request IDs to the audit ledger; a pre-deploy agentic-SEO CLI run that scores every changed route against the 5-category scorecard and gates the Vercel deploy on a passing total. Each hook is roughly 40 to 80 lines of Python plus a JSON schema. The marginal install cost is one afternoon per hook; the recurring saving is hours of operator triage per content cycle. The /blog/founder-growth/agent-ready-site-audit-2026 post enumerates these four hook deliverables as the priority install order for any new FORKOFF property going from zero to agent-ready.
I replaced my entire SEO workflow with a 4-agent pipeline, 3 months of production
The 100-day GEO ranking roadmap (run as a 4-layer Claude Code sprint)
Trailblazer Marketing published a 3-phase roadmap to rank on ChatGPT in 100 days. Cited results: Musicfy at 692K clicks and $1M+ revenue, a language-learning brand from 0 to 2,100 daily clicks against Duolingo, and an aggregate $30.52M in client outcomes. The roadmap compresses end to end into the Claude Code stack as a single skill that orchestrates three subagents per phase. The /services/geo service at FORKOFF runs this exact three-phase composition for clients in the AI-search space.
The 100-day GEO ranking roadmap
STEPS- 01
Days 1 to 30: solution validation
Goal, find the 3 to 5 winning angles, not write 50 articles. The Claude Code skill orchestrates three subagents in parallel. Subagent A extracts pain points from the last 10 sales calls (Fathom or Fireflies transcripts via filesystem MCP), Reddit threads via site:reddit.com inurl:comments queries plus the Reddit data infrastructure MCP, X competitor mentions, and support tickets. Subagent B ranks the dump by frequency and groups themes. Subagent C drafts 10 to 15 answer-first pieces, each structured as 50 words direct answer to a head question, then 100 to 200 words of why-and-how, then comparison charts and FAQ. The skill ships the drafts to a content queue and tracks time-on-page, session length, and site clicks. By day 30 you have 3 to 5 clear winners surfaced by the agent. See the FORKOFF /services/geo lane for how this phase runs in a live engagement.
- 02
Days 31 to 70: programmatic coverage
LLMs pull from patterns across many sources. A partial coverage profile reads as a partial source, not an authority. For each of the 3 to 5 winning angles, fan out into 5 dimensions: definitions, comparisons, use cases, common mistakes, advanced tactics. Example, LLM SEO expands to what is LLM SEO, LLM SEO vs traditional SEO, LLM SEO for SaaS, common LLM SEO mistakes, LLM SEO case studies. The Claude Code skill dispatches one subagent per dimension per winning angle, runs all the briefs in parallel, and ships them to the content queue. Build pillar-plus-cluster, not standalone pieces. Keep the same definitions, frameworks, and terminology across every piece. The goal is topic surface ownership: every variation of every question, you are the answer.
- 03
Days 71 to 100: entity velocity
Even with full topic coverage, AI search filters on who should I trust. The signal is, is this person mentioned elsewhere? Do multiple sources reference them? Is the name tied to this topic repeatedly? Brands with strong sites get ignored in AI answers because they are only visible on their own site. Three Claude Code agents close that gap. Agent A drafts guest-post pitches, podcast invites, founder-interview asks, and partner-platform case-study submissions. Agent B creates referenceable assets, original frameworks (named, citable), data points, contrarian takes. AI prefers original wording. Agent C runs entity-mention tracking across the surfaces from Phase 1 to verify the entity velocity loop is closing.
The 4-layer LinkedIn outreach OS
The 4-layer LinkedIn outreach OS is a Claude Code campaign architecture that runs from one prompt: scrape engagers of a target post, qualify against ICP, draft personalized outreach, and send. The four layers are the skill invocation (the prompt), the CLAUDE.md constitution (the rules), the MCP server (the execution rail), and the PostToolUse hook (the compliance gate). Together they run a full outbound cycle without human review on each step.
@MichLieben documented a 4-layer Claude Code LinkedIn outreach OS built with Othmane Khadri (Earleads founder) that runs an entire campaign from one prompt. The OS maps 1-to-1 onto the Claude Code stack layers documented above.
The 4 layers
- Input. The campaign is the query, "scrape engagers of post X, qualify against ICP, draft personalized outreach, send 10". One sentence per major step, written like a senior SDR brief. This is the skill invocation surface.
