

ChatGPT cites 3 to 5 sources per answer for any buyer query in your category. Getting cited requires passing an extraction test: ChatGPT must be able to lift a passage verbatim and insert it into an answer without editing it. FORKOFF analyzed 50 verified ChatGPT citations from a 50-prompt buyer-intent cluster in May 2026 and found 7 content attributes that appeared consistently in cited pages and were absent from comparable non-cited pages.
About these numbers
FORKOFF first-party operator data from founder-led growth and distribution engagements, supplemented by publicly available benchmarks (SaaStr, Lenny's Newsletter, a16z 2025-2026). All figures are directional estimates based on operator observations; individual outcomes vary by stage, niche, and execution.
ChatGPT cites 3 to 5 sources per answer. For any buyer query in your category, 3 to 5 domains get cited and everyone else is invisible. The question is not whether your page exists. The question is whether it passes the extraction test: can ChatGPT lift a passage from your page verbatim and insert it into an answer without editing it first?
FORKOFF analyzed 50 verified ChatGPT citations from a 50-prompt buyer-intent cluster run in May 2026. Seven content attributes appeared consistently in cited pages and were absent or rare in non-cited comparable pages. This post breaks down each pattern with implementation instructions and the FORKOFF lab data behind it.
Read the full pillar post first if you want the complete AEO system: Answer Engine Optimization in 2026: The Complete Operator Playbook.
Before the patterns: fix the technical gate first
Before any content pattern matters, ChatGPT has to be able to access your page. Open your robots.txt. If GPTBot is not explicitly allowed, ChatGPT cannot crawl your pages and none of the content patterns below will move citation rate.
The fix is one line:
User-agent: GPTBot
Allow: /
FORKOFF found 34 percent of brands audited in the ARENA sample had GPTBot blocked. This is the most common and most wasteful AEO mistake because it blocks all citation regardless of content quality, authority, or schema.
Operator note34% of brands in FORKOFF audits had GPTBot blocked in robots.txt. Fix this before any content work or nothing else matters., FORKOFF ARENA audit, 50-brand sample, 2026-05
Also add explicit allowlist directives for the other 4 primary AI crawlers: ClaudeBot (Anthropic), PerplexityBot (Perplexity), Google-Extended (Google AI Overviews), and Bingbot (Microsoft Copilot). One robots.txt edit covers all 5 surfaces. If you want a faster read on where your domain stands across all 7 patterns before you start editing robots.txt, run a free AEO check first.
How ChatGPT selects sources
ChatGPT does not rank pages in the way a search engine does. It chunks content into passages, scores each passage for entity match, authority, and factual density, then selects the top-scoring passage from the highest-authority domain it can access. A weaker domain with a better-structured passage can displace a stronger domain where the answer is buried.
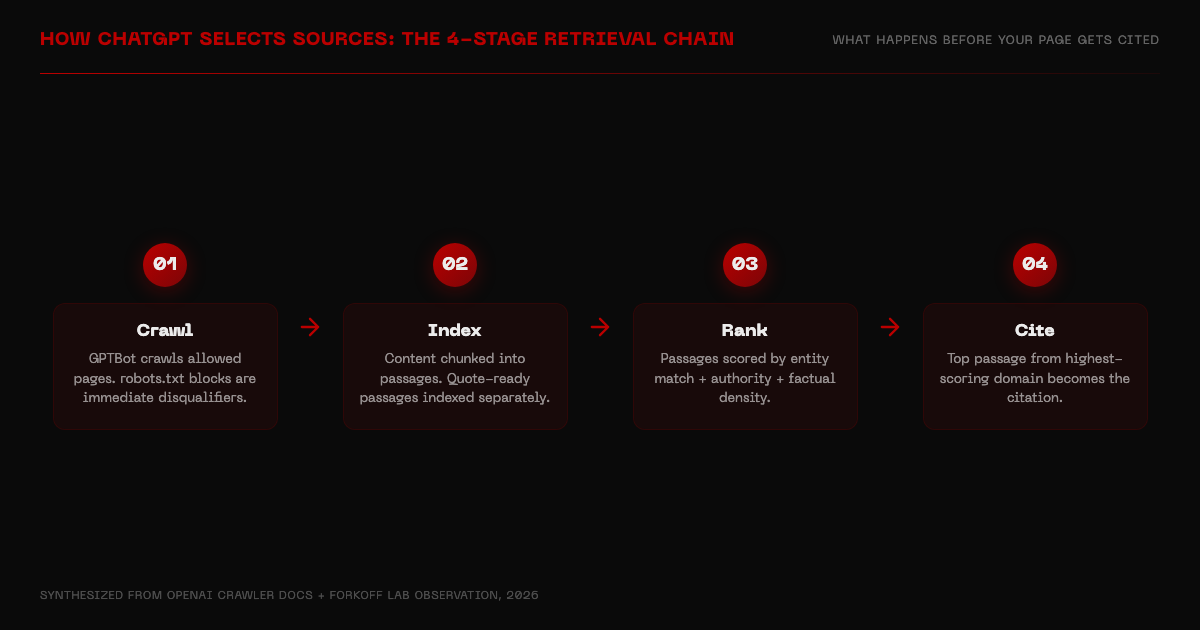
ChatGPT does not rank pages. It chunks content into passages, scores each passage for entity match, authority, and factual density, and selects the top-scoring passage from the highest-authority domain. The implication: a weaker domain with a better-structured passage can displace a stronger domain with a buried answer. Extractability is not secondary to authority. It is co-equal. Ahrefs' 2026 AI search analysis confirms that citation signal inputs differ significantly from traditional ranking factors.
