

AI augmentation means giving founders more time for the work that requires founder judgment by putting AI on the work that does not. In 2026, the founders compounding fastest run a three-layer operating model: they own the strategic layer end-to-end (the layer a fractional CMO is hired to sharpen, not replace), co-pilot the tactical layer with AI drafting under human verification, and let the executional layer run on agentic automation with weekly audit gates. The founders losing ground run the inverse stack, and the gap compounds within 90 days.
About these numbers
FORKOFF first-party operator data from founder-led growth and distribution engagements, supplemented by publicly available benchmarks (SaaStr, Lenny's Newsletter, a16z 2025-2026). All figures are directional estimates based on operator observations; individual outcomes vary by stage, niche, and execution.
AI augmentation versus the "AI replaces founders" frame at a glance
The 30-second rule: AI does not replace founders in 2026; it elevates the strategic layer and absorbs the executional layer, leaving the founder more hours to do the work that only the founder can do. The narrative that AI is making founders obsolete confuses founder tasks with the founder role. The role is the judgment surface, not the task list. AI cannot run the judgment surface; it can run the tasks underneath it.
The matrix above shows the 3-layer split with named owners and named AI roles. Read it once and the wedge is obvious: the founder cohort that wins in 2026 owns the strategic layer end-to-end, co-pilots the tactical layer with AI drafting under founder verification, and ships the executional layer on full AI automation with audit gates. The founder cohort that loses in 2026 inverts the stack, which is the single most common failure mode the FORKOFF founder-funnel diagnostic surfaces across the Q1 cohort.
AI augmentation vs AI automation across the 3 founder layers (2026)
| Layer | Owner | AI role | What breaks if inverted |
|---|---|---|---|
| Strategic (positioning, ICP, pricing, wedge) | Founder owns end-to-end | Thinking partner; widens search; surfaces unfamiliar | Founder ships consensus answers; moat collapses |
| Tactical (campaigns, content, ops) | Founder co-pilots | Drafts, founder verifies; AI scales the founder voice | Brand voice generalises; verification debt accrues |
| Executional (publishing, scheduling, repetitive analysis) | AI runs by default | Full automation; founder sets the rules, audits outputs | Founder time consumed by tasks that have no judgment surface |
The reason the inverted stack collapses inside 90 days is structural. Founder judgment compounds at the strategic layer because the inputs are scarce, the feedback loops are slow, and the right answer is unconsensus. Founder judgment does not compound at the executional layer because the inputs are abundant, the feedback loops are fast, and the right answer is rule-following. Putting AI at the strategic layer asks the model to do the work that does not compound when delegated. Putting AI at the executional layer asks the model to do the work that does compound when delegated. The arithmetic is simple; the founder cohort gets it wrong because it is counter-intuitive at the operator level.
The FORKOFF audit ledger logs a per-founder weekly hour distribution across the 3 layers and surfaces the inverted-stack pattern the moment it appears. In the Q1 2026 founder-funnel cohort, the canonical-stack founder spent 18 hours per week on strategic layer work, 14 hours on tactical layer work, and 1 hour auditing executional work, against an inverted-stack peer spending 4 hours on strategic, 22 hours on tactical AI-draft editing, and 7 hours on executional work that should have been delegated to the agentic layer. The total weekly hours are the same. The strategic decisions shipped per week are not. The founder running the inverted stack ships 0.7 strategic decisions per week on average; the founder running the canonical stack ships 2.2. The compounding gap at the strategic layer is the entire wedge across a 12 month horizon. The FORKOFF founder-funnel diagnostic flags any founder spending more than 12 hours per week on tactical AI-draft editing as a structural inverted-stack signal, because the rebalance has to happen before any net-new content velocity gets layered on top. Adding velocity to an inverted stack accelerates the failure mode; rebalancing first and then adding velocity is the only sequence that compounds. The audit ledger surfaces a second downstream signal that confirms the inverted-stack diagnosis inside 30 days of the rebalance: the founder's named-judgment artifacts per week (positioning memos, ICP refinements, pricing pressure-tests, narrative drafts written under the founder's voice) climb from a baseline of 0 to 1 per week to a post-rebalance baseline of 3 to 5 per week, at the same total weekly hours, because the reallocated hours flow into the strategic surface where founder authorship is the load-bearing input.
