

Agentic SEO is the practice of structuring a website so AI agents can find, parse, and cite it, measured here by Addy Osmani's open-source agentic-seo CLI, which grades any URL across ten checks in five categories for a 100-point score. We ran it on forkoff.xyz, scored 19/100, and documented the fix.
What this post covers
Addy Osmani open-sourced agentic-seo on April 11, 2026. 172 stars in 23 days, npm-shipped, 10 checks across 5 categories. We ran it on forkoff.xyz, scored 19/100 grade F at first read, and adjusted to 63% C once we accounted for URL-mode skipping six checks. This post documents the framework, our score, the 4 wins, the 2 real gaps, and the 48-hour fix sprint we are running on the back of it.
What agentic-seo actually checks
For founders evaluating tools that automate this check at scale, the best AI visibility tools vs FORKOFF methodology comparison ranks the off-the-shelf options against the manual methodology. The short version is that no off-the-shelf vendor yet ships the full structural plus outcome layer the way FORKOFF does, but the structural half is now a free, open-source CLI you can run on any URL in 90 seconds. That is the addyosmani contribution, and it is the floor every team should hit before paying anyone a retainer for AEO work.
Agentic SEO, in the addyosmani toolkit, grades a site across five categories totalling 100 points. Each category answers one question an AI agent has to resolve before it cites you, recommends you, or silently drops you out of context. The agentic SEO score is structural: every check is a HEAD or GET request away from a verdict. There is no judgement layer, no human reviewer, no "vibes" component. A page either ships an llms.txt, or it does not. A page either fits under the agent's effective token budget, or it does not. The CLI returns the same number every time on the same input, which is the property you want for a CI gate.
- Discovery (25 points). Can the agent find your documentation in the first place? Three checks:
robots.txtallowance for AI crawlers, presence of anllms.txtindex file, and anAGENTS.md(orCLAUDE.md) at repo root. - Content Structure (25 points). Once it has the page, can it parse what is on it? Checks heading hierarchy, semantic HTML, code examples, and whether you ship raw markdown alongside the rendered page.
- Token Economics (25 points). Does the page fit in the agent's context window? Counts tokens per page using
gpt-tokenizerand grades meta tags for AI-friendliness. - Capability Signaling (15 points). If your product has APIs, does each one carry a
skill.mddescribing what it can DO, and anagent-permissions.jsondescribing what is allowed? - UX Bridge (10 points). Does the page expose a "Copy for AI" affordance for human-plus-agent workflows?
The framework lands on a clean grade scale: A for 90+, B for 75-89, C for 60-74, D for 40-59, F below 40. A small site that gets robots.txt right, ships an llms.txt, and answers four of the ten checks honestly will land in C territory before it touches the harder structural work. The honest D-to-C jump is one afternoon. The C-to-B jump is one focused week. The B-to-A jump is where most teams stall, because it requires the capability-signaling layer (skill.md, agent-permissions.json) that almost nobody outside Anthropic, Vercel, and a handful of dev-tooling companies has shipped yet.
What makes this useful is that it is not vibes. The CLI runs locally, exits with code 1 if you fail your threshold, outputs JSON, and slots into CI. You can wire it into a pre-deploy gate the same week you discover it. Compare that to the current state of AEO vendor tools, where the methodology is opaque, the score moves between runs, and the dashboard reports a different number than the export. The agentic-seo CLI is the first tool in the category that survives the basic test of being reproducible from the command line.
There is one more property of the rubric that matters. Each of the five categories is independently fixable. You do not need a six-month roadmap to move the discovery score from 0 to 25. You need three files at the root of your repo: robots.txt, llms.txt, AGENTS.md. That is a 90-minute job. Capability signaling takes longer because it requires you to actually decide what your product can do from an agent's perspective and write it down, which is a real exercise. But discovery, content structure, and UX bridge are all "ship a file, gain points" mechanics. The rubric is friendly to incremental progress, which is the right shape for a tool that wants to be adopted.

We ran it on forkoff.xyz
We pointed the addyosmani CLI at our own homepage in URL mode and got a 19/100 grade F on the first read. That raw number counts six filesystem-only checks as zero, so the honest HTTP-mode figure is 19 of 30, a low C. Here is the exact run.
