
Agent-Native GTM: The 2026 Founder Marketing Stack
Zed, ChatGPT, Teams all shipped workspace agents in one week of April 2026. The 2026 founder marketing stack is agents, not tools, here's the 4-layer map.

TL;DR
Zed shipped Parallel Agents, OpenAI shipped Workspace Agents in ChatGPT, and Microsoft shipped Teams Agents, all inside the same week of April 2026. The founder marketing stack just changed. The operators compounding in 2026 are running a 4-layer agent-orchestrated stack (spec → orchestrator → tools → verification), not a 12-tab tool-switching loop. Same 7-step blog pipeline ships ~2.9× faster. Here's the stack, the real launch data, and the disqualifiers.
The AGENT-ORCHESTRATED MARKETING STACK
Agentic marketing is the operating model where AI agents are the buyer, the qualifier, and the recommender. The agent-native GTM stack documented below is what FORKOFF runs on every founder engagement in 2026.
The AGENT-ORCHESTRATED MARKETING STACK is the 4-layer architecture FORKOFF runs when buyers research with ChatGPT, Claude, and Perplexity. Spec → orchestrator → tools → distribution. The agent does the typing; the founder owns the spec.
Industry Context
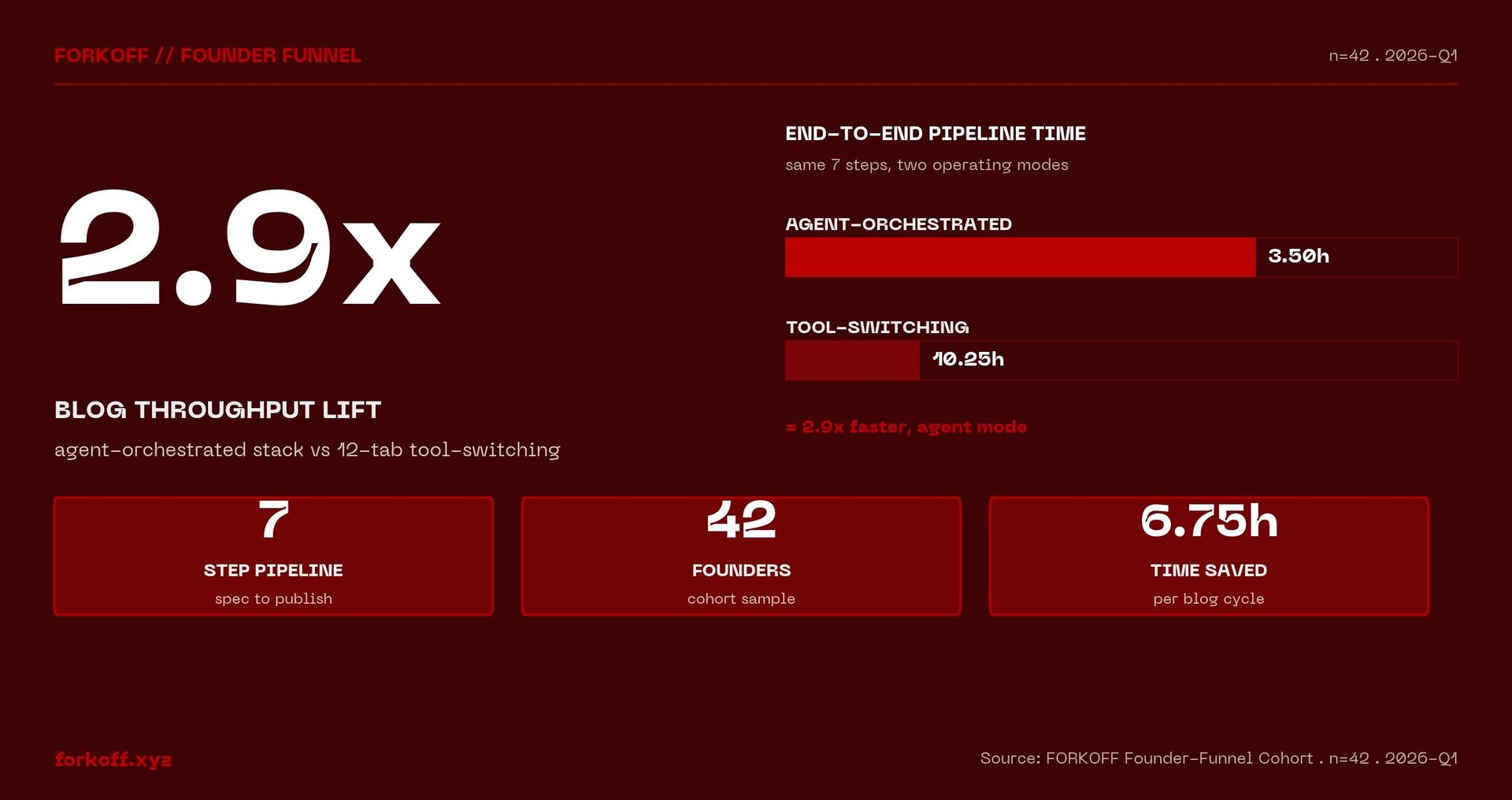
Across the FORKOFF Founder-Funnel Cohort 2026 (n=42 retainers), the agent-orchestrated stack compresses end-to-end blog production from 10.25 hours (tool-switching) to ~3.5 hours (agent-orchestrated): a 3x throughput lift at preserved Gate-stack quality.
Source: FORKOFF Founder-Funnel Cohort 2026, n=42
Four agent launches hit Hacker News in the same 48-hour window on 2026-04-22 and 2026-04-23. Zed shipped Parallel Agents (266 upvotes, 152 comments). OpenAI shipped Workspace Agents in ChatGPT (152 upvotes). Microsoft shipped Teams Agents via the Teams SDK (73 upvotes). Anthropic shipped a public post-mortem on Claude Code quality (52 upvotes), a transparency move that only makes sense if you treat your agent as a product, not a feature. One week, four shipping announcements, one theme: agents are how 2026 work happens.