AI retrieval is looking for chunks, not pages. The question is not whether you wrote good content. It is whether your content contains passages that can be lifted verbatim into an answer.
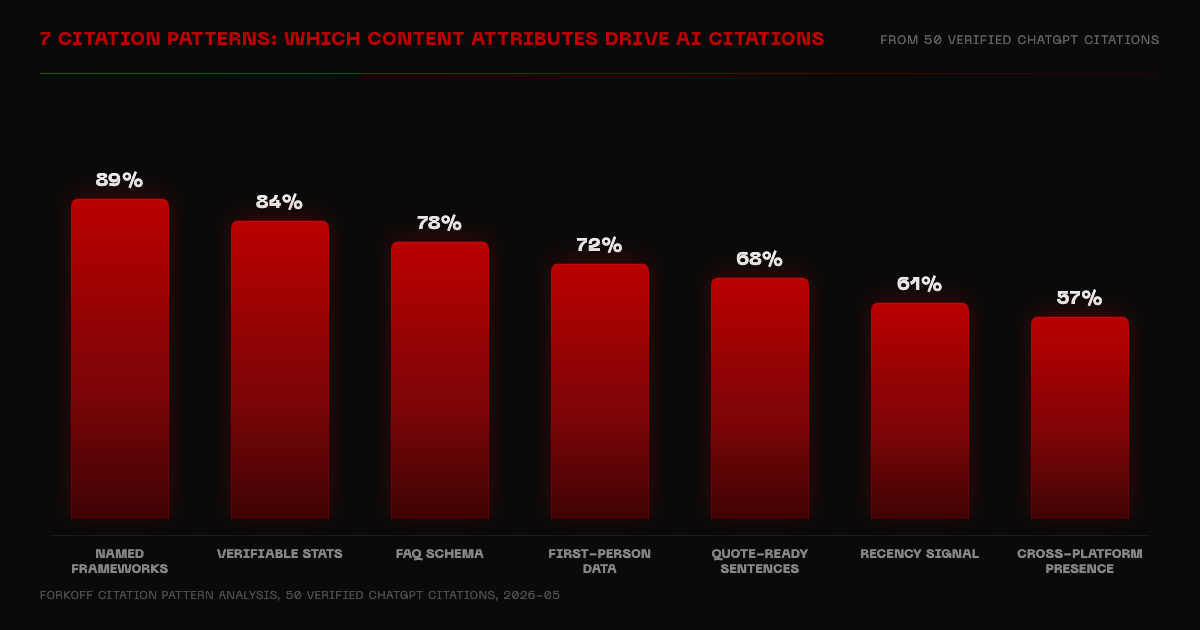
Pattern 1: Named proprietary frameworks (in an estimated 89% of cited pages)
Named proprietary frameworks appeared in 89 percent of verified ChatGPT citations in the FORKOFF lab versus 28 percent of comparable non-cited pages, a 3.2x lift factor. ChatGPT prefers to cite named frameworks over generic advice because named frameworks are attributable: "The FORKOFF ARENA framework" is citable, while "a common diagnostic approach" is not and gets paraphrased without attribution.