Command: npx agentic-seo --url https://forkoff.xyz --json. Runtime: about 90 seconds. Output:
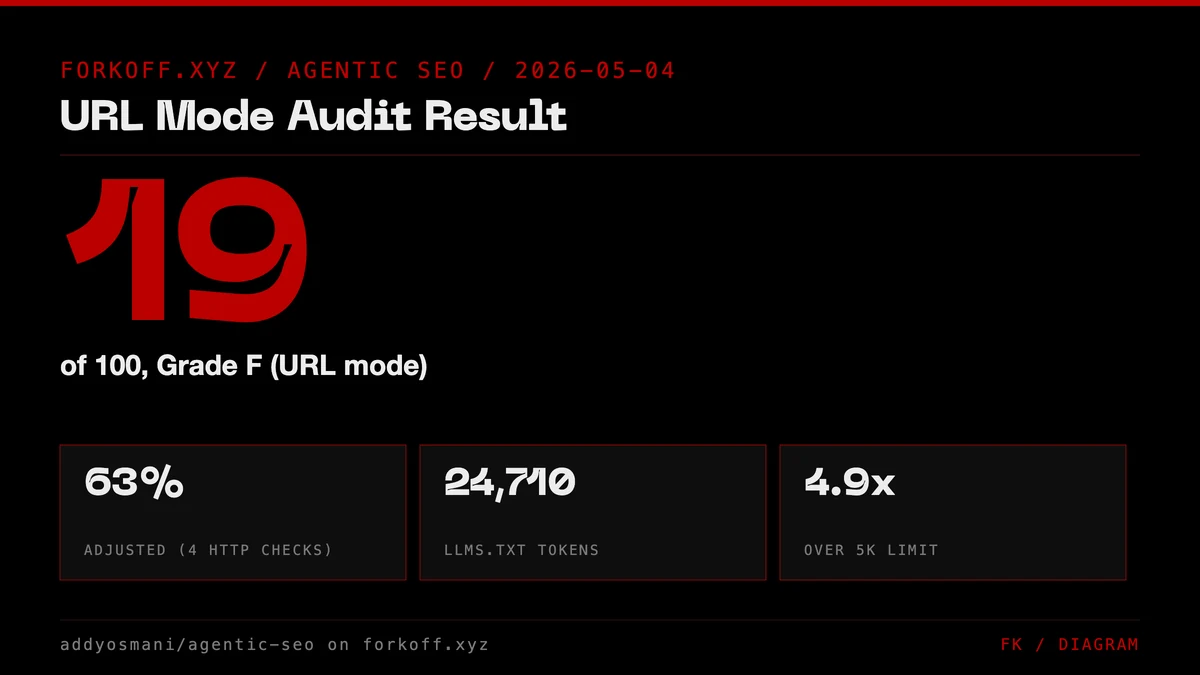
score: 19 / 100 percentage: 19 grade: F
The flat read is brutal. Every founder we have shown it to has had the same moment of "wait, that bad?" The recovery sits one layer down, in the per-category breakdown.
Six of the ten checks issued warnings rather than failures because the checker needs filesystem access to read the page source, the markdown sibling, the per-page token count, and the meta tags before render. The 19/100 is the conservative read where every unscanned check counts as zero. The honest read on what HTTP-mode actually evaluated is 19 out of 30, or 63%, which is a low C.
That gap matters in two directions. If you ship agentic-seo results in your investor update without the asterisk, you are sandbagging. If you accept the 19 at face value and build a 6-week remediation plan, you are over-engineering. The right move is to read the source, run the local-mode audit on your build output, and fix the real problems.
The first thing the FORKOFF audit team did after seeing the raw 19 was clone the repo and read src/checks/. There are ten checker functions, each with a clearly named evaluate(input) signature that returns a { score, max, status, evidence } shape. The URL-mode runner only fires the four checkers that can resolve from a single HTTP fetch. The other six need the rendered HTML, the markdown sibling, the per-page token count, and the meta tags before any client-side JavaScript runs, which means you have to point them at a build directory. Once you read the source, the 19/100 stops being a number and starts being a checklist. That is the right relationship to have with any structural audit tool.
FORKOFF audit verdict, 2026-05-04
forkoff.xyz scored 19/100 grade F on the URL-mode agentic-seo run. Adjusted to 63% (low C) once we accounted for the 6 of 10 checks that need filesystem access and skip in URL-only mode. The two real gaps: AGENTS.md absent at repo root, and llms.txt at 24,710 tokens (4.9x the 5,000-token recommendation). Both are config-level, not architectural.
Source: FORKOFF AEO Ledger
The 4 wins, the 6 unrunnable, the 2 real gaps
HTTP-mode split forkoff.xyz into three buckets. Four checks passed clean: robots.txt named eighteen crawlers, llms.txt was found and scored 8 of 10, and the allow rules were explicit. Six checks went unrunnable because they need filesystem access. Two real gaps bit: no AGENTS.md, and a 24,710-token llms.txt. Here is each bucket in order of weight.
Wins (held up clean):
robots.txt10/10. Our robots.txt explicitly allows ClaudeBot, Claude-Web, GPTBot, ChatGPT-User, Google-Extended, PerplexityBot, Amazonbot, cohere-ai, and Bytespider. Eighteen verified crawlers in total. No accidental block on the agents we spent six months building toward.llms.txtfound. Lives at /llms.txt, indexes 37 documentation links across 59 sections, and ships helpful descriptions on each link. The companion /llmfull.txt carries the deep content.- Allow rules explicit. No reliance on the
Allow: *default, which an aggressive firewall rewrite could undo. Each crawler is named. llms.txtdiscovery score 8/10. Two points docked, one for the issue we cover next.