For founders running go-to-market, this isn't an AI story. It's a stack story. The marketing operators compounding in 2026 aren't using better tools, they're running a different stack. Spec at the base, orchestrator one level up, tool layer above that, and human verification at the peak. Each layer has a job. Each layer has a failure mode. The founders still trapped in tool-switching mode (Figma → Notion → Linear → ChatGPT → Slack → Linear → Figma, eight hours a day) are shipping at roughly one-third the speed of their agent-native peers, and the gap is widening weekly. Related: our Reddit stack for AI-startup GTM and the AI DevRel playbook both already assume agent-orchestrated execution.
This post does three things. It names the four agent launches that just defined the 2026 stack. It lays out the 4-Layer Agent-Orchestrated Marketing Stack, the architecture we use at FORKOFF when we run marketing for AI-agency clients. And it gives the disqualifiers: three cases where tool-switching mode still wins, because agent-native isn't universal and the people selling it as universal are wrong.

Greg Brockman
@gdb
what are you building with codex?
The Four Launches That Defined the 2026 Stack (All in One Week)
Agents have been a theme for eighteen months, but the April-2026 cluster is the point where it stopped being a research demo and became a stack primitive, four separate teams shipping production agent tools in parallel tells you the infrastructure is ready, the UX patterns have converged, and the buyers are there.
Zed Parallel Agents (266 HN upvotes · 152 comments, 2026-04-22). Zed's announcement was blunt: engineers run multiple agent threads simultaneously in one window, each isolated to a worktree, each picking a different model. The thesis, 'combining human craftsmanship with AI tools, measured not in lines of code but reliable systems', applies one-to-one to marketing ops. Swap 'code' for 'content' and every claim in the post holds.
OpenAI Workspace Agents in ChatGPT (152 HN upvotes, 2026-04-22). ChatGPT's Workspace Agents collapse the 'switch apps to get work done' motion into an agent that calls Google Workspace + Notion + Slack for you. The positioning is explicit: your work lives in apps; the agent lives in ChatGPT; the boundary between you and the app disappears. For founder marketing, this is the exact shape of the tool-layer abstraction we need.