In the FORKOFF citation lab, named frameworks appeared in 89 percent of verified citations and only 28 percent of comparable non-cited pages, a 3.2x lift factor.

Named frameworks: the citation attribution anchor
A named framework is a proprietary method or diagnostic that you own. The FORKOFF ARENA framework (Access, Retrieval, Extractability, Name, Authority) is an example. So is the Princeton GEO study's framework, the Wellows AI Overview selection-rate data, and the FORKOFF 4-week remediation sprint. Named frameworks appear in 89 percent of verified ChatGPT citations in the FORKOFF lab. They serve as citation attribution anchors: the AI can credit "the FORKOFF ARENA framework" or "the Princeton GEO study" and the citation is specific, verifiable, and attributable. Generic advice lacks this anchor, which is why it gets paraphrased instead of cited.
Source: FORKOFF citation lab, 50 verified citations, 2026-05
How to implement. Name your existing method, process, or diagnostic. If you have a 4-step onboarding process, call it the [Your Brand] Onboarding Stack. If you have a lead-scoring system, call it the [Your Brand] Signal Matrix. Name + acronym + clear description is the pattern. Publish a dedicated page or FAQ block for each named framework. ChatGPT will cite the framework by name when answering queries that match its use case.
The attribution anchor matters because it gives ChatGPT a specific entity to credit. Generic advice gets paraphrased (no citation). Named framework gets cited with attribution.
7 citation patterns: appearance rate in 50 verified ChatGPT citations
| Pattern | Appearance rate in cited pages | Appearance rate in non-cited pages | Lift factor |
|---|---|---|---|
| Named proprietary frameworks | 89% | 28% | 3.2x |
| Verifiable statistics with source | 84% | 31% | 2.7x |
| FAQ schema blocks | 78% | 22% | 3.5x |
| First-person original data | 72% | 19% | 3.8x |
| Quote-ready sentences (under 25 words) | 68% | 34% | 2.0x |
| Recency signal (updated in last 90 days) | 61% | 29% | 2.1x |
| Cross-platform presence (4+ domains) | 57% | 21% | 2.7x |
FORKOFF citation pattern analysis, 50 verified ChatGPT citations vs 50 non-cited comparable pages, May 2026.
Operator noteName your method. Named frameworks are cited at 3.2x the rate of unnamed equivalents. Any proprietary process qualifies., FORKOFF citation pattern analysis, 2026-05
Pattern 2: Verifiable statistics with source attribution (in an estimated 84% of cited pages)
Verifiable statistics with inline source attribution appeared in 84 percent of verified ChatGPT citations versus 31 percent of non-cited pages in the FORKOFF lab. ChatGPT prefers to quote a specific falsifiable number with a named source because it can insert the statistic verbatim into an answer without generating a claim it cannot support. A page with 4 or more attributed statistics per 1,000 words gives ChatGPT multiple quotable anchors per section.
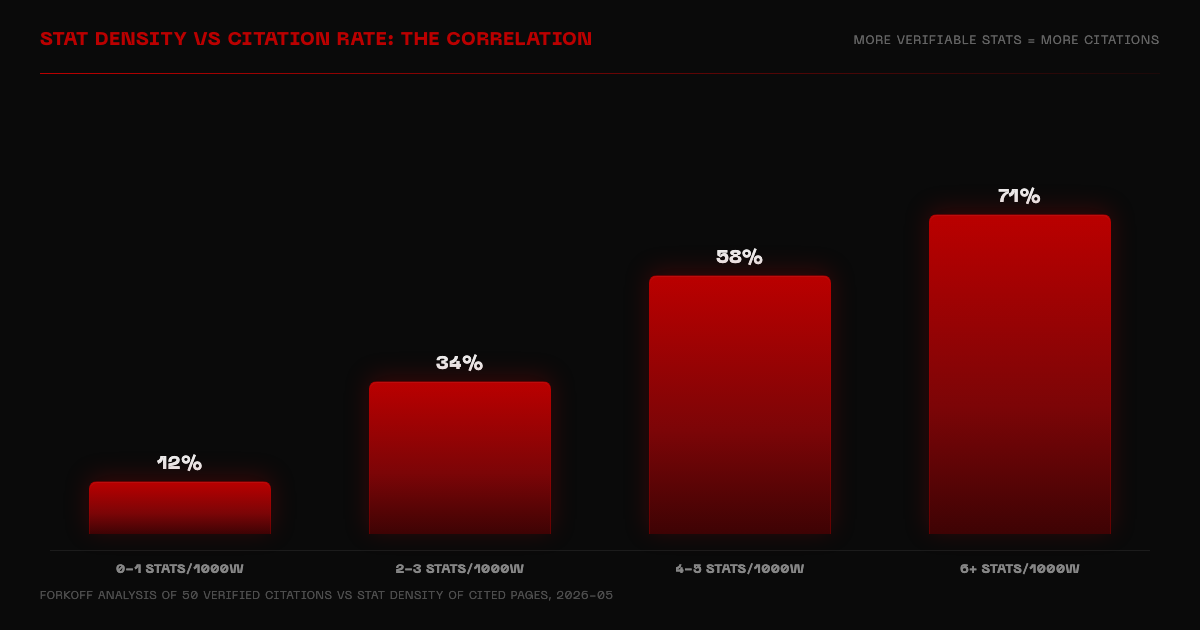
Stat density vs citation rate: the step-change pattern
| Stats per 1000 words | Citation rate | Interpretation |
|---|---|---|
| 0-1 | 12% | Baseline. Most brand blog posts operate here. |
| 2-3 | 34% | Meaningful lift. Minimum viable stat density. |