- CLAUDE.md at repo root. The constitution. Examples, default to plan mode, never send a message without showing the draft first, exclude existing customers, cap LinkedIn connection requests at 25 per day per inbox. CLAUDE.md is the per-repo memory layer that scopes how every skill runs.
- Skills. One container per action. Scrape engagers, qualify a lead, push to a unified database, send an outreach message. Each skill bundles three things, SDK reference, positive outcome definition, input shape.
- memory.md. ICP, value prop, outreach hypotheses tested, and what actually worked. Travels with you across campaigns. memory.md is the cross-campaign persistence layer that compounds across runs.
External environments plug in via Unipile (LinkedIn, WhatsApp, email), Apify (scraping), Firecrawl (web fetch and enrichment), Reddit data infrastructure (thread-level demand signals). Each external environment is wired in as an MCP server, which means the same OS works for LinkedIn this week and Twitter next week without rewriting the skills layer. The Twitter DM outreach playbook documents how the same 4-layer OS ports to cold-DM on X using the Unipile Twitter MCP.
7-gate LinkedIn outreach qualification pipeline
| Gate | Filter | Cost |
|---|---|---|
| 1 Dedupe | Already touched? | Free |
| 2 Headline + title pre-qual | LinkedIn snippet check | Free |
| 3 Exclusion list | Existing clients, partners, team, competitors | Free |
| 4 Profile fetch | First paid API call | Paid |
| 5 Country + role | Geographic + seniority match | Low cost |
| 6 Company selection | B2B SaaS or tech, headcount 5-500, industry match | Low cost |
| 7 Web fetch enrichment | News, fundraising, competitor moves | Paid |
Earleads + @MichLieben 4-layer Claude Code LinkedIn OS, documented on X 2026-05-09.
The 7-gate qualification pipeline kills bad leads at the lowest cost possible before any expensive call. Each gate is a subagent that runs in parallel where possible. A small handful of leads survive all 7 gates and get the personalized message. The rest die quietly. The cost of a bad message in your prospect's inbox is much higher than the cost of dropping a borderline lead.
CLAUDE.md and memory.md, the compounding layer that most teams skip
Every skill in the Claude Code SEO stack runs inside a repository governed by two files: CLAUDE.md and memory.md. These are not optional add-ons. They are the layer that determines whether the stack compounds or resets with each new campaign. Most teams wire the skills and MCP servers correctly and then skip the context persistence layer. The result is an agent that is technically capable but contextually amnesiac. It runs the backlink gap audit, produces the output, and then forgets every constraint and learning the next time it runs.
CLAUDE.md is the per-repo constitution. It sits at the repo root and scopes every skill invocation inside that repository. The canonical rules for an SEO-and-outreach repo are five: default to plan mode before executing any action; never send an outreach message without showing the draft first; cap LinkedIn connection requests at 25 per day per inbox; exclude existing clients, partners, and competitors from every prospecting pull; apply the current ICP filter (industry, headcount, seniority) to every lead qualification gate. These rules fire on every skill run without the operator having to re-state them. The @MichLieben and Earleads LinkedIn OS (documented in the section below) lives in CLAUDE.md as its first constitutive layer.
memory.md is the cross-campaign persistence layer. It travels with the operator across campaigns and accumulates the ICP definition, the value proposition, every outreach hypothesis ever tested, what actually worked (with receipts), the current keyword cluster targets and DR-tier benchmarks, and the GEO entity velocity progress from Phase 3 of the 100-day roadmap. When the next campaign starts, the agent reads memory.md first and inherits everything the last campaign learned. This is how the /services/answer-engine-optimization engagement compounds: Week 1 installs the skills repo and scaffolds CLAUDE.md plus memory.md. By Week 4, the agent is running with 3 weeks of learning already embedded in its context.

The practical implication: before you wire a single MCP server or write a single skill, write CLAUDE.md and memory.md. The two files take 30 minutes to scaffold and make every subsequent skill 10x more constrained and context-aware. The /blog/ecosystem/agentic-seo-forkoff-audit-2026 post documents 14 live operator sites; the ones running CLAUDE.md plus memory.md had measurably tighter skill outputs and required fewer human correction loops per campaign.