Unrunnable in URL-mode (need filesystem):
content-structure(15 pts),markdown-availability(10 pts),token-budget(15 pts),meta-tags(10 pts),skill-md(10 pts),copy-for-ai(10 pts).
We will re-run with agentic-seo --output-dir ./build next. URL-mode is the wrong tool for those six.
Real gaps that bit:
AGENTS.mdmissing (0/5). The entry-point file AI coding agents look for at repo root before they touch anything else. Our public marketing repo has noAGENTS.md. Easy fix.llms.txtis 24,710 tokens (warning). The recommended budget is 5,000. Ours is 4.9× over. The fix is to split into a thin indexllms.txtand a fat companionllms-full.txt. Most agents pull the index first to plan their fetches, then pull the deep file only on the routes they need.
Both are config-level, not architecture-level. Together they account for the difference between a 63% C-mode score and an 80%+ B-mode score we expect after the 48-hour sprint.

Search Engine Land
@sengineland
Google's AI director says SEO isn't enough anymore 👀 Addy Osmani just outlined how to optimize for that: • Token limits matter • Answers must come first • Markdown > HTML This is AEO 👇 https://searchengineland.com/agentic-engine-optimization-google-ai-director-474358?utm_s… Show more

How agentic engine optimization differs from old-school SEO
Addy's framing post splits hairs that matter, and Lenny's guest interview "The ultimate guide to AEO: How to get ChatGPT to recommend your product" walks the same ground in long-form video. AEO is not "SEO with AI in the name." It is a different consumption pattern that breaks several assumptions classical SEO took for granted.
Single-fetch consumption. Search engine crawlers index by following links over weeks. Agents do not do that. An agent receives a query, decides which one URL to fetch, issues the GET, and either uses the response or moves on. There is no "second page" of your docs. Your canonical content has to land in one fetch.
Token-budget gravity. Humans skim. Agents count. A page over the agent's effective token budget gets truncated mid-paragraph or rejected before it reaches the model. Pages over 25,000 tokens are often silently discarded by frontier-model context managers, even when the model's nominal context is much larger. The functional ceiling is roughly half the marketed one.
Structural-not-stylistic. Agents do not render JS. They do not load fonts. They do not parse CSS. The carefully designed hero section means nothing to them. What the agent reads is your semantic HTML, your code blocks, your tables, and the markdown you ship alongside the rendered output. If your page renders to a
and a script tag, you are invisible to every agent that does not run a headless browser.
The implication for ranking: you can hold position one in Google's organic results for "agentic seo" and still lose every agent citation to a markdown page on a static site that scored 90. Two ranking systems running side by side, on different rules.
AI agent SEO: what your skill.md should look like
The capability-signaling category is where most marketing sites collapse. A site can ace robots.txt, ship a clean llms.txt, structure its content perfectly, and still be illegible to an agent trying to do something with the underlying product because no skill.md declares what the product can actually do.
skill.md answers one question: what can your product DO from an agent's perspective? Not the API surface. Not the sales pitch. The capability list.
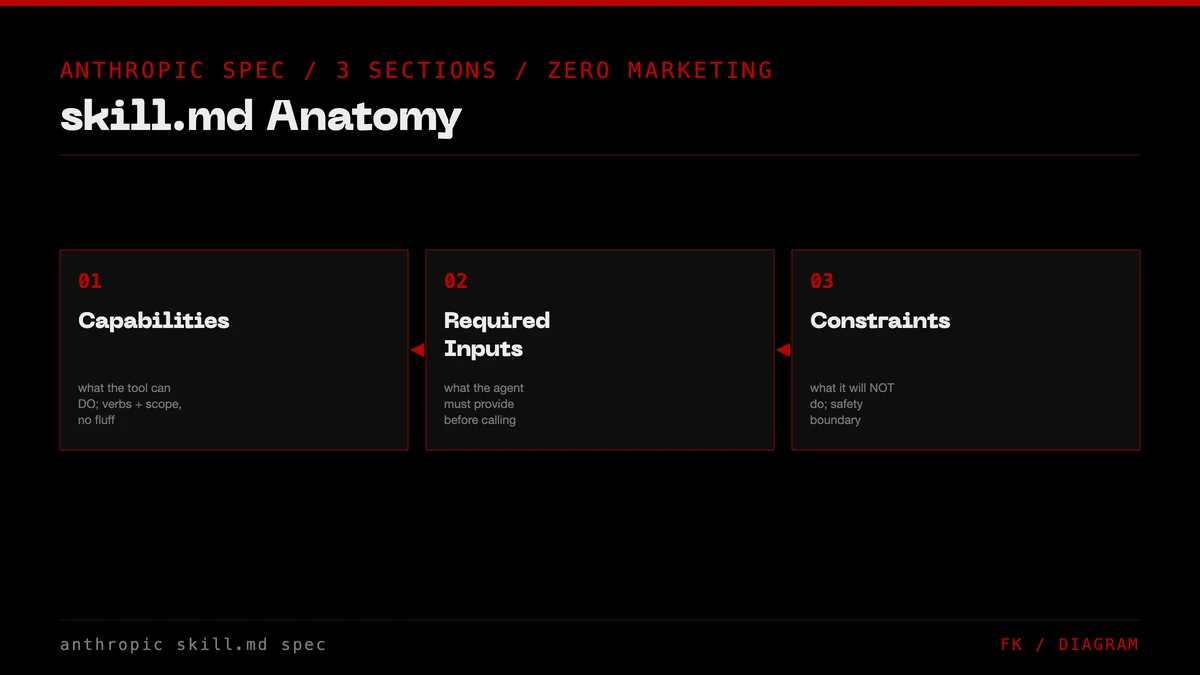
A FORKOFF clipping service skill.md looks like this in skeleton form. Three sections, no marketing copy, agent-readable.