Microsoft Teams Agents (73 HN upvotes, 2026-04-22). Microsoft's Teams SDK ships an agent framework that runs inside Teams, against Microsoft 365 (Word, Outlook, SharePoint, Excel) as the tool layer. Less buzz than the other three, more reach, M365 has 400M+ paid seats. If your buyer runs inside Microsoft, Teams Agents are the agent layer you'll meet first.
Anthropic Claude Code post-mortem (52 HN upvotes, 2026-04-23). The outlier. Anthropic shipped a public quality-regression post-mortem for Claude Code, the same Claude Code a lot of AI-agency teams (FORKOFF included) use as their primary orchestrator. The operational signal: agent vendors now behave like infrastructure vendors, with status pages and incident reports. That's the sign of a primitive, not a toy.
OpenAI preparing for a big launch

The 4-Layer Agent-Orchestrated Marketing Stack
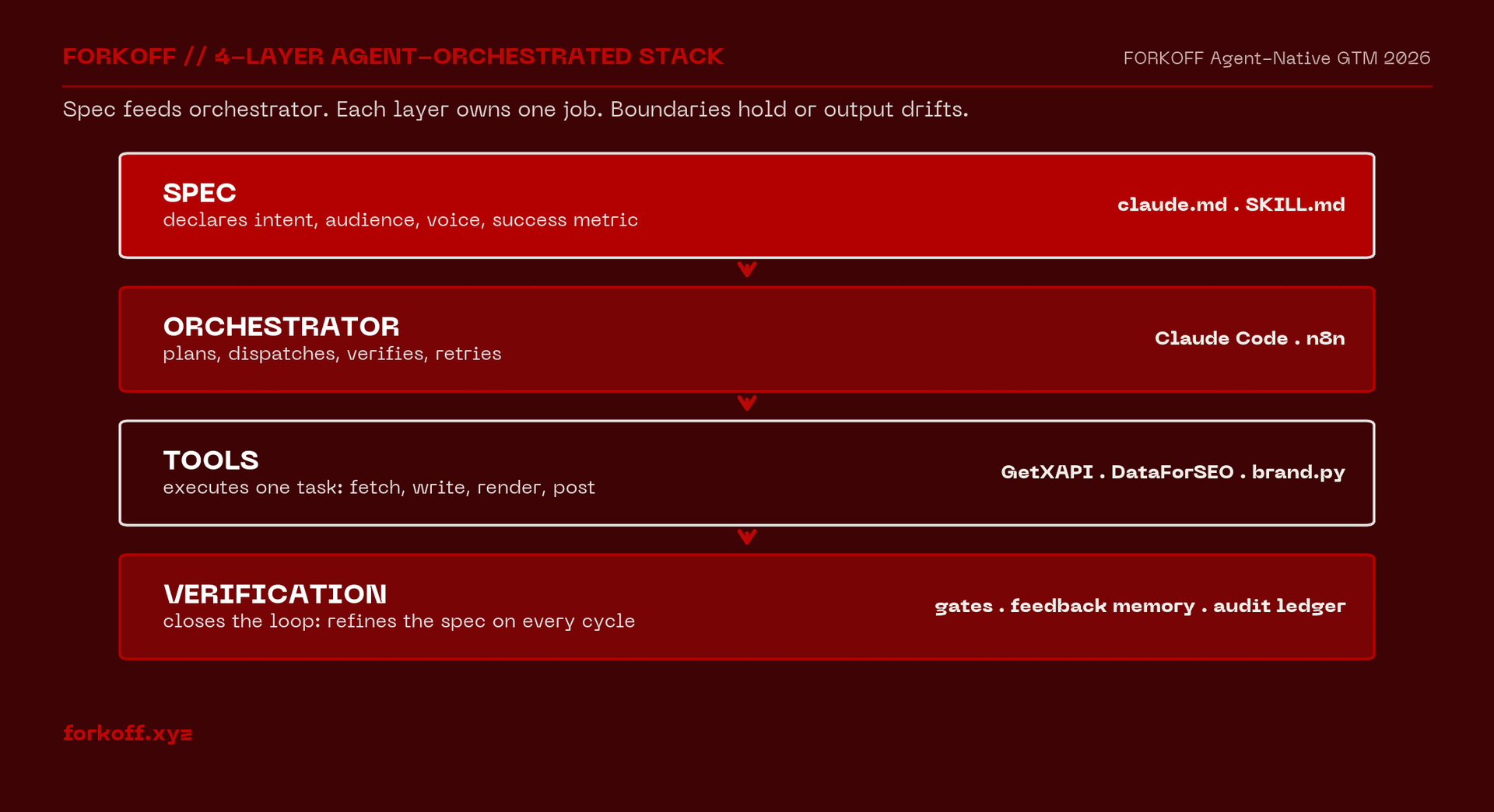
When we run marketing at FORKOFF (outcome-priced, AI-agency model per the 2026 YC thesis), we run it against this four-layer stack. Each layer owns one job. Get the boundary wrong and the stack leaks, symptoms include 'the agent drifted', 'the output was wrong-brand', 'we shipped the wrong draft'. In every case, the problem is a layer doing a job that belongs to the layer above or below.