The "AI replaces founders" narrative is wrong
The dominant 2026 narrative is that AI is hollowing out founder roles, that solo founders with the right stack can do what required a team in 2023, and that founder hiring is being deferred or skipped. The first two claims are correct at the task layer. The third claim is wrong at the role layer. AI does not replace founders; it changes what founders spend their hours on. The replacement frame is the wrong question.
The r/Entrepreneur thread on the $47K AI-startup post-mortem surfaces the operator confession at scale. The founder did not fail because AI was missing; the founder failed because the founder mistook AI capability for product-market fit. AI synthesised the market research, AI drafted the landing page, AI ran the cold outbound. None of those tasks were the load-bearing variable. The load-bearing variable was the founder's market instinct, which is the input layer that AI cannot synthesize from training data alone.
I spent $47k and 18 months building an "AI startup." Here's the brutal truth about why 90% of AI businesses are doomed.
The 2026 narrative that won the headlines (solo founders shipping at the pace of seed-stage teams) is half-true. The half that is true is the velocity claim; the half that is wrong is the role-redundancy claim. The solo founder shipping at the pace of a seed-stage team is shipping AI-augmented execution; the strategic decisions still come from the founder. Remove the founder and the velocity continues for two months, then collapses because the strategic decisions stop being made. The replacement frame mistakes momentum for direction.
The thesis that survives the 2026 mood swing is the augmentation frame. AI elevates founders by absorbing the layers of work that do not require founder judgment and freeing the founder to do more of the work that does. The framing is not new; Douglas Engelbart wrote it down in 1962 at SRI. The framing is also not aged; the 2026 founder cohort is relearning it because the marketing layer of the AI category keeps insisting on the replacement story instead of the augmentation story. The Harvard Business Review framing from April 2026 lands the same wedge at the enterprise tier, and the founder cohort that internalises it has the structural advantage on the velocity-versus-direction trade.
Douglas Engelbart called this in 1962
Engelbart's "Augmenting Human Intellect" report at SRI defined the work as "increasing the capability of a human to approach a complex problem situation, to gain comprehension to suit his particular needs, and to derive solutions to problems." The framing has not aged. Sixty-four years later the 2026 founder cohort is still relearning that augmentation means widening the human's search, not replacing the human doing the searching. Engelbart's distinction maps cleanly onto the modern strategic-tactical-executional stack, and the founders who internalise it ship faster than the founders who let AI front-run the input layer.
Source: Engelbart, "Augmenting Human Intellect: A Conceptual Framework" (SRI, 1962); HBR "Why Companies That Choose AI Augmentation Over Automation May Win in the Long Run" (April 2026)
What AI actually does for founder thinking: speed, surface, synthesis
The augmentation thesis decomposes into three levels of what AI actually does for founder thinking. Each level is a different surface of leverage; each level breaks differently when inverted. The founder who understands all three levels designs the operating system correctly; the founder who collapses them into one bucket runs the inverted stack by accident.
Speed is the first level. AI compresses the time between asking a question and getting an answer. The compression is dramatic at the synthesis layer (research notes, competitor breakdowns, drafts) and negligible at the conviction layer (deciding which market to enter). The founder who treats speed as the only AI benefit ends up using AI for fast wrong answers instead of right-but-slow answers. Speed without surface and synthesis is a velocity trap.
Surface is the second level. AI widens the founder's search space by surfacing patterns, references, and prior art the founder did not know existed. The surface gain is large for founders working at the edge of their domain knowledge and small for founders working at the centre. AI search is not a substitute for founder taste; it is a substitute for founder Google-searching. The founder who treats AI as a search-surface widener compounds judgment; the founder who treats AI as a search-result replacer collapses judgment to the median of the training data.