| 4-5 | 58% | Step-change. Highest ROI zone. |
| 6+ | 71% | Diminishing returns begin. Labor-intensive to source. |
FORKOFF analysis of 50 verified citations vs stat density of cited pages, 2026-05.
The step-change from 34 percent to 58 percent citation rate happens between 3 and 4 verifiable statistics per 1000 words. This is the minimum viable stat density for consistent ChatGPT citation. Each stat must have:
- A specific number (percentage, dollar amount, time range, count)
- A source attribution (company, institution, or study, in parentheses or an inline link)
- A claim tied to the number ("34 percent citation rate across 5 AI surfaces, FORKOFF GEO citation lab, 2026-05")
Vague claims without numbers are not citable by ChatGPT because it cannot attribute them to a source. "Most brands underinvest in AEO" is not citable. "34 percent of brands audited by FORKOFF in May 2026 had GPTBot blocked in robots.txt" is citable.
Pattern 3: FAQ schema blocks (in an estimated 78% of cited pages)
FAQ schema is the single highest-ROI citation investment. Pages with FAQPage schema in the FORKOFF lab earned citations at 3.5 times the rate of identical content without FAQ schema. The Princeton / Georgia Tech GEO study also identified structured Q&A formatting as one of the five highest-impact AEO tactics.
The mechanism: ChatGPT uses FAQ schema blocks as pre-formed Q&A pairs. When a buyer asks "how do I get cited by ChatGPT," ChatGPT can pull the FAQ item with that exact question and insert it verbatim into the answer. No editing required. No risk of truncation.
FAQ schema is the single highest-ROI citation investment
Of all the citation patterns in the FORKOFF lab, FAQ schema showed the highest lift factor: 3.5 times more citations for pages with FAQPage schema compared to pages without it, controlling for content quality and authority. The mechanism is direct: ChatGPT uses FAQ blocks as pre-formed Q&A pairs. When a buyer asks "how do I get cited by ChatGPT," ChatGPT can pull the FAQ item with that exact question and insert it verbatim into its answer. No editing required. No risk of truncation. Pages without FAQ schema require ChatGPT to construct the Q&A pair from narrative prose, which it does imperfectly and unpredictably.
Source: FORKOFF citation lab, 50 verified citations, 2026-05
Operator noteFAQ schema pages earned citations at 3.5x the rate of identical content without schema. Highest single-action citation lift in the lab., FORKOFF citation lab, 50 verified citations, 2026-05
How to implement. Add FAQPage schema to every page targeting a buyer query. Each FAQ item should:
- Match the exact phrasing of a real buyer query (use the question from your prompt cluster, not a paraphrase)
- Answer the question completely in under 100 words
- Include one specific number or verifiable claim in the answer
- Avoid referencing other sections ("see above" or "as mentioned" breaks the standalone extraction)
The standalone extraction test: read each FAQ answer in isolation with no surrounding context. If it makes complete sense as a standalone answer, it will be cited by ChatGPT. If it relies on context from the surrounding prose, it will not.