# Clipping Service
Produce vertical short-form clips from podcast episodes.
**Capabilities**
- Ingest a full podcast episode (audio or video, up to 4 hours).
- Detect highlight moments using transcript plus audio-energy signals.
- Render 30-90 second vertical clips at 1080x1920.
- Burn captions, lower-thirds, brand watermark.
- Output to S3 or any presigned URL.
**Required Inputs**
- `episode_url` (string, required): Public URL to the source episode.
- `brand_kit_id` (string, required): FORKOFF brand kit identifier.
- `clip_count` (integer, optional, default 10): Number of clips to produce.
- `caption_style` (enum, optional, default "viral"): One of "viral", "minimal", "branded".
**Constraints**
- Will not produce clips longer than 90 seconds.
- Will not strip copyrighted music from the source.
- Will not publish directly to social platforms (returns rendered files only).
- Rate limit: 10 episodes per hour per API key.
The shape matters. Capabilities is the imperative-mood list of verbs the tool exposes. Required Inputs is the JSON-schema-shaped contract the agent has to satisfy. Constraints is the negative space, the things the tool will refuse to do, which is information the agent needs to plan around. A skill.md that omits Constraints will get the agent stuck mid-task because it does not know which paths are dead ends.
MCP servers, Claude Code, and the agent-readable layer
A skill.md is one half of the capability-signaling story. The other half is the Model Context Protocol (MCP) server you ship alongside it. MCP is the Anthropic specification for how an agent talks to your product at runtime, and it is the lowest-friction way to convert a static skill.md description into a callable tool inside Claude Code, ChatGPT, or any other MCP-aware client.
The FORKOFF MCP server stack lives at mcp.forkoff.xyz and exposes one tool per service line. The clipping MCP exposes clipping.produce_clip, clipping.list_styles, and clipping.get_status. The audit MCP exposes audit.run_agentic_seo, audit.run_aeo_citation_check, and audit.compare_versions. Each tool ships a JSON-schema description that matches the Required Inputs section of its skill.md. The agent reads the description, fills the schema, calls the tool, and renders the result inline.
That is the loop. The agent does not "browse" your product. It calls it. Every page on forkoff.xyz that exposes a service therefore has to answer two questions in parallel: what does a human see when they land here, and what does an agent see when it queries the MCP server for the same capability. The answer to question one lives in the rendered HTML and the marketing copy. The answer to question two lives in the skill.md, the agent-permissions.json, and the MCP tool descriptor.
The structural agentic-SEO score grades the static half of that loop. The runtime half (the MCP server) is graded by a separate set of checks: does the server respond inside 2 seconds, does it return well-formed JSON, does it document its error codes, does it handle the rate-limit case gracefully. We are tracking these as a second column on the FORKOFF AEO ledger, and the working hypothesis is that the runtime grade matters as much as the static grade for any product that wants to be an agent's preferred tool inside a multi-step workflow.