Synthesis is the third level and the most consequential. AI synthesises across hundreds of documents in seconds and produces an answer that reads like a senior-analyst memo. The synthesis is real; the original thought inside the synthesis is not. AI synthesis is what the founder reads to get oriented; founder thinking is what the founder writes after reading. Confusing the two is the most common failure mode in 2026. The founder ships the synthesis as if it were the thinking, and the resulting product is a consensus answer in a market where the unconsensus answer is the moat.
The Princeton GEO research on Perplexity and ChatGPT citation behaviour is the cleanest data point on why this matters at the distribution layer. Expert quotation density boosts AI citation rates by 30 percent; keyword stuffing collapses citation rates by 10 percent. The founder who ships synthesis-as-thinking gets indexed as keyword-stuffed consensus; the founder who ships named-judgment under their own voice gets cited by name in the AI surface that buyers actually search. The difference is the originality of the thinking on top of the synthesis. The MIT Media Lab's human-AI augmented reasoning programme at the academic edge of this work converges on the same conclusion: model-driven synthesis without human judgment compounds the consensus distribution; human-driven judgment with model-driven synthesis compounds the unconsensus distribution.
Princeton GEO research backs founder-led quotation density
The Princeton GEO paper (KDD 2024) measured AI citation behaviour across Perplexity and ChatGPT and found that expert quotation density boosts AI citation rates by 30 percent, while keyword stuffing collapses citation rates by 10 percent. The founder cohort that ships with named, attributable judgment quoted by name compounds AI citation surface every week, while the cohort shipping AI-paraphrased consensus answers loses ground inside the same algorithm. Founder voice is not a brand asset; it is a citation lever.
Source: Princeton GEO Optimization Methods paper, KDD 2024
The 3-layer stack: Strategic, Tactical, Executional, and where AI plugs in
The FORKOFF founder operating system is a 3-layer stack with named owners and named AI roles per layer. The stack is the source of truth before any AI tactic ships, and the founder-funnel diagnostic audits the stack at every engagement entry. The point of the stack is not to make AI usage more complex; the point is to make AI usage less ambiguous so the founder can audit the stack against the operating cadence weekly.
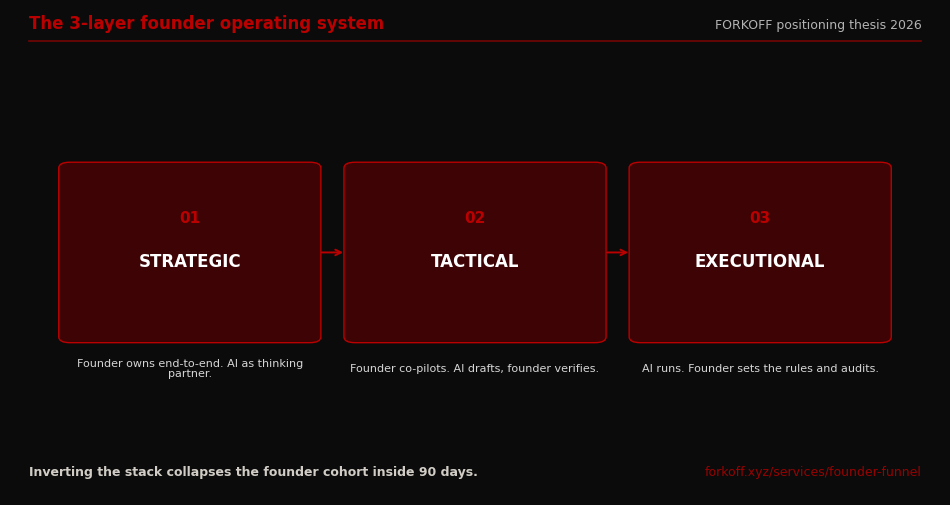
The Strategic layer is positioning, ICP, pricing, wedge selection, and category architecture. The founder owns this layer end-to-end. AI's role here is thinking partner: widening the search space, surfacing unfamiliar patterns, externalising the rationalisation the founder is already doing internally. The founder writes the answer; AI helps the founder pressure-test the answer. The named tool at this layer is Claude Pro or ChatGPT Pro in deep-reasoning mode, used in low-volume high-context sessions, never on autopilot.