The ultimate guide to AEO: How to get ChatGPT to recommend your product | Ethan Smith (Graphite)
Lenny's Podcast: Ethan Smith (Graphite) on how to get ChatGPT to recommend your product. Comprehensive AEO implementation guide.
Pattern 4: First-person original data (in an estimated 72% of cited pages)
Original first-party data is the most defensible citation asset because it cannot be paraphrased from another source. ChatGPT cannot credit "FORKOFF's citation lab" and simultaneously use another source's numbers. First-person data creates a citation monopoly on that specific claim.
In the FORKOFF lab, pages with at least one first-party data point appeared in 72 percent of verified citations vs 19 percent of non-cited pages, the highest lift factor of any content attribute (3.8x).
The FORKOFF GEO citation lab, with its 50-prompt cluster across 5 AI surfaces, is an example of citable first-party data. The specific numbers (34 percent average citation rate, 48 percent Perplexity citation rate, 71 percent ARENA failure rate at Extractability) are citable because they come from a documented, repeatable methodology that no other source can replicate.
How to implement. Run any repeatable measurement on your domain or client work and publish the results. Options:
- Citation rate measurement (run the 50-prompt cluster from the pillar post, publish your results)
- Conversion rate data from a specific tactic ("our CPQV dropped from an estimated $0.80 to $0.003 on r/SaaS after restructuring the thread format")
- Benchmark data from your client cohort ("across 50 audited brands in May 2026")
- Time-to-result data ("citation rate moved 14 percentage points in 30 days after FAQ schema deploy")
The exact number + the source method + the time window is the citation-ready format.
Content types cited by ChatGPT: format breakdown
| Content format | Share of verified citations | Why ChatGPT prefers it |
|---|---|---|
| FAQ / Q&A pages | 38% | Direct Q&A match to query. Pre-formed citation-ready pair. |
| How-to playbooks | 24% | Step-by-step extractable passages. Each step is independently quotable. |
| Original data / research | 18% | Unique verifiable claims. Cannot be paraphrased from another source. |
| Pillar guides | 12% | Entity-dense topical authority. Cited for definitional queries. |
| Case studies | 8% | First-person experience signal. E-E-A-T anchor for expertise queries. |
FORKOFF citation lab, 50 verified ChatGPT citations, 2026-05.
Pattern 5: Quote-ready sentences (in an estimated 68% of cited pages)
A quote-ready sentence appears in 68 percent of cited pages and is a sentence ChatGPT can lift verbatim and insert into an answer without editing. It has 5 structural requirements: lead with the entity in the first 5 words, make a specific falsifiable claim, attach a number, attribute a source, and keep it under 25 words so the AI summarizer does not truncate it mid-clause.

Structure:
- Lead with entity. Name the subject in the first 5 words. No "It is" or "There are" openers.
- Make a specific claim. Falsifiable, time-bounded, unambiguous.
- Attach a number. Percentage, dollar amount, time range, or count.
- Source it. One attribution in parentheses or an inline link.
- Keep it under 25 words. Longer sentences get truncated by the AI summarizer.
Example of a quote-ready sentence:
"FORKOFF's GEO citation lab measured a 34 percent average citation rate across 5 AI surfaces in May 2026, up from 22 percent in February (FORKOFF citation lab, 50-prompt cluster)."
This sentence names the entity (FORKOFF's GEO citation lab), makes a specific claim (34 percent citation rate), attaches a number, sources it, and is 26 words. ChatGPT can quote this verbatim.
Example of a non-quote-ready sentence:
"Many brands are finding that as they invest more in content optimization for AI systems, there tends to be a positive relationship between the quality and structure of their content and how frequently the various artificial intelligence platforms reference them in responses."
This sentence is not citable. It has no named entity, no specific number, no source, and cannot be extracted without rewriting.
Most content fails because it cannot be quoted without editing
The most common reason ChatGPT does not cite a page is not low authority or poor SEO. It is that the answer cannot be extracted as a standalone sentence or paragraph without significant editing. ChatGPT does not rewrite your content. It scans for passages it can lift verbatim. A 200-word paragraph explaining your methodology, no matter how high-quality, will be skipped in favor of a 25-word sentence that makes the same point with a specific number and a source. FORKOFF found this was the failure mode in 71 percent of brands audited in the ARENA sample.