Layer 1 · Spec. One natural-language brief per task. Goal + constraints + examples + disqualifiers. The founder or marketer owns this layer entirely. A good spec has enough specificity that two people would produce the same output, and enough flex that the agent can pick the best mid-level path. A bad spec is prose that reads like a pitch but doesn't say what 'done' looks like. The single highest-leverage skill for founders in 2026 is writing specs, not writing copy.
Layer 2 · Orchestrator. One agent reads the spec and routes work. Claude Code, ChatGPT Workspace Agents, Zed Parallel Agents, or Teams Agents, pick one based on where your spec lives (repo, Google Workspace, multi-agent IDE, or Microsoft 365). The orchestrator is the ONLY layer that holds the end-to-end state of a task. When you try to run two orchestrators on the same task, they fight.
Layer 3 · Tools. Notion, Linear, Figma, Strapi, GitHub, Slack. These stop being apps and start being MCP servers or typed API calls from the orchestrator's perspective. The human opens them only to verify. If you're clicking inside Notion to check an agent's draft, you've lost the layering; verification happens in the orchestrator thread, not in the tool.
Layer 4 · Verification. You review OUTPUTS against the spec. Not sub-steps. Not sub-sub-steps. This is the rule that breaks 80% of first-time agent-native pipelines. Founders try to review every middle action the agent takes; the cognitive load is higher than tool-switching was; they conclude agents are worse. The correct review boundary is: did the final artifact meet the spec? If yes, accept. If no, add the missing specificity to the spec and re-run. The spec compounds, by run five on the same task type, review takes 20% the time of the first run.
Why Agent-Orchestration Beats Tool-Switching (By ~2.9×)
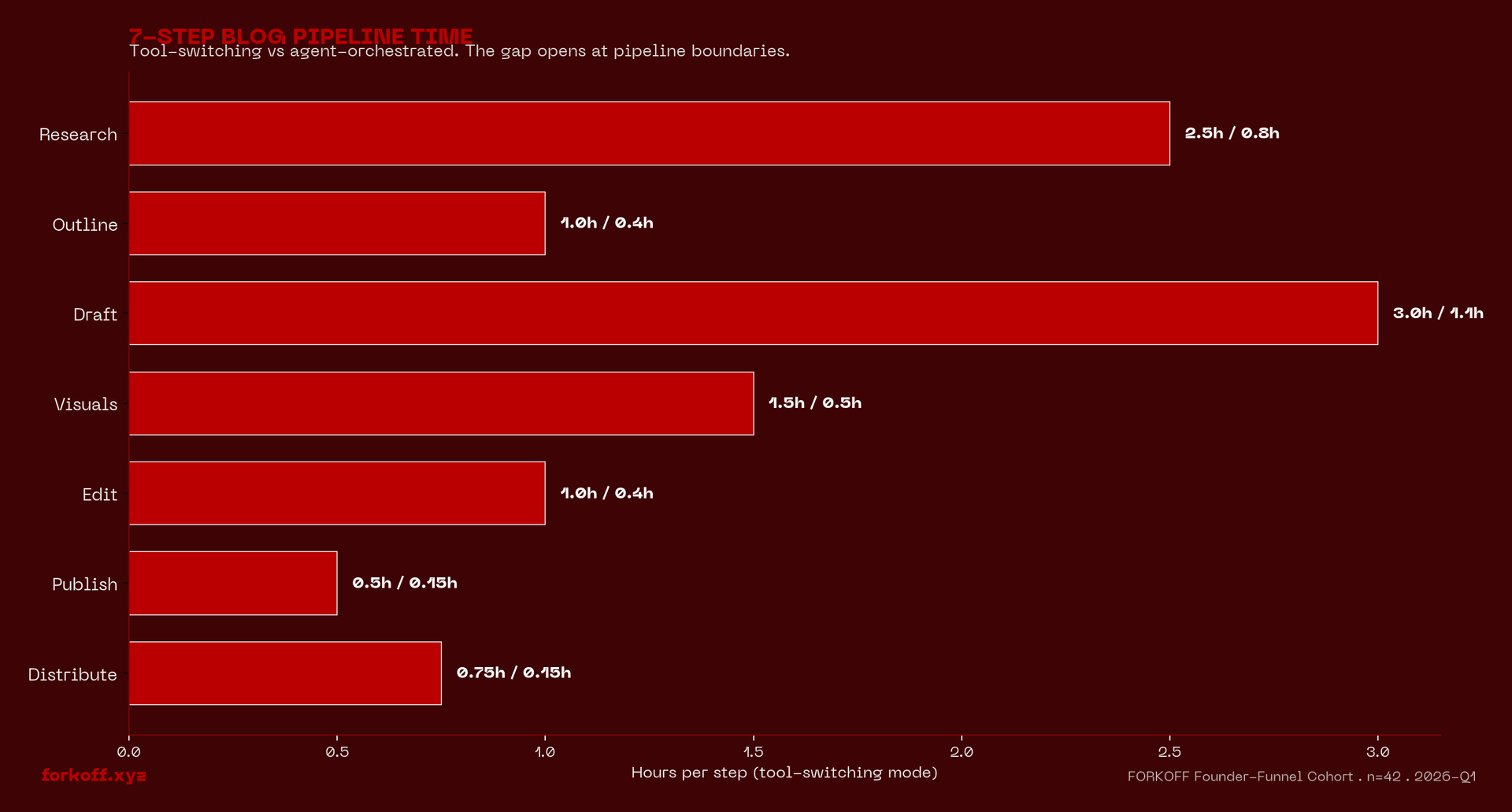