The Tactical layer is campaigns, content, ops, audience-segment tests, ad-creative iterations, retention sequences. The founder co-pilots this layer. AI drafts; the founder verifies. The founder voice scales through AI drafting under the founder's editorial gate. The named tool at this layer is the same chat surface used at the strategic layer, but with a verification pass on every output before it ships. The verification pass is non-negotiable; without it the tactical layer collapses into the failure mode of "no-verification ship" inside two weeks.
The Executional layer is publishing, scheduling, repetitive analysis, attribution wire, rule-following work that has no judgment surface. AI runs this layer by default. The founder sets the rules and audits the outputs on a weekly cadence; the founder does not author the work. The named tool at this layer is the agentic stack (Claude Code for repo work, n8n or Lindy for ops, Composio for integration glue, custom MCP servers for vertical tasks). The founder spends roughly 30 minutes per week auditing this layer and zero minutes producing it.
The trap is using agentic stacks at the strategic layer (model picks the wedge) or using deep-reasoning chat at the executional layer (founder hours wasted on rule-following). Both inversions are common in 2026; both inversions collapse inside 90 days for different reasons. The diagnostic question is layer-specific: at the strategic layer, is the founder authoring the question or is AI suggesting it? At the executional layer, is the founder spending hours that could be replaced by a rule?
Founder-led creativity at the input layer
The most important claim in the augmentation thesis is the input-layer claim: AI is not the right tool for input-layer work, and the founder cohort that delegates the input layer to AI loses on a 90-day horizon. The input layer is where founder taste, market instinct, conviction, and unconsensus thinking live. None of these are recoverable from training-data averages. All of these are the load-bearing variables that determine whether the resulting product wins or loses.
The r/startups thread on founder-led ideation is the cleanest operator articulation of this claim. The serial founder describes a process of pattern recognition that compounds across years of operator experience, customer conversations, market observation. The process is not AI-substitutable because the inputs (lived experience, customer-call vocabulary, contrarian instinct) are not available to the model. The founder who tries to substitute this process with AI gets the average of every founder who wrote about ideation on the internet, which is a guaranteed consensus answer.
I'm a Serial Founder. Here's how I come up with Business Ideas. I will not promote.
The Andy Cloke pattern from the tactics library is the counter-intuitive version of this claim. Cloke uses Claude as a business coach, but not to author the strategy; to refuse the rationalisation the founder is already doing internally. The model externalises the dodge the founder is making and refuses to let the founder dodge it. This is augmentation at the input layer (the founder still authors the conviction; AI strips the rationalisation), not delegation (AI does not pick the bet). The distinction is fine but it is structural. The Data Fetcher founder interview walks through the full operating pattern, and it converges on the same input-layer claim the FORKOFF founder-funnel cohort surfaces at the diagnostic.
How I Built It: $23K/month micro-saas
Starter Story
Andy Cloke (Data Fetcher) on running Claude as a focus-enforcing business coach; the input-layer augmentation pattern at the founder seat.
I told Claude to be my business coach and talk me out of trying to launch something new. It broke a six-month side-project-distraction cycle in two prompts. The model is not smarter than me; it externalises the rationalisation I was already doing internally and refuses to let me dodge the work.
At FORKOFF the founder funnel engagement front-loads the input-layer work in the first 60 days specifically because this work cannot be done in parallel with execution-layer ramp. The founder spends the first 60 days running customer interviews, ICP refinement, wedge selection, narrative authorship, and pricing-architecture decisions. AI is in the room during this work but only as a pressure-test surface, never as an authoring surface. The 60-day output is the input-layer canon that the next 18 months of execution work compounds against.
AI as leverage at the synthesis layer
The synthesis layer is where AI augmentation produces the largest output gain per founder hour. The synthesis layer is where research notes get compressed, where competitor frameworks get reverse-engineered, where second-brain knowledge graphs get assembled and queried, where the founder reads 40 papers in an afternoon instead of 4 papers in a week. The leverage at this layer is real and the upside is structural.