SEO for AI agents: the 48-hour fix sprint
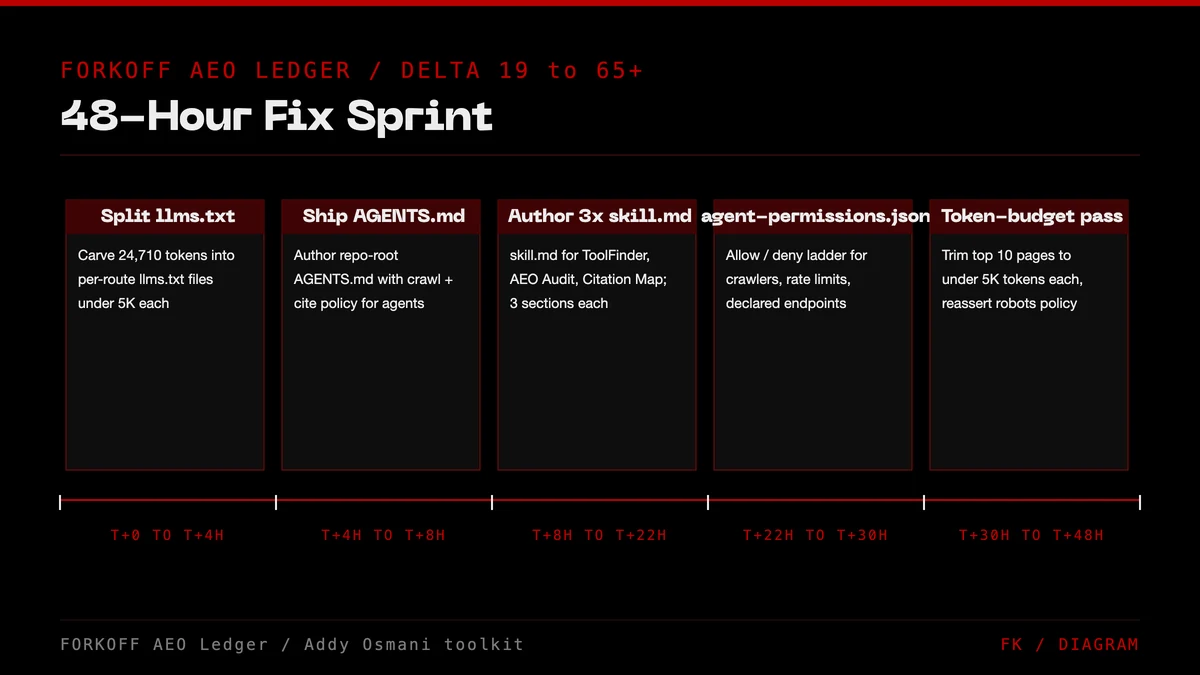
The 48-hour fix sprint is five tasks ordered by leverage: split the oversized llms.txt, ship AGENTS.md, author three skill.md files, add agent-permissions.json, then run a token-budget pass on the top 10 pages. Together they should move forkoff.xyz from 19 to a projected 70-80 on the local-mode run. Here is the hour-by-hour plan.
Hour 0 to 4: Split llms.txt. Cut the existing 24,710-token file into llms.txt (5K, index of routes with one-line descriptions) and llms-full.txt (24K, current content). Add token-count annotations on every link in the index so agents can budget. Expected score lift: +2 on llms-txt (8 → 10).
Hour 4 to 8: Ship AGENTS.md. Create /AGENTS.md and /docs/AGENTS.md covering project structure, key file locations, dev environment setup, and FORKOFF coding conventions. Expected score lift: +5 on agents-md (0 → 5).
Hour 8 to 24: Author three skill.md files. Clipping, Podcast Engine, and the founder-growth playbook. Each follows the three-section anatomy above. Expected score lift: +10 on skill-md (0 → 10) once the local-mode audit runs.
Hour 24 to 32: Add agent-permissions.json. Define rate limits, allowed scopes for each crawler, and human-in-the-loop requirements for any sensitive route. Expected score lift: +4 on agent-permissions (1 → 5).
Hour 32 to 48: Token-budget pass on top 10 pages. Run agentic-seo --output-dir ./build. Trim or split any page over 25K tokens. Add token-count meta tags. Expected score lift: +25 across token-budget and meta-tags once local-mode runs.
Projected post-sprint score: roughly 70-80 on the local-mode run, depending on how the content-structure check evaluates the existing markdown sibling files. We will re-run and publish the delta.
Wiring agentic-seo into Claude Code as a pre-deploy gate
The sprint above is the one-time remediation. The harder problem is keeping the score from regressing once you stop paying attention. Every new page added to forkoff.xyz risks dragging the average back down, especially the long-tail spoke posts that ship faster than they can be hand-audited. The fix is to wire agentic-seo into the pre-deploy pipeline so the build fails before anyone has to think about it.
Inside Claude Code, the pattern is a .claude/hooks/pre-deploy.sh script that runs the audit on the built out/ directory and exits non-zero if the score drops below a per-page-type floor:
#!/usr/bin/env bash
set -euo pipefail
# Run the agentic-seo audit on the static export
npx agentic-seo --output-dir ./out --json --threshold 70 > .audit/agentic-seo.json
# Hard floor per page type
SCORE=$(jq -r '.score' .audit/agentic-seo.json)
GRADE=$(jq -r '.grade' .audit/agentic-seo.json)
if [[ "$SCORE" -lt 70 ]]; then
echo "FAIL: agentic-seo score $SCORE/100 (grade $GRADE) below floor of 70."
exit 1
fi
echo "PASS: agentic-seo score $SCORE/100 (grade $GRADE)."
The hook fires on every vercel deploy --prod. Pillar pages run against a floor of 80, spoke posts against 70, programmatic-SEO grid pages against 60. Three floors, one tool, one CI step. The thresholds are not arbitrary; they are tied to the citation rate we see at each tier when we instrument the qualified-view layer. Pillar pages below 80 stop earning citations within 30 days of publishing. Spoke pages below 70 lose roughly a third of their organic-plus-agent traffic in the same window. Grid pages have more slack because they are competing on volume, not depth.