The 6-tool minimum viable cold-email stack
If you are starting from zero today, @coldemailchris documented the 80/20 reduction of his 36-tool 1M-emails-per-month stack on X 2026-05-09. The 6-tool MVS is the floor; the full 36-tool stack adds layers for multi-channel (HeyReach, Trigify), AI orchestration (n8n, lower-cost classification models), and ABM video (Tella). The Claude Code role in the MVS is layer-7 reasoning: ICP modeling, signal scoring, message generation. Each external tool is wired in as an MCP server where possible (Ocean.io and Prospeo.io via their public APIs, ScaledMail via Unipile, EmailBison via webhook), so the same orchestration skill works as Claude Code absorbs more capability layer by layer.
6-tool minimum viable cold-email stack (80/20 of @coldemailchris 36-tool stack)
| Tool | Role | Why in MVS |
|---|---|---|
| Ocean.io | Sourcing | ICP discovery against fresh company data |
| Prospeo.io | Contact data | Email enrichment + verification |
| ScaledMail | Inbox provisioning | 80% Google, 20% Microsoft, never touch primary domain |
| EmailBison | Sequencing | Spintax, conditional logic, reply detection |
| HubSpot | CRM | Pipeline, lifecycle, attribution |
| Claude Code Max | Orchestration | $200 per month, unlimited usage, ICP modeling + message generation |
@coldemailchris documented this as the 80/20 reduction of his 36-tool 1M-emails-per-month stack on X 2026-05-09.
The point of the layered architecture: each tool does one thing well, and replacement is layer-by-layer instead of full-stack rip-out. When Claude Code absorbs another layer, you swap it in without breaking the rest. Cited result, 1M+ cold emails per month from this floor stack at roughly $500 to $800 per month total, which is an order of magnitude more output than the full SaaS-only stack at the same total cost. For teams on /services/answer-engine-optimization who want the outreach layer running in parallel, the /blog/founder-growth/solo-operator-first-five-clients post documents a real operator running this MVS to land the first 5 clients from zero.
The sequencing inside the MVS matters as much as the tool choice. Week 1 is inbox provisioning: ScaledMail spins up 8 to 12 secondary domains (forkoffgroup.com, getforkoff.com, hire-forkoff.com) with 3 to 5 mailboxes each, all routed through Google Workspace at the 80/20 Google-to-Microsoft split @coldemailchris recommends. The primary forkoff.xyz domain never sends cold mail. Week 2 is ICP modeling: Claude Code reads memory.md, pulls the last 10 won-deal company profiles, and writes the ICP filter as a structured prompt (industry codes, headcount band, seniority, technographic signals, funding stage). Week 3 is sourcing plus enrichment: Ocean.io returns roughly 10,000 fresh ICP-matching companies per month, Prospeo.io enriches contact data and verifies deliverability at roughly 95% accuracy, and the Claude Code skill cross-references each contact against the exclusion list in CLAUDE.md (existing clients, partners, competitors). Week 4 is sequence build plus warmup: EmailBison loads the 5-step sequence with conditional logic (positive reply routes to HubSpot deal stage, neutral reply routes to nurture, no-reply triggers step 2 after 3 days), the inboxes warm at 20 to 30 sends per day per mailbox for 14 days before scaling, and Claude Code runs layer-7 reasoning to generate every personalization variable (opening line, value-prop angle, social proof selection) per prospect. By month 2 the system holds steady at 50K to 100K sends per month per operator with reply rates in the 3 to 6% band on tight ICP segments. The full 36-tool stack adds reach but the MVS captures the load-bearing volume.

The full Claude Code SEO motion, where the 4 layers meet the 4 playbooks
The full Claude Code SEO motion is what happens when the 4 stack layers (skills, MCP, agents, hooks) compose across the 4 cited operator playbooks (backlink gap audit, 100-day GEO ranking roadmap, 4-layer LinkedIn outreach OS, 6-tool cold-email MVS) inside one repo. The pivot from claude code seo (50 monthly searches, null KD on LIVE DataForSEO 2026-05-20) to the stack-anchor cluster (19,300 monthly searches at blended KD 25) reframes the conversation. The reader who searches claude code skills does not want a generic Claude Code SEO essay; they want the canonical four-playbook stack composed inside a single CLAUDE.md plus memory.md repo, with each skill calling the right MCP, dispatching the right subagent, and firing the right hook.