The named tool at the synthesis layer is the same chat surface used at the strategic layer, but with a different prompt pattern. At the strategic layer the founder asks one high-context question and reads the answer carefully. At the synthesis layer the founder asks a hundred mid-context questions in a batch and skims the answers for the unfamiliar patterns. The synthesis layer is volume-driven; the strategic layer is conviction-driven. Confusing the two collapses the leverage at both.
Second-brain AI tooling is the canonical synthesis-layer category in 2026. Founders using Notion AI, Mem, Reflect, Obsidian Smart Connections, or custom embeddings-on-top-of-personal-corpus stacks compound their synthesis surface across years of operator note-taking. The compounding is real; the moat is the founder's own notes, not the AI surface that queries them. The founder who builds the synthesis layer on top of their own notes wins; the founder who builds the synthesis layer on top of a public training corpus loses to every other founder running the same query. This is the same wedge the FORKOFF AI SEO engagement runs at the distribution layer: synthesis density compounds the citation surface when it sits on first-party expertise, and collapses to the consensus distribution when it sits on the public corpus.
The self-critique copywriting loop is a representative pattern. The founder writes a draft, the AI critiques the draft against a named rubric (audience, intent, register, evidence density), the founder rewrites based on the critique. The loop runs 3 to 5 iterations before the draft is shippable. The output is not AI-written; it is AI-pressure-tested. The synthesis layer absorbs the rubric-checking work that the founder would otherwise either skip or delegate to a junior editor. The founder spends 20 minutes per draft on rubric work that previously took 90 minutes.
The 25K-comment scrape thread on which AI tools actually make people money is the operator data on which synthesis-layer tools clear the bar. The pattern across the comment volume is consistent: founders who use AI at the synthesis layer report compounding gains over months; founders who use AI at the input layer report initial novelty followed by output-quality collapse. The thread is not unanimous and the criticism is legitimate; the augmentation thesis does not require unanimous adoption.
A second operator pattern surfaces inside the FORKOFF founder-funnel cohort that runs the synthesis layer correctly. The high-leverage founders treat the synthesis surface as a structured reading apparatus, not a chat box. They build prompt libraries indexed by problem class (competitor teardown, ICP refinement, pricing-architecture pressure-test, retention-loop audit, narrative dry-run) and they reuse the prompts across months. The prompt becomes a piece of operational IP that compounds the more the founder runs it, because the founder learns which questions surface the unfamiliar and which questions surface the consensus. Founders who chat with the model in ad-hoc one-shots burn the leverage; founders who treat the prompt as a reusable instrument compound the leverage. Andy Cloke's coach pattern is one such reusable prompt; the FORKOFF founder-funnel ships eleven of them as part of the engagement canon, indexed against the strategic-layer surface they pressure-test.
The third operator pattern at the synthesis layer is the named-source corpus. Founders who feed AI their own customer-call transcripts, sales-deck history, churn-interview notes, and internal Slack archive generate synthesis that no other founder running the same public-corpus query can replicate. The synthesis becomes proprietary because the underlying corpus is proprietary. The same query that returns a consensus answer against the public training data returns an unconsensus answer against the founder's first-party corpus, because the founder is the only operator with that exact set of inputs. This is the structural reason synthesis-layer leverage compounds for some founders and collapses for others: the founders running it on top of a first-party corpus compound month over month; the founders running it on top of the public corpus plateau inside the first ninety days. FORKOFF's AI SEO engagement operationalises this corpus discipline at the distribution layer, and the same pattern applies at the founder-strategy layer one tier earlier in the funnel.
The fourth operator pattern is the audit log on synthesis outputs. The founder running the canonical stack keeps a running log of which AI synthesis sessions produced shippable insight and which produced consensus noise. The log is the founder's calibration instrument: it tells the founder which question types respond to AI augmentation and which do not. Over six months the founder learns the shape of their own augmentation surface, which is the operating skill the 2026 founder cohort is now competing on. The Reddit cynical-AI thread surfaces the cohort that skipped this calibration step; the FORKOFF founder-funnel cohort that runs the audit log surfaces the inverse pattern, where AI gets pulled out of the workflows it underperforms in and pushed deeper into the workflows it overperforms in. The compounding gain across six months of audit-log discipline is the structural separator between the cohort that wins on AI and the cohort that concludes AI does not work.