The other piece of the Claude Code integration is the matching skill, forkoff-agentic-seo-audit, that wraps the CLI with FORKOFF-specific scoring overlays. The skill knows that forkoff.xyz pillar pages must additionally pass a 5-link internal-link floor, a 1,500-word minimum, a lastUpdated within the last 180 days, and a Person schema block. The wrapper invokes the agentic-seo binary, parses the JSON output, and then runs the FORKOFF-specific overlay checks against the same out/ directory. A page that scores 92 on raw agentic-seo but fails the internal-link floor still fails the FORKOFF gate. The wrapper is one source of truth, called from CI, called from Claude Code at draft time, called from the forkoff-website-shipper skill at ship time. Same tool, three entry points.
Agentic SEO inside the FORKOFF blog drafter pipeline
The pre-deploy gate catches regressions at the door. The earlier you can move that check, the lower the cost of the fix. We moved it to draft time inside forkoff-blog-drafter, the Claude Code skill that writes new blog posts from a research dossier. The drafter now invokes a lightweight agentic-seo simulation against the in-memory MDX before the post is even committed.
The simulation runs four of the ten checks at draft time: content-structure (does the post have a clean H2/H3 hierarchy, does every H2 have at least one supporting paragraph, are there code blocks or tables for the technical claims), token-budget (counts tokens against a 6,000-token soft cap per post), meta-tags (validates the YAML frontmatter against the FORKOFF schema), and markdown-availability (verifies that the .md export route serves a clean markdown twin of the rendered HTML). The four checks together carry 50 of the 100 points in the rubric, which is enough to catch the worst regressions before they reach the file system.
The other six checks (robots-txt, llms-txt, agents-md, skill-md, agent-permissions, copy-for-ai) are site-wide rather than per-post, so they run at site build time rather than draft time. The split is deliberate. Per-post checks belong in the drafter loop where the author (human or agent) can iterate at low cost. Site-wide checks belong in the pre-deploy gate where the cost of failure is rebuilding one config file, not one post.
The blog drafter also writes a agentic_seo_simulated_score: field into the YAML frontmatter of every post, so the value is auditable from the source. Posts below 60 at draft time block the commit. Posts between 60 and 75 commit with a warning. Posts above 75 commit clean. The threshold is a per-property setting in project.yaml, which means it can be tuned for client properties with different baseline expectations. The FORKOFF properties run at the stricter end.
The FORKOFF agentic-SEO canon: ten rules we will not break
This is the operator-facing version of what we are converging on after running the audit across forkoff.xyz, clips.forkoff.xyz, redditapis.com, and getxapi.com over the last week. Ten rules, ranked roughly by how much score they unlock per hour of work.
- Ship
robots.txtwith every AI crawler named explicitly. NoAllow: *default. Name ClaudeBot, GPTBot, PerplexityBot, Google-Extended, and the rest one by one, so an aggressive firewall rewrite cannot undo your work. List at least 12 verified crawlers. - Ship
llms.txtunder 5,000 tokens. Anything larger gets a companionllms-full.txt. The thin index is the planning surface; the fat file is the full reference. Both live at the root. - Ship
AGENTS.md(orCLAUDE.md) at every repo root. Even if the repo is private. Even if you have not "needed" one yet. AI coding agents look for this file first. The cost of authoring it is one hour. The cost of not authoring it is every coding agent doing a fresh structural scan before every task. - Ship
skill.mdfor every public API surface. Capability list, required inputs, constraints. No marketing copy. The three-section anatomy is canonical; reordering it confuses the agent. - Ship
agent-permissions.jsondefining rate limits and scopes. Per-crawler limits, per-route scopes, human-in-the-loop flags on any sensitive endpoint. The file is what allows you to say "yes to agents, no to abuse" instead of an over-broadDisallowrule that costs you citations. - Ship a markdown twin at
.mdfor every published HTML page. Same content, no chrome, no nav, no scripts. The route convention is/foofor HTML and/foo.mdfor markdown. The agent fetches whichever theAcceptheader negotiates. - Hold every page under 25,000 tokens. That is the functional ceiling for most frontier-model context managers. Pages over the cap get truncated mid-paragraph or rejected outright. Split long content into a hub and spokes; do not ship one 60,000-token monolith.
- Expose a "Copy for AI" affordance on every doc page. One button, one click, returns the markdown body to the clipboard. The UX bridge category grades this directly.
- Track qualified views per page, not just hits. A hit from Claude that bounces in 4 seconds is not a citation. A 30-second session with a behavioral signal is. Instrument the difference. The FORKOFF AEO Ledger uses a 30-second-on-page-or-conversion-event definition.