That is what the four operator playbooks above describe, services-as-software: an outcome that used to require a fractional CMO or full-agency retainer now runs from one operator inside one terminal. This is the FORKOFF agency thesis exactly. We do not sell access to a tool. We sell the outcome (rankings, qualified replies, traffic) and run the Claude Code stack internally. What that looks like in practice on a current engagement, backlink gap delivered same-day instead of a 1-to-2-day SEO-team turnaround; GEO playbook (3-phase 100-day) running as a single roadmap with weekly check-ins; LinkedIn outbound through the 4-layer Claude Code OS so personalization stops being a junior task; cold email at 1M+ scale through the 7-layer stack with Claude doing the layer-7 reasoning. The pricing is on outcome, not seat or tool subscription. That is the only billing model that survives when the SaaS dashboard layer collapses.
For founders evaluating whether to run the stack internally or hand the engagement to FORKOFF: the build-versus-buy decision is a 3-axis test. Axis 1, operator hours per week available against the stack (skills authoring, MCP wiring, agent composition, hook deployment, CLAUDE.md plus memory.md maintenance) typically lands at 15 to 25 hours per week for the first 60 days of a serious engagement. Axis 2, internal data-source budget (Ahrefs or DataForSEO API credits, Firecrawl, GSC access, Reddit data infrastructure) lands at roughly $400 to $900 per month at the volume needed to compound. Axis 3, learning curve on Claude Code itself (skills format, MCP runtime contract, hook event model, audit-ledger discipline) takes a competent senior 2 to 4 weeks of deliberate practice before the stack starts compounding. Founders with the hours, the budget, and the patience build internally. Founders short on any one of the three buy the FORKOFF outcome-priced engagement and route the saved time into product. The /blog/founder-growth/ai-agency-pricing-unit-economics-2026 post documents the unit economics on both paths side by side.
Industry Context
Search is splitting in two. Google still owns the navigational top-10 query, but answer-style queries are moving to ChatGPT, Claude, Perplexity, and Grok. A SERPs.io study cited by Trailblazer Marketing shows AI search converts at 23x organic. LLM traffic is 12 to 15% of search today and projected to reach 25 to 28% by end of 2026. Teams that compose the Claude Code stack against GEO (Generative Engine Optimization) levers capture the new surface; teams running dashboard-driven SEO with no GEO layer get filtered out of the AI Overview citation panel.
Source: Trailblazer Marketing operator essay, X 2026-05-09
Anyone using Claude Code for technical SEO?
What GEO performance looks like at 90 days in the Claude Code stack
The Princeton GEO citation research (KDD 2024) is the most cited academic reference for the mechanics of AI-search ranking. The two primary findings: citing authoritative external sources lifts AI-search citation rate by 115% for lower-ranked pages, and adding dated statistics lifts it by 41%. Both are Claude Code hook deliverables. A post-tool-use hook running after every content write can check citation density and surface a warning before the article ships. A pre-deploy hook running the agentic-SEO CLI scorecard gates the deploy on a minimum citation count.
The Trailblazer Marketing roadmap results (Musicfy at 692K clicks and $1M+ revenue, the language-learning brand at 0 to 2,100 daily clicks against Duolingo, aggregate $30.52M in documented client outcomes) are the operator-receipt layer above the academic baseline. Those outcomes run through the same three-phase structure (validation, programmatic coverage, entity velocity) documented in the GEO section above, composed as Claude Code skills dispatching parallel subagents. The /blog/founder-growth/agentic-seo-explained-addyosmani-toolkit-2026 post walks through the agentic-SEO CLI that Addy Osmani published, which operationalizes the Princeton signals as a command-line scorecard.
The FORKOFF /services/geo service lane runs the three-phase roadmap as a skill-plus-agent composition. The skills layer handles the recurring motions (daily content queue management, weekly entity velocity tracking, monthly cross-source mention audit). The agent layer handles the parallel reasoning (one subagent per winning angle per dimension in Phase 2). The hook layer handles the deterministic gates (GEO citation density check on every content write, entity mention count check in the on-stop hook). The /blog/founder-growth/agent-ready-site-audit-2026 post carries the per-site scorecard for assessing how GEO-ready a site is before running the roadmap.