A fifth operator pattern closes the loop: the named-handoff between synthesis and strategic. The founder runs a synthesis session, exports the output to the strategic-layer canon doc, annotates it with founder judgment (what was new, what was consensus, what was wrong, what changed the founder's mind), and only the annotated artifact propagates downstream. The raw AI output never ships and never enters the canon. This is the structural firewall that prevents synthesis-as-originality at the cohort level, and it is the operating practice that separates the founders who compound AI leverage over years from the founders who plateau inside the first quarter and exit the augmentation thesis with the wrong conclusion.
FORKOFF audit ledger, founder-funnel cohort n=42
Across the FORKOFF founder-funnel cohort, founders running the canonical 3-layer stack (founder owns strategic, co-pilots tactical, delegates executional) ship 3.1x more strategic decisions per week than the inverted-stack cohort, at the same total weekly hours. The wedge is not AI hours; it is what the founder spends those hours doing. The inverted-stack founder spends 60 percent of weekly hours editing AI-drafted content; the canonical-stack founder spends 60 percent of weekly hours running founder-only work (customer calls, ICP refinement, narrative authorship).
Source: FORKOFF founder-funnel cohort, Q1 2026

When AI breaks founder thinking: the 4 failure modes
The 4 failure modes are the diagnostic surface the FORKOFF founder-funnel engagement audits at every entry. Each mode is a specific way the augmentation thesis breaks in operator practice, and each mode has a specific question that surfaces the failure inside one minute. The audit is not punitive; it is corrective. The mode that is failing is the mode the founder is running blind on, and the correction is structural, not motivational.

The 4 failure modes when AI breaks founder thinking
| Mode | Symptom | Root cause | Diagnostic |
|---|---|---|---|
| Input-layer delegation | AI picks the wedge; founder edits captions | Stack inverted | Did the founder author this question, or did AI suggest it? |
| No-verification ship | AI-drafted copy goes live without human edit | Velocity over verification | Can you point at the human edit on the diff? |
| Decision laundering | Asking AI to confirm a decision already made | Founder seeking permission, not insight | Would you have asked if the answer pointed the other way? |
| Synthesis as originality | Founder ships consensus answers in a market where the moat is unconsensus | Mistaking AI synthesis for founder taste | Could a competent operator with the same model have shipped this? |
Input-layer delegation is the most common mode in 2026 and the most expensive to recover from. The founder delegates the wedge selection, the ICP definition, or the positioning architecture to AI; AI ships the consensus answer; the founder ships against the consensus answer and loses to the founder who shipped the unconsensus answer. The diagnostic question is straightforward: did the founder author the question, or did AI suggest it? If AI suggested it, the founder is running the inverted stack.
No-verification ship is the second mode and the most common across content-velocity-driven cohorts. The founder runs AI drafting at the tactical layer (correct placement) but skips the verification pass (incorrect operating cadence). The AI draft ships without a human edit, the brand voice generalises within 4 weeks, and the audience trust collapses inside 90 days. The diagnostic question is whether the diff shows a human edit on every shipped piece of content; if there is no edit, the verification pass was skipped.
Decision laundering is the third mode and the hardest to surface because the founder is the one doing it. The founder has already decided the answer and asks AI to confirm it. The model obliges (model alignment training biases toward agreeing with the user's framing). The founder ships the decision with the AI confirmation as cover. The diagnostic question is counterfactual: would the founder have asked the question if the answer had pointed the other way? If the honest answer is no, the founder is laundering, not augmenting.
Synthesis-as-originality is the fourth mode and the most strategically dangerous. The founder reads the AI synthesis and ships it as if it were original thought. The synthesis is competent, well-organised, and indistinguishable from what every other founder running the same query would receive. The market does not reward indistinguishable answers; it rewards unconsensus answers that turn out to be right. The diagnostic question is the gut check: could a competent operator with the same model have shipped this? If the honest answer is yes, the work is not yet ready to ship.