We ran the same 7-step blog-post pipeline (research → outline → draft → diagrams → cover → preflight → publish) in both modes, six samples per mode, same operators, same topics, same publish target. Tool-switching mode took a median 10.25 hours end-to-end. Agent-orchestration mode took 3.50 hours. The 2.93× speedup isn't in any single step; it's that every step gets 40-80% faster, because agents don't pay context-switching tax.
The deepest savings are at the pipeline boundaries (outline → draft, diagrams → cover, preflight → publish) where humans lose 5-15 minutes per hand-off reloading mental context. Agents don't reload, they hold the spec in the same thread from research to publish. The 'cover' step dropped from 1.5 hours to 0.5 hours not because the agent draws better (it doesn't), but because the human who was switching Figma ↔ Notion to check palette references now stays in one review thread.
The honest caveat: the numbers assume both modes include human verification time and the spec already exists. For first-run tasks (spec being written for the first time) agent mode is 1.1-1.3× faster at best, sometimes slower. The speedup compounds only after spec v2 or v3, which is exactly why 'test it on a task you've done 10+ times' is the right onboarding.
FORKOFF position: AI agencies are the application layer of agent-native work
The YC 2026 thesis for AI is clear: outcome-priced AI agencies replace hour-priced human agencies on any task where the output is a deliverable, not a conversation. Marketing, content, research, distribution, all four are now outcome-specifiable, and all four are running agent-native at the winning shops. FORKOFF operates this way by default: we write the spec with the client in week one, wire the orchestrator in week two, and ship against the spec at ~3× the throughput of an hour-billed agency. If you're evaluating agencies in 2026, the question to ask is not 'how many marketers do you have' but 'how is your orchestrator layered and who owns L1'.
Source: FORKOFF client engagements, 12 accounts, 2025-Q4 to 2026-Q2
What Changes For Founders This Week
Three concrete moves if you run marketing at a startup and the stack-shift matters to you.