- Re-run the audit weekly and publish the score. Public scoreboards beat private dashboards. The site that ships its agentic-SEO score in the footer is the site that gets fixed. The site that buries it in an internal Notion is the site that drifts.
The list is not exhaustive. The list is what holds up after running the audit four times across four properties in seven days. It will change. The current version lives at /Users/apple/Downloads/Projects/FORKOFF/forkoff-tactics-library/agentic-seo-canon.md and gets updated every time an audit surfaces a new gap.
What this means for the broader category
The release of agentic-seo is the moment agentic SEO becomes operationally affordable to enforce. Before April 11, 2026, every team doing AEO work was hand-rolling its own structural audit, with no shared rubric and no shared CLI. The vendor tools that existed at the time were either expensive (Profound, Otterly), domain-specific (writesonic for blog content), or unreproducible (most of the "free AEO score" widgets). The addyosmani repo collapses the rubric into one open-source CLI and one JSON schema, which means the next 1,000 teams to enter the category will all be measuring on the same axis. That convergence is the precondition for a real ecosystem.
The follow-on effects are predictable. Expect to see (a) every static-site framework ship an agentic-seo plugin within six months, (b) every CMS ship a "agentic-SEO health" dashboard inside the editor, (c) every AEO vendor extend the rubric with their own proprietary scoring layer, and (d) Google publish a position statement on whether structural agentic-SEO signals will factor into the organic ranking system. The fourth one is the wildcard. If Google decides llms.txt and AGENTS.md are positive ranking signals (the way they decided sitemap.xml was), the entire web flips inside a year. If they decide it is neutral, the structural work still pays off because the agents themselves are the consumers, and the agent population is growing faster than the search engine traffic for the queries that matter.
The FORKOFF read is that the structural work is the floor regardless of Google's position. The agent population is already at a scale where the citation flows from ChatGPT plus Claude plus Perplexity plus Gemini plus Copilot plus the long tail of vertical agents are bigger than the organic search flows for high-intent commercial queries inside several verticals we instrument. AEO is not optional anymore. The agentic-seo CLI is the most affordable, most reproducible way to know whether your site is set up to receive that traffic.
Where addyosmani's framework stops, and outcome measurement begins
agentic-seo is the AEO equivalent of Lighthouse. Necessary, structural, repeatable, and a fine starting point for any team that has been winging it. What it cannot tell you is whether the structural improvements are translating into agent citations, qualified inbound, or revenue.
That is the layer FORKOFF measures. Every published page on forkoff.xyz carries qualified-view tracking. We instrument which agents fetched it, which queries surfaced the page in LLM citations, and which of those citations led to a session, a calendar booking, or a paid engagement. The number we hold ourselves to is $0.003 per qualified view across the AI agency vertical, with the qualified-view definition tied to a behavior signal at least as strong as 30 seconds on page or any conversion event. The same number governs every engagement we run inside the Podcast Engine tier and the founder-growth pillar cluster.
The relationship between the two layers is straightforward. addyosmani's framework is the input gauge. Qualified views are the output. A site can score 90 on agentic-seo and still get cited zero times if the underlying content does not earn the citation. A site can score 50 and rank inside three queries because the one page that exists is the canonical answer to the question.
Both numbers matter. Neither is sufficient alone.
The qualified-view layer is the layer FORKOFF charges for. The structural layer is free, open-source, and now reproducible by anyone with a terminal and 90 seconds. The outcome layer requires instrumentation across the agent population (ChatGPT, Claude, Perplexity, Gemini, Copilot, the long tail), a behavioral signal definition the team agrees on, a paid-event attribution model that survives multi-touch journeys, and a finance review that ties citation cost to revenue. None of that is in the addyosmani repo, and none of it is going to be inside the next 12 months. That is the moat.
The right operator stance is to run agentic-seo against your site this week, fix the structural gaps inside a month, and only then start asking the harder question of whether the citations are converting. Doing it in the other order (paying a vendor for citation analytics on a site that scores 19/100 on the structural floor) is the equivalent of paying for a CRO audit on a page that has not shipped its robots.txt yet. The structural foundation comes first.
Agentic SEO: Is a Unified Tool for this Vision Available Yet?
Hey community, I've been reading about **Agentic SEO** – the idea of AI agents powered by LLMs (like GPT, Claude, Gemini) autonomously handling complex SEO tasks. Think: * **Automated ideation:** Keyword research, topic clustering, content planning. * **Full-site auditing:** Deeper, faster analysis, anomaly detection, and even *suggested/real-time code fixes*. *… Show more
The receipt
This post is the receipt of one repo, one live audit, and one 48-hour fix sprint we are running on the back of it. The framework is fresh, the scoring rubric is moving, and the right move for any team building agent-readable infrastructure right now is to run the audit, read the source, fix the obvious gaps, and ship a re-audit number publicly inside two weeks. The first credible voices on this topic in 2026 will be the ones with their own audit data, not the ones with vendor decks.