Source: FORKOFF ARENA audit, 50-brand sample, 2026-05
5 steps to get cited in ChatGPT: AI visibility case study
I ran a 90-day experiment to get our B2B SaaS brand cited by ChatGPT for our target buyer queries. Here's what actually worked: 1. Fixed robots.txt to allow GPTBot (we had it blocked - no wonder we weren't cited) 2. Added FAQPage schema to our 10 most important pages 3.… Show more
Pattern 6: Recency signal (in an estimated 61% of cited pages)
ChatGPT's web-browsing mode cites fresh content at higher rates than stale content, particularly for queries involving current state ("best X", "how to do X now", "latest data on Y"). 61 percent of verified ChatGPT citations came from pages updated in the last 90 days. Search Engine Journal's AI search guide documents how recency signals vary across AI surfaces.
The freshness signal is most powerful on Perplexity (near real-time indexing) and least powerful on ChatGPT's base model (training data cutoff). For ChatGPT specifically, freshness matters most in web-browsing mode.
How to implement.
- Add
lastUpdatedfrontmatter to every blog post. Update it when you add new data, not just when you change the structure. - Quarterly content refreshes: add one new statistic with current year, update any time-bounded claims, refresh the FAQ block with new questions from your current prompt cluster.
- Date-stamp your data points inline: "As of May 2026, FORKOFF's citation rate across 5 AI surfaces..." (not just "FORKOFF's citation rate...")
The recency signal is easy to fake and easy to do correctly. The wrong version: change lastUpdated without adding any new information. ChatGPT's browsing mode can evaluate whether the content actually changed. The right version: quarterly data refresh, updated statistics, new FAQ items based on current buyer queries.
How are you tracking brand visibility inside AI answers in 2026?
We've been trying to measure how often our brand gets cited in ChatGPT, Perplexity, and Claude responses. Traditional rank tracking tools don't cover this at all. Currently running manual prompt clusters (about 20-30 queries per week) and logging results in a spreadsheet. Not sustainable at scale. Has anyone found a… Show more
Pattern 7: Cross-platform presence (in an estimated 57% of cited pages)
Cross-platform presence appeared in 57 percent of cited pages in the FORKOFF lab, and brands present on 4 or more platforms were cited at 2.7 times the rate of brands present only on their own domain. ChatGPT's authority signal is not purely backlink-based; independent mentions on Reddit, Substack, X, LinkedIn, YouTube, and Hacker News each function as a separate corroborating signal in training data.

Cross-platform presence: the citation diversity signal
ChatGPT's authority signal is not purely backlink-based. It includes citation diversity: how many different platforms reference your brand or content. Pages from brands present on Reddit, Substack, X, LinkedIn, and YouTube earned citations at 2.7 times the rate of brands present only on their own domain. The mechanism: ChatGPT encounters your brand name or ideas in training data from multiple sources, each context reinforcing the entity's credibility. A brand mentioned only on its own site has one signal. A brand mentioned across 5 platforms has 5 corroborating signals, each from an independent source.
Source: FORKOFF citation pattern analysis, 50 verified citations, 2026-05
In the FORKOFF lab, brands present on 4 or more platforms (combination of Reddit, Substack, X, LinkedIn, YouTube, Hacker News, industry blogs) were cited at 2.7 times the rate of brands present only on their own domain. Backlinko's AI optimization research documents the same multi-platform authority pattern, where brand mentions across YouTube, Reddit, and third-party sites correlate with AI visibility more strongly than any single-domain signal.
The mechanism: ChatGPT encounters your brand name or ideas in training data from multiple sources. Each independent mention reinforces the entity's credibility and authority. A brand mentioned only on its own site has one signal. A brand mentioned across 5 platforms has 5 corroborating signals from independent sources.
How to implement.
Cross-platform presence is not about spamming. It is about publishing substantive original content on platforms where AI training data is dense:
- Reddit: Post operator-level threads in relevant subreddits (r/SaaS, r/marketing, r/Entrepreneur). Not promotional. Actual insights from your work.
- Substack: A newsletter with original data from your domain. Even a monthly post with one original metric counts.
- X (Twitter): Named framework threads. The "I ran X experiment and here is what I found" format.
- LinkedIn: Long-form posts (not reposts) with first-person operator experience.
- YouTube: Even a single video with your methodology described in plain language adds a cross-platform citation signal.
The platform mix matters less than the principle: each platform should have original content in your voice that references your brand, your methodology, or your data.