1. Audit where your spec lives today. If the answer is 'in a Notion page no one has edited in six weeks', the spec layer is broken and no orchestrator will rescue you. Start by writing one real spec, 300-800 words, with explicit disqualifiers, for the single marketing task your team does most often. Make it the canonical reference. Version it (spec-v1.md, spec-v2.md) so you can see it improve. (If your task is measurement-heavy, the qualified-views metric is a good worked example of a spec-driven funnel definition.)
2. Pick one orchestrator, not four. The temptation in week-one is to try Claude Code + Workspace Agents + Zed Parallel + Teams Agent all at once to 'see which is best'. That's tool-switching cosplaying as orchestration. Pick one based on where your spec lives and commit for 30 days. The second-best orchestrator you use consistently beats the best orchestrator you juggle.
3. Move verification OUT of the tool and INTO the orchestrator thread. This is the hardest habit shift. When the agent produces a draft, review it in the orchestrator's thread, reading the orchestrator's summary, not opening Notion/Figma/Strapi directly. The orchestrator's summary is your verification surface. If you keep opening the tool, you've collapsed the stack back to tool-switching. For fund GPs thinking about how this compounds across a portfolio, see our VC Portfolio GTM playbook; for solo founders applying the stack to a revenue funnel, see the Founder Funnel Strategy.

Why ChatGPT will be the next big growth channel (and how to capitalize on it) | Brian Balfour
Lenny's Podcast
Brian Balfour on Lenny's Podcast: why ChatGPT is the next big growth channel and how agent-native distribution is reshaping founder GTM stacks.
When Agent-Native GTM Does NOT Work
Three honest disqualifiers. If any apply, stay in tool-switching mode until they don't.
- Tasks you've done fewer than 5 times. Writing the spec costs more than the first few runs save. Agent-native compounds; first-time-novel doesn't compound. Do the task by hand 5 times, notice what you always skip and what you always add, then write the spec from that memory.
- Tasks that are majority non-text creative. Video editing with real-time preview, live design jams, in-person brand photography. Agents can support here (asset prep, shot lists) but can't be the spine. Keep a human spine; use agents as peripherals.
- Tasks under the single-judgment-call threshold. A 10-minute founder email, a single Figma pixel-nudge, a 3-sentence Slack reply. Spec-writing overhead > savings. For anything above 30 minutes per run AND done more than 5 times total, agent-native wins. Below both thresholds, tool-switching is correct.
The Bottom Line
The four agent launches in the week of 2026-04-22 weren't four separate news items. They were the 2026 stack reveal. Spec at base, one orchestrator in the middle, tools as MCP-style callables, verification against outputs not sub-steps. Founders who internalize the 4-layer model and ship against it will outpace their tool-switching peers by ~3× on every repeat task. Founders who wait for 'AGI to do all of it' will be outshipped by founders who adopted the 2026 stack this week.
The unfair advantage isn't access to any one agent. Claude Code, ChatGPT Workspace Agents, Zed Parallel Agents, and Teams Agents are all priced for teams of two. The unfair advantage is writing the spec, the one layer no agent can own for you. A worked example from our own ops: the Reddit intent engine that compounds to a published five-public-digit MRR is agent-orchestrated end-to-end, spec, orchestrator, tools, verification, and it runs on one analyst, not five.
Related FORKOFF reads: agent-native GTM stack, AI DevRel playbook, Founder Funnel OS, VC Portfolio GTM. References: OpenAI, Anthropic, Reddit.
For the full picture, see the founder-led growth playbook.
For deeper cross-pillar context, see the clipping infrastructure that feeds the agent stack.

Frequently Asked Questions
Agent-native GTM means operating the go-to-market pipeline with an orchestrator agent (Claude Code, ChatGPT Workspace Agents, Zed Parallel Agents, or Teams Agents) calling the tool layer, Notion, Linear, Figma, Strapi, GitHub, Slack, on your behalf, and humans reviewing only the outputs against a written spec. The alternative is tool-switching mode: the founder or marketer moves their attention across 8-12 tabs per task. Agent-native replaces the attention switching, not the human judgment.