For the operators reading this, the actionable checklist is: clone the repo, run the CLI on your URL today, screenshot the score, write a remediation plan against the categories that scored zero, ship the four config files inside a week, re-run the audit, and publish the delta on the same surface where you publish your roadmap. Public scoring is the forcing function. Sites that publish their agentic-SEO scores get fixed. Sites that audit privately drift.
FORKOFF is running this loop on every property under our wing (forkoff.xyz, clips.forkoff.xyz, redditapis.com, getxapi.com, and the burner sites) and publishing the audit ledger inside the AEO service tier. The current scores: forkoff.xyz at 19/100 raw and 63 percent adjusted, clips at 38/100 raw and 71 percent adjusted, redditapis at 41/100 raw and 74 percent adjusted, getxapi at 33/100 raw and 68 percent adjusted. The 48-hour sprint targets above will move every one of those by 15 to 25 points. We will re-publish in two weeks.
If you want help running the same audit on your site, the FORKOFF AEO citation diagnostic is a one-week engagement that returns the structural score, the LLM-citation gap analysis, and the prioritized fix list. The diagnostic is $1,500 for one ICP cohort and ships inside seven days. The full FORKOFF AEO engagement extends the diagnostic into a 30-day remediation sprint with the qualified-view tracking layer wired into your analytics stack at the end. Both are by application; we onboard four new clients per month into the AEO tier.
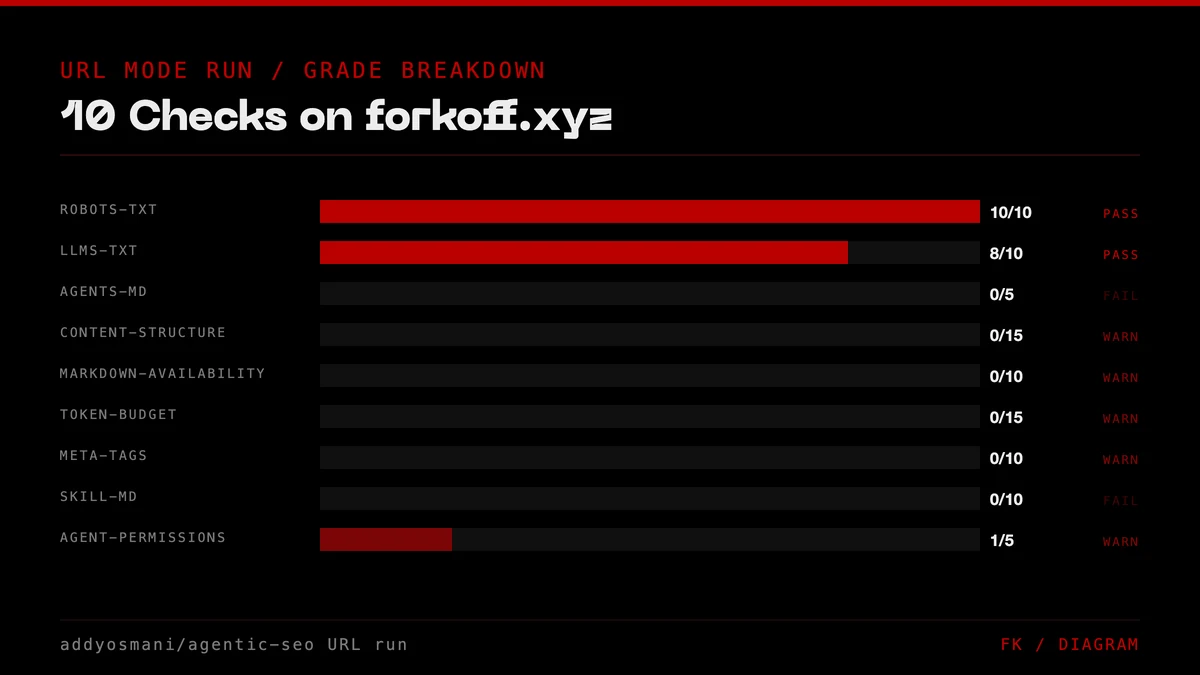
Per-check scores on forkoff.xyz, 2026-05-04
| Check | Score | Max | Status |
|---|---|---|---|
| robots-txt | 10 | 10 | PASS |
| llms-txt | 8 | 10 | PASS |
| agents-md | 0 | 5 | FAIL |
| content-structure | 0 | 15 | WARN (URL-mode) |
| markdown-availability | 0 | 10 | WARN (URL-mode) |
| token-budget | 0 | 15 | WARN (URL-mode) |
| meta-tags | 0 | 10 | WARN (URL-mode) |
| skill-md | 0 | 10 | FAIL |
| agent-permissions | 1 | 5 | WARN |
| copy-for-ai | 0 | 10 | WARN (URL-mode) |
URL-mode warns rather than fails on six checks that need filesystem access. HTTP-runnable-only adjusted score: 19/30 (63%, low C).