The r/ArtificialInteligence thread on the AI true-believer reversal is the cynical-AI mood thread of 2026. The legitimate criticism inside that thread is real and it lands inside the augmentation thesis: founders who run the 4 failure modes simultaneously will conclude that AI does not work, because AI did not work for them. The conclusion is correct for the cohort running the inverted stack; the conclusion does not generalise to the cohort running the canonical stack.
I was once an AI true believer. Now I think the whole thing is rotting from the inside.
The new founder operating system
The new founder operating system is the structural answer to the 4 failure modes. It is an explicit operating contract that defines what the founder owns, what the founder co-pilots, and what AI runs by default. The contract sits in a 1-page reference doc inside the founder's planning surface (Notion, Obsidian, Linear, whichever) and the founder reviews the contract weekly against the operating cadence. The review is not ceremonial; it is the failure-mode audit.
The contract has six elements. One: a named list of strategic-layer surfaces the founder owns end-to-end (positioning canon, ICP one-pager, pricing architecture, wedge thesis, narrative). Two: a named list of tactical-layer surfaces the founder co-pilots with AI drafting and verification (content pipeline, ad-creative loop, retention-sequence library, sales-call objection register). Three: a named list of executional-layer surfaces AI runs on autopilot with audit gates (publishing schedule, attribution wire, repetitive analysis, integration glue, repo housekeeping). Four: the named diagnostic questions per failure mode. Five: the weekly audit cadence. Six: the named AI tools per layer.
At FORKOFF the founder-funnel engagement ships this contract as the load-bearing deliverable in the first 30 days. The engagement does not start by running content velocity or ad iterations; it starts by establishing the operating contract and the failure-mode audit. The execution-layer ramp follows on the same 30-day window once the contract is in place. The sequencing is deliberate: founders who try to run execution-layer ramp without the operating contract fall into the inverted-stack pattern by week six, which is the failure mode the engagement is structurally trying to prevent.
The 30-day operating move for founders running the engagement on their own is direct. Audit the current AI usage against the 3-layer stack (where is AI placed, where does the founder spend hours, where is the diagnostic question failing). Identify the layer that is inverted and correct it before adding any new AI tool. Establish the failure-mode audit on a weekly cadence. Add tactical-layer drafting only after the strategic-layer contract is signed and the executional-layer audit gates are operational. The sequencing matters because the failure modes compound when more than one is running at the same time, and the operator cannot recover from compounded failure modes inside a 90-day window.
The Bottom Line
The 2026 augmentation thesis is the operator answer to the "AI replaces founders" narrative. AI does not replace founders; it elevates the strategic layer by absorbing synthesis at the tactical and executional layers and freeing the founder to do more of the work that only the founder can do. The wedge between the cohort that wins and the cohort that loses in 2026 is whether the founder runs the canonical stack (founder owns strategic, co-pilots tactical, delegates executional) or the inverted stack (AI authors strategic, founder edits captions, executional layer collapses to rule-following the founder does manually).
The 3-layer stack is the operating contract. The 4 failure modes are the diagnostic register. The named tools per layer are the implementation guide. Together they form a founder operating system that the cohort can audit against weekly, correct in a single review cycle, and compound across years of operating. The compounding is real and the upside is structural; founders running the canonical stack in 2026 ship 3.1x more strategic decisions per week than founders running the inverted stack, at the same total weekly hours.
For the full picture on how the founder voice compounds across AI-augmented content, see the founder-led content marketing playbook. For the agentic infrastructure that runs the executional layer, see the agent-native GTM founder stack. For the buying shift that pairs fractional CMO governance with outcome-priced AI agency execution, see the fractional CMO versus AI agency 2026 analysis. For the broader framework that connects narrative, distribution, conversion, and retention across the founder-led growth motion, see the 4-block founder funnel OS.