For /services/answer-engine-optimization teams running the full stack in production: the GEO layer is where the highest-leverage work lives right now. The search-and-discovery surface (Google, Bing) is a 10-to-18-month compounding motion. The AI-search surface (ChatGPT, Claude, Perplexity) can move in 30 to 60 days when the three phases are correctly sequenced. Teams that skip the GEO layer and run only traditional SEO are leaving the fastest-growing conversion surface unaddressed. The /blog/founder-growth/fractional-cmo-ai-agency-buying-shift-2026 post documents the buyer-routing shift quantitatively.
The bottom line
The Claude Code SEO stack in 2026 is four layers composed across four operator playbooks. Skills package the recurring SEO workflows so the same prompt is not rewritten every campaign. MCP servers provide live data so the agent reaches outside its runtime. Agents and subagents reason in parallel so a 1-to-2-day backlink gap collapses to 10 to 15 minutes. Hooks ship structural fixes deterministically so the audit-ledger closes without human triage. The 4 PASS keywords in the stack-anchor cluster (claude code skills 9,900, mcp 3,600, agents 2,900, hooks 2,900) carry 19,300 monthly US searches at blended KD 25 on LIVE DataForSEO 2026-05-20.
For SEO and outreach teams deciding between a full SaaS stack and the Claude Code composition: the decision is a 3-axis framework (recurring-motion frequency, data-source reach, automation appetite). High-frequency recurring motions (weekly backlink gap, monthly content brief refresh, daily outreach personalization) collapse into skills first. Wide-reach data needs (Ahrefs + DataForSEO + Firecrawl + GSC + Reddit infrastructure) plug in as MCP servers. Compound reasoning across many sources runs as parallel subagents. Quality gates and ship triggers fire as hooks. The whole stack compounds in CLAUDE.md plus memory.md so the next campaign starts with everything the last campaign learned. The /tools/ai-seo-audit-free tool runs a free audit of how GEO-ready your current site is before committing to the full stack.
For protocol, infrastructure, and consumer-app teams running outcome-priced AI-search optimization, the FORKOFF service surface ships the full Claude Code stack as a single engagement. The two productized lanes are /services/answer-engine-optimization (skills + agents for the search-and-discovery surface) and /services/answer-engine-optimization (hooks + MCP for the AI Overview citation surface). The 4-week sprint installs the skills repo, wires the MCP stack, builds the agent compositions, and lays in the deterministic hook layer. Three sequenced moves to start this week, even before the FORKOFF engagement: run the backlink gap recipe on your top 5 keywords using the exact Alentra prompt above; pick 3 winning angles from your last 10 sales calls plus Reddit search and draft an answer-first piece for each in the 50-words-direct-answer plus 100-to-200-words-why structure; audit your CLAUDE.md and memory.md if you already run Claude Code, since the OS layer is the thing teams skip and it is the layer that compounds across every future campaign.
The next 24 months are the highest-leverage window to lock the Claude Code SEO stack before the broader market closes the gap. AI-chat buyer routing keeps shifting share away from search, which lifts the value of multi-layer agent stacks that produce founder-attributed content compounding across surfaces. The 4-layer stack (skills, MCP, agents, hooks) running across the 4 operator playbooks (backlink gap, GEO 100-day, LinkedIn 4-layer, cold email 6-tool) is the only operating system that captures both the search-and-discovery surface and the multi-month brand-surface compounding. For the deep-dive companion reads: /blog/ecosystem/agentic-seo-forkoff-audit-2026 carries the 14-site agentic-SEO audit and the 10-check scorecard; /blog/founder-growth/agentic-seo-explained-addyosmani-toolkit-2026 walks through the agentic-seo CLI from Addy Osmani; /blog/founder-growth/agent-ready-site-audit-2026 is the per-site agent-ready scorecard. For distribution teams running the full content play in parallel with SEO, /blog/reddit-marketing/reddit-for-ai-startups-2026-stack documents the Reddit intent-to-demand funnel that the Reddit data infrastructure MCP feeds. For founders running /services/answer-engine-optimization as the primary GEO lever, /blog/ecosystem/geo-citation-lab-forkoff-rerun-2026 documents a live GEO citation experiment run by FORKOFF. Pick the skill set, wire the MCP servers, dispatch the agents, fire the hooks, and let the stack run.