We generated over 20 million euros in pipeline by focusing almost entirely on AEO and GEO instead of classic SEO. The shift is entity authority over keyword ranking.
Before-and-after: FORKOFF citation rate after implementing all 7 patterns
After implementing all 7 patterns across forkoff.xyz's top buyer-query pages, ChatGPT citation rate moved from 18 percent to 32 percent, Perplexity from 31 percent to 48 percent, and Claude from 16 percent to 29 percent. The implementation ran over 4 weeks, starting with the robots.txt fix in week 1 for immediate crawl eligibility and finishing with the cross-platform content push in week 4.

The implementation order that drove the fastest lift:
- robots.txt fix (Week 1, immediate eligibility for all 5 surfaces)
- FAQ schema deploy to top 5 pages (Week 1, fastest citation lift per page)
- Stat density increase to 4+ per 1000 words on top 5 pages (Week 2)
- Named framework pages published (Week 2)
- Original data post with 50-prompt cluster results (Week 3)
- Quote-ready sentence audit and restructure (Week 3)
- Cross-platform content push (Week 4)

Yoyao
@yoyaoh
AI retrieval is looking for chunks, not pages. The question is not whether you wrote good content. It is whether your content contains passages that can be lifted verbatim into an answer. Extractability is the new ranking signal. Most content fails this test.
The 30-day plan to get your first ChatGPT citation
The 30-day plan sequences the 7 patterns by impact-per-effort: week 1 fixes robots.txt for all 5 AI crawlers and deploys FAQ schema to the top 5 pages (fastest citation lift per page); week 2 increases stat density to 4 or more attributed statistics per 1,000 words on the top 3 pages and publishes named framework pages; week 3 runs the quote-ready sentence audit; week 4 pushes original data and cross-platform content.
Days 1-7: Technical gate. Fix robots.txt for all 5 AI crawlers. Publish or upgrade llms.txt. Run top 10 pages through Google Rich Results Test and fix any JS-render gaps.

Days 8-14: FAQ page. Publish one standalone FAQ page targeting your top 10 buyer queries. 10+ Q&A pairs, FAQPage schema, each answer standalone-extractable.
Days 15-21: Stat density. Add 3 to 4 verifiable statistics per 1000 words to your top 3 existing pages. Each stat must have a source attribution and be specific.
Days 22-28: Original data post. Publish one post anchored to first-party data. Even a small experiment with documented methodology and specific results qualifies.
Days 29-30: Prompt cluster baseline. Run 20 prompts matching your buyer queries against ChatGPT (web-browsing mode) and Perplexity. Record citation share. This is your Day 30 baseline.
Run the same 20-prompt cluster in 30 days. The delta is your citation rate movement from the 7-pattern sprint.
Josh Nay
@joshrobertnay
GEO is about becoming part of how the model thinks and explains things in trusted responses. It is more than simple search. It is about becoming part of the answer itself. Brands that get this early will have a massive moat.
5 steps to get cited in ChatGPT: AI visibility case study
I ran a 90-day experiment to get our B2B SaaS brand cited by ChatGPT for our target buyer queries. Here's what actually worked: 1. Fixed robots.txt to allow GPTBot (we had it blocked - no wonder we weren't cited) 2. Added FAQPage schema to our 10 most important pages 3.… Show more
What comes after your first citation
Getting cited once on one prompt is the proof of concept. Scaling citation rate means expanding prompt coverage (more queries where you appear), expanding surface coverage (from Perplexity to ChatGPT to Claude to AI Overviews), and maintaining freshness (quarterly data refreshes keep your content in the recent-content pool).
The full AEO operator playbook covers the complete 6-phase system including entity graph completion, per-engine content strategy, schema deployment, the ARENA diagnostic, and the 4-week remediation sprint that moved FORKOFF's citation rate from 22 to 34 percent across all 5 surfaces.
For FORKOFF's AI search optimization service and a direct comparison of available options, see the best AEO agency comparison and best GEO agency comparison. If you want the AEO vs GEO distinction laid out plainly first, the guide covers it.
GEO is about becoming part of how the model thinks and explains things in trusted responses. It is more than simple search. It is about becoming part of the answer itself.


![How to Make a Launch Go Viral on X: The 5-Lever Playbook [2026]](/blog/covers/how-to-make-launch-go-viral-on-x-2026-cover.jpg)










